小批量情况下Group Normalization优于Batch Normalization
需积分: 50 34 浏览量
更新于2024-09-03
收藏 926KB PDF 举报
Group Normalization (GN) 是一种在深度学习领域中崭露头角的技术,它在 Batch Normalization (BN) 之后成为训练网络的重要里程碑。尽管BN在大规模批量训练时表现出色,但它在小批量情况下的性能却有所下降,主要问题在于批量统计估计的不准确,这会导致误差随着批次大小减小而迅速增加。这一局限性限制了BN在训练大型模型以及应用于如目标检测、图像分割和视频分析等计算机视觉任务中的应用,这些任务通常受内存消耗的约束,需要使用较小的批次。
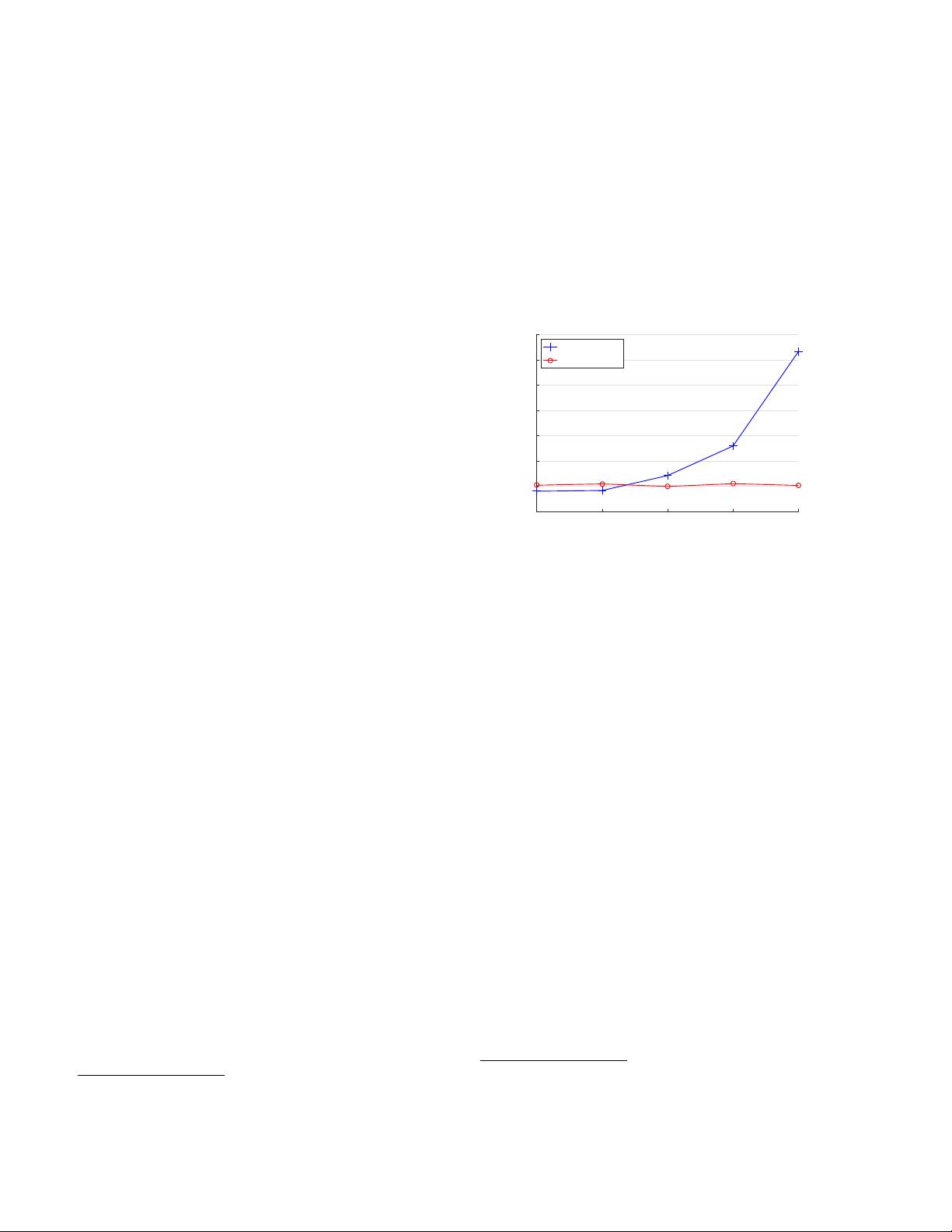
为了克服这一问题,GN 提出了一种简单且有效的替代方案。GN 将通道划分为若干组,对每个组内的数据进行计算,包括计算均值和方差来进行标准化。与 BN 不同,GN 的计算独立于批次大小,因此它能够在更广泛的批次尺寸范围内保持较高的准确性。在 ImageNet 数据集上训练 ResNet-50 模型时,GN 在使用只有2的批次大小时,其错误率比 BN 减少了惊人的10.6%。即使在常规的批次尺寸下,GN 也显示出与 BN 相当的表现,并且优于其他类型的归一化方法。
GN 的优势在于其稳健性和适应性,使得模型在资源有限的情况下仍能保持良好的性能。它的设计简化了模型架构,降低了对大量训练数据的依赖,并且对于那些需要处理小批量数据的任务来说,提供了更具鲁棒性的解决方案。此外,GN 还可能有助于加速训练过程,因为它减少了对批次统计同步的需求,这对于分布式训练环境尤其有利。
Group Normalization 是一项重要的技术创新,它在解决小批量训练问题上取得了突破,为深度学习模型在实际应用中的高效和稳定表现提供了新的可能性。在未来的研究和实践中,GN 可能会成为一种广泛采用的归一化策略,尤其是在资源受限的场景下。
Group Normalization
Yuxin Wu Kaiming He
Facebook AI Research (FAIR)
{yuxinwu,kaiminghe}@fb.com
Abstract
Batch Normalization (BN) is a milestone technique in the
development of deep learning, enabling various networks
to train. However, normalizing along the batch dimension
introduces problems — BN’s error increases rapidly when
the batch size becomes smaller, caused by inaccurate batch
statistics estimation. This limits BN’s usage for training
larger models and transferring features to computer vision
tasks including detection, segmentation, and video, which
require small batches constrained by memory consumption.
