监控Scala与Python Spark作业在Yarn中的动态资源使用
需积分: 9 110 浏览量
更新于2024-07-17
收藏 1.27MB PDF 举报
" Monitoring the Dynamic Resource Usage of Scala and Python Spark Jobs in Yarn "
在2017年的SPARK SUMMIT大会上,来自Sqrrl Data的Ed Barnes、Ruslan Vaulin和Chris McCubbin共同探讨了如何在YARN环境下监控Scala和Python Spark作业的动态资源使用情况。这篇报告深入剖析了机器学习(ML)应用的工作流程,以及如何将Spark技术有效地应用于实际产品中。
在云计算领域,Apache Spark因其高效的数据处理能力而备受青睐,特别是在大数据分析和机器学习任务中。YARN(Yet Another Resource Negotiator)作为Hadoop的资源管理器,为Spark提供了执行框架,确保其在分布式环境中的可扩展性、稳定性和测试性。然而,随着应用规模的扩大,性能、内存需求、故障和扩展性等问题也会逐渐显现,对分布式应用程序的调试变得尤为困难。
Spark UI是Spark自带的一种监控工具,可以提供作业级和任务级的监控视图,帮助开发者了解任务执行情况。但在遇到如Out-of-Memory (OOM)等严重问题时,Spark UI的诊断能力有限,不能提供足够的信息来定位问题根源。例如,当测试工程师反馈代码在处理大量数据时引发OOM异常,开发者在Spark UI中可能找不到明显的线索。
针对这种情况,报告提出了一种YARN工具化方法的要求,以解决集群级的进程监控问题。该方法应能提供每个节点和每个进程的统计信息,识别高CPU和内存使用情况,并记录Spark作业的进程层次结构和时间线。这样的工具可以帮助开发者更有效地追踪和诊断性能瓶颈,优化资源分配,提高Spark作业的效率和稳定性。
在使用Scala和Python开发Spark应用时,需要特别关注资源管理和性能优化。例如,对于Python应用,由于Py4J接口的存在,可能会引入额外的性能开销和内存使用。在上述案例中,Py4J问题导致的OOM异常,由于在Spark UI中没有明显的提示,需要通过更深入的工具和方法来定位和解决。
监控Spark作业在YARN上的动态资源使用是一项关键任务,它涉及到从ML工作流的设计、测试到生产环境的部署全过程。有效的监控和调试策略能够帮助开发者及时发现并解决问题,从而确保Spark应用在大规模数据处理中的高效运行。
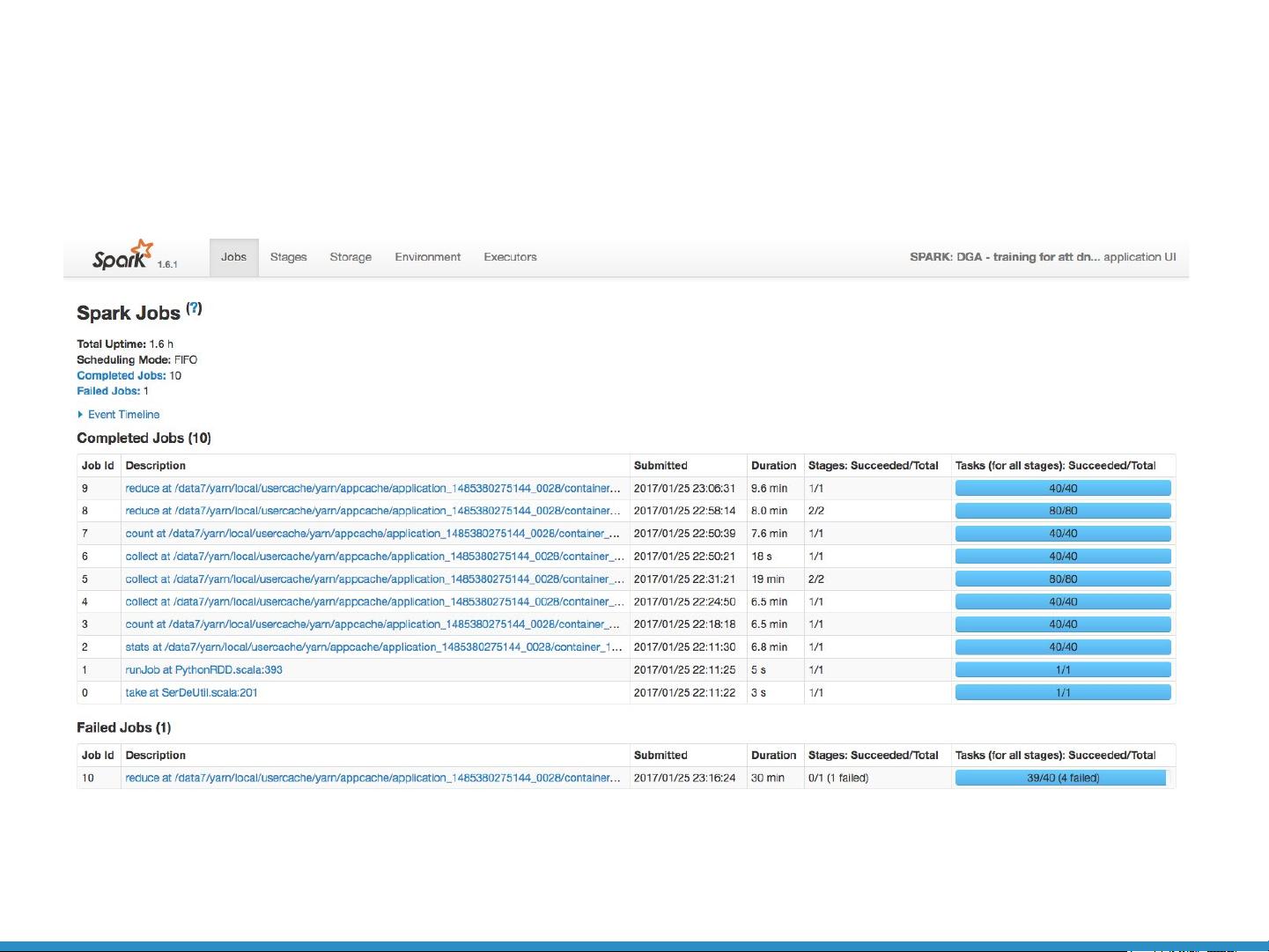
Spark UI: job level
剩余24页未读,继续阅读
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传

weixin_38743481
- 粉丝: 698
- 资源: 4万+
 我的内容管理
展开
我的内容管理
展开







