Python爬取w3school jQuery教程并离线保存
44 浏览量
更新于2024-08-29
收藏 112KB PDF 举报
在这个Python爬虫项目中,目标是抓取W3School网站上的jQuery教程内容,并将其保存到本地,以满足那些在网络受限或没有电子书的情况下想学习jQuery语法的需求。作者是一名正在寻找工作的开发者,利用业余时间通过实践提升技能,认为多做项目有助于成长。
首先,需求明确,即抓取"http://www.w3school.com.cn/jquery/jquery_syntax.asp"中的jQuery语法部分,以及"http://www.w3school.com.cn/jquery/jquery_intro.asp"的简介内容。由于网站结构相似,发现根URL"http://www.w3school.com.cn/jquery/"是重复的,这提示可能采用分页或者有统一的目录结构。
在进行爬虫实现时,作者使用了Python的urllib和BeautifulSoup库。`head()`函数设置了一个User-Agent请求头,模拟浏览器行为,以避免被服务器识别为机器人。`parse_url(url)`函数负责发送HTTP请求、读取响应并返回HTML内容。`url_s()`函数则作为主入口,初始化URL并调用`parse_url()`函数处理。
通过BeautifulSoup解析HTML,作者观察到右侧栏存在链接,推测这些链接可能是导航或章节链接,可以通过拼接URL获取完整的课程页面。在实际操作中,会遍历这些链接,构建一个URL列表,然后逐个抓取内容。这可能涉及到递归或循环,以便处理多级菜单和子章节。
此外,为了节省带宽和避免过于频繁的访问,可能还会加入一些延时(`time.sleep()`)和错误处理机制。爬虫完成后,抓取的数据可以存储为文本文件、CSV或其他便于后续查阅和分析的格式,如Markdown或JSON。
这个项目不仅锻炼了Python编程和爬虫技术,还涉及到了HTML解析、网页结构分析、网络请求处理等关键知识点。对于新手来说,这是一个很好的实战机会,能够加深对Web开发和数据抓取的理解。同时,通过学习如何处理动态加载内容或使用Selenium等工具来应对反爬虫策略,可以进一步提高技能水平。
python爬取爬取w3shcool的的JQuery课程并且保存到本地课程并且保存到本地
最近在忙于找工作,闲暇之余,也找点爬虫项目练练手,写写代码,知道自己是个菜鸟,但是要多加练习,书山有路勤为径。各位
爷有测试坑可以给我介绍个啊,自动化,功能,接口都可以做。
首先呢,我们明确需求,很多同学呢,有事没事就想看看一些技术,比如我想看看JQuery的语法呢,可是我现在没有网络,手机上
也没有电子书,真的让我们很难受,那么别着急啊,你这需求我在这里满足你,首先呢,你的需求是获取JQuery的语法的,那么我
在看到这个需求,我有响应的网站那么我们接下来去分析这个网站。http://www.w3school.com.cn/jquery/jquery_syntax.asp 这是语
法url, http://www.w3school.com.cn/jquery/jquery_intro.asp 这是简介的url,那么我们拿到很多的url分析到,我们的
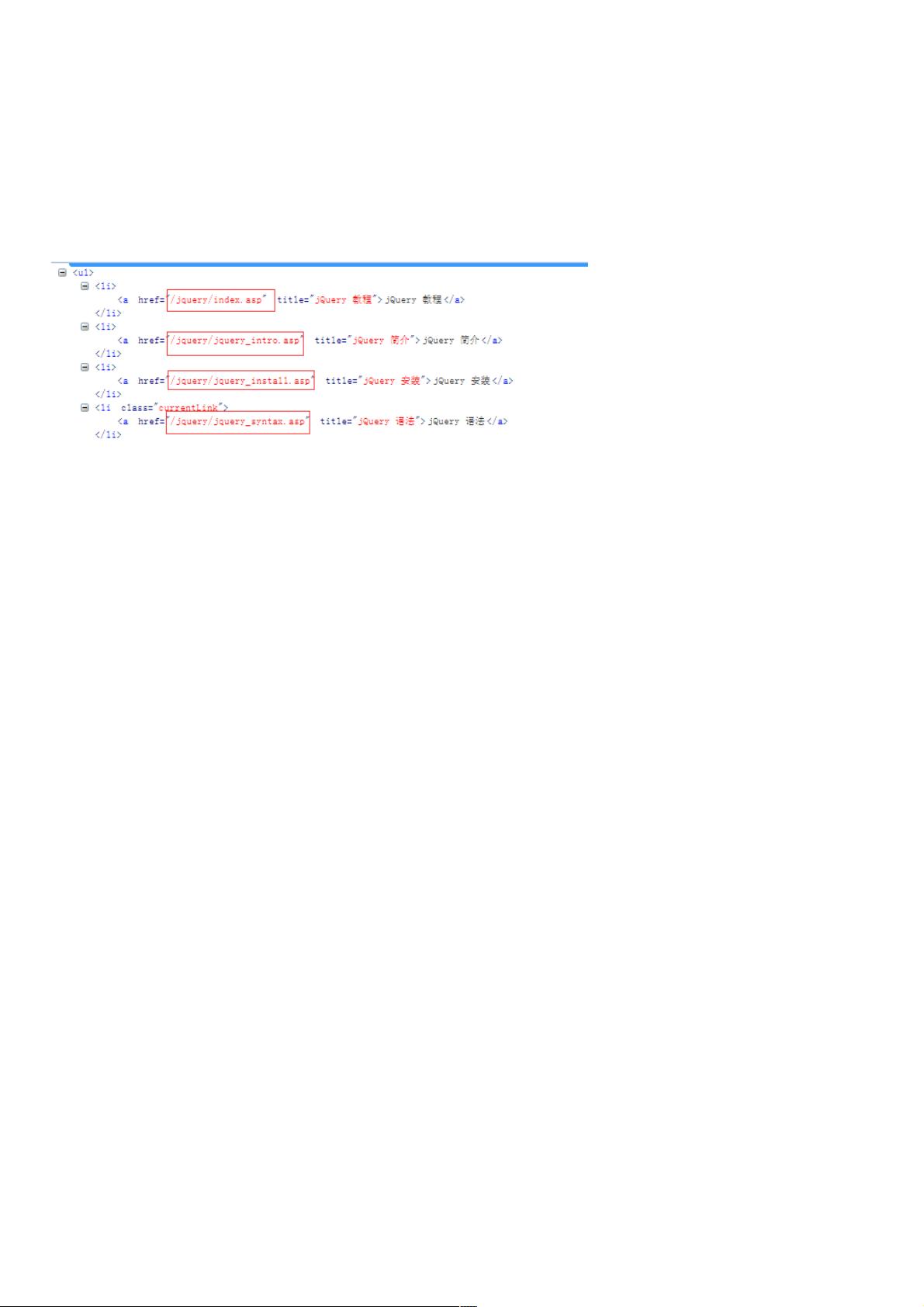
http://www.w3school.com.cn/jquery是相同的,那么我们在来分析在界面怎么可以获取得到这些,我们可以看到右面有相应的目标
栏,那么我们去分析下
我们来看下这些链接,。我们可以吧这些链接和http://www.w3school.com.cn拼接到一起。然后组成我们新的url,
上代码