In this paper, we present Group Normalization (GN) as
a simple alternative to BN. GN divides the channels into
groups and computes within each group the mean and vari-
ance for normalization. GN’s computation is independent
of batch sizes, and its accuracy is stable in a wide range
of batch sizes. On ResNet-50 trained in ImageNet, GN has
10.6% lower error than its BN counterpart when using a
batch size of 2; when using typical batch sizes, GN is com-
parably good with BN and outperforms other normaliza-
tion variants. Moreover, GN can be naturally transferred
from pre-training to fine-tuning. GN can outperform its BN-
based counterparts for object detection and segmentation in
COCO,
1
and for video classification in Kinetics, showing
that GN can effectively replace the powerful BN in a variety
of tasks. GN can be easily implemented by a few lines of
code in modern libraries.
1. Introduction
Batch Normalization (Batch Norm or BN) [26] has been
established as a very effective component in deep learning,
largely helping push the frontier in computer vision [59, 20]
and beyond [54]. BN normalizes the features by the mean
and variance computed within a (mini-)batch. This has been
shown by many practices to ease optimization and enable
very deep networks to converge. The stochastic uncertainty
of the batch statistics also acts as a regularizer that can ben-
efit generalization. BN has been a foundation of many state-
of-the-art computer vision algorithms.
1
https://github.com/facebookresearch/Detectron/
blob/master/projects/GN.
2481632
batch size (images per worker)
22
24
26
28
30
32
34
36
error (%)
Batch Norm
Group Norm
Figure 1. ImageNet classification error vs. batch sizes. This is
a ResNet-50 model trained in the ImageNet training set using 8
workers (GPUs), evaluated in the validation set.
Despite its great success, BN exhibits drawbacks that are
also caused by its distinct behavior of normalizing along
the batch dimension. In particular, it is required for BN
to work with a sufficiently large batch size (e.g., 32 per
worker
2
[26, 59, 20]). A small batch leads to inaccurate
estimation of the batch statistics, and reducing BN’s batch
size increases the model error dramatically (Figure 1). As
a result, many recent models [59, 20, 57, 24, 63] are trained
with non-trivial batch sizes that are memory-consuming.
The heavy reliance on BN’s effectiveness to train models in
turn prohibits people from exploring higher-capacity mod-
els that would be limited by memory.
The restriction on batch sizes is more demanding in com-
puter vision tasks including detection [12, 47, 18], segmen-
tation [38, 18], video recognition [60, 6], and other high-
level systems built on them. For example, the Fast/er and
Mask R-CNN frameworks [12, 47, 18] use a batch size of
1 or 2 images because of higher resolution, where BN is
“frozen” by transforming to a linear layer [20]; in video
classification with 3D convolutions [60, 6], the presence of
spatial-temporal features introduces a trade-off between the
temporal length and batch size. The usage of BN often re-
quires these systems to compromise between the model de-
sign and batch sizes.
2
In the context of this paper, we use “batch size” to refer to the number
of samples per worker (e.g., GPU). BN’s statistics are computed for each
worker, but not broadcast across workers, as is standard in many libraries.
1
arXiv:1803.08494v3 [cs.CV] 11 Jun 2018
下载后可阅读完整内容,剩余9页未读,立即下载
302 浏览量
189 浏览量
141 浏览量
2025-02-25 上传
2023-07-10 上传
204 浏览量
187 浏览量

玖零猴
- 粉丝: 664
 我的内容管理
展开
我的内容管理
展开







最新资源
- 久度免费文件代存系统 v1.0:全技术领域源码分享
- 深入解析caseyjpaul.github.io的HTML结构
- HTML5视频播放器的实现与应用
- SSD7练习9完整答案解析
- 迅捷PDF完美转PPT技术:深度识别PDF内容
- 批量截取子网页工具:Python源码分享与使用指南
- Kotlin4You: 探索设计模式与架构概念
- 古典风格茶园茶叶酿制企业网站模板
- 多功能轻量级jquery tab选项卡插件使用教程
- 实现快速增量更新的jar包解决方案
- RabbitMQ消息队列安装及应用实战教程
- 简化操作:一键脚本调用截图工具使用指南
- XSJ流量积算仪控制与数显功能介绍
- Android平台下的AES加密与解密技术应用研究
- Место-响应式单页网站的项目实践
- Android完整聊天客户端演示与实践