import urllib.request
from bs4 import BeautifulSoup
import time
def head():
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
}
return headers
def parse_url(url):
hea=head()
resposne=urllib.request.Request(url,headers=hea)
html=urllib.request.urlopen(resposne).read().decode('gb2312')
return html
def url_s():
url='http://www.w3school.com.cn/jquery/index.asp'
html=parse_url(url)
soup=BeautifulSoup(html)
me=soup.find_all(id='course')
m_url_text=[] m_url=[] for link in me:
m_url_text.append(link.text)
m=link.find_all('a')
for i in m:
m_url.append(i.get('href'))
for i in m_url_text:
h=i.encode('utf-8').decode('utf-8')
m_url_text=h.split('')
return m_url,m_url_text
这样我们使用url_s这个函数就可以获取我们所有的链接。
['/jquery/index.asp', '/jquery/jquery_intro.asp', '/jquery/jquery_install.asp', '/jquery/jquery_syntax.asp', '/jquery/jquery_selectors.asp', '/jquery/jquery_events.asp',
'/jquery/jquery_hide_show.asp', '/jquery/jquery_fade.asp', '/jquery/jquery_slide.asp', '/jquery/jquery_animate.asp', '/jquery/jquery_stop.asp',
'/jquery/jquery_callback.asp', '/jquery/jquery_chaining.asp', '/jquery/jquery_dom_get.asp', '/jquery/jquery_dom_set.asp', '/jquery/jquery_dom_add.asp',
'/jquery/jquery_dom_remove.asp', '/jquery/jquery_css_classes.asp', '/jquery/jquery_css.asp', '/jquery/jquery_dimensions.asp', '/jquery/jquery_traversing.asp',
'/jquery/jquery_traversing_ancestors.asp', '/jquery/jquery_traversing_descendants.asp', '/jquery/jquery_traversing_siblings.asp',
'/jquery/jquery_traversing_filtering.asp', '/jquery/jquery_ajax_intro.asp', '/jquery/jquery_ajax_load.asp', '/jquery/jquery_ajax_get_post.asp',
'/jquery/jquery_noconflict.asp', '/jquery/jquery_examples.asp', '/jquery/jquery_quiz.asp', '/jquery/jquery_reference.asp', '/jquery/jquery_ref_selectors.asp',
'/jquery/jquery_ref_events.asp', '/jquery/jquery_ref_effects.asp', '/jquery/jquery_ref_manipulation.asp', '/jquery/jquery_ref_attributes.asp',
'/jquery/jquery_ref_css.asp', '/jquery/jquery_ref_ajax.asp', '/jquery/jquery_ref_traversing.asp', '/jquery/jquery_ref_data.asp',
'/jquery/jquery_ref_dom_element_methods.asp', '/jquery/jquery_ref_core.asp', '/jquery/jquery_ref_prop.asp'], ['jQuery 教程', '', 'jQuery 教程', 'jQuery 简介',
'jQuery 安装', 'jQuery 语法', 'jQuery 选择器', 'jQuery 事件', '', 'jQuery 效果', '', 'jQuery 隐藏/显示', 'jQuery 淡入淡出', 'jQuery 滑动', 'jQuery 动画', 'jQuery stop()',
'jQuery Callback', 'jQuery Chaining', '', 'jQuery HTML', '', 'jQuery 获取', 'jQuery 设置', 'jQuery 添加', 'jQuery 删除', 'jQuery CSS 类', 'jQuery css()', 'jQuery 尺寸', '',
'jQuery 遍历', '', 'jQuery 遍历', 'jQuery 祖先', 'jQuery 后代', 'jQuery 同胞', 'jQuery 过滤', '', 'jQuery AJAX', '', 'jQuery AJAX 简介', 'jQuery 加载', 'jQuery Get/Post', '',
'jQuery 杂项', '', 'jQuery noConflict()', '', 'jQuery 实例', '', 'jQuery 实例', 'jQuery 测验', '', 'jQuery 参考手册', '', 'jQuery 参考手册', 'jQuery 选择器', 'jQuery 事件',
'jQuery 效果', 'jQuery 文档操作', 'jQuery 属性操作', 'jQuery CSS 操作', 'jQuery Ajax', 'jQuery 遍历', 'jQuery 数据', 'jQuery DOM 元素', 'jQuery 核心', 'jQuery 属性',
'', ''])
这是所有链接还有对应链接的所对应的语法模块的名字。那么我们接下来就是去拼接urls,使用的是str的拼接
下载后可阅读完整内容,剩余3页未读,立即下载
2010-06-16 上传
2018-01-27 上传
2014-07-25 上传
2011-08-09 上传
2019-01-02 上传
2020-08-08 上传
2013-06-04 上传

weixin_38641561
- 粉丝: 5
- 资源: 943
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
