Python机器学习入门:数据下载与版本检查
12 浏览量
更新于2024-09-01
收藏 438KB PDF 举报
本资源主要介绍了机器学习的基本概念以及一个具体的入门示例,包括Python环境的检查和数据处理流程。以下是详细的知识点解析:
1. **检查版本信息**:
在进行机器学习项目之前,确保使用的Python版本至少是3.5及以上,因为一些高级库可能依赖于特定版本。通过`sys.version_info`检查Python版本,确认安装了`sklearn`库,并且版本在0.20或更高,以便利用稳定的功能。这对于兼容性和性能至关重要。
2. **获取和整理数据**:
数据是机器学习项目的基石。首先,你需要创建一个名为`lifesat`的目录(如果不存在),然后从指定的GitHub存储库(<https://raw.githubusercontent.com/ageron/handson-ml2/master/>)下载两个CSV文件:`oecd_bli_2015.csv`和`gdp_per_capita.csv`。通过`urllib.request.urlretrieve()`函数实现下载,并将数据保存到指定路径。通过`os.makedirs()`函数创建目录,确保数据存储结构正确。使用`tree datasets`命令查看目录结构,`head -10`用于预览文件的前10行,了解数据前几项内容。
数据加载时,使用`pandas`库的`read_csv()`函数,这个函数提供了丰富的参数选项,如`thousands`用于设置千位分隔符,`delimiter`可以自定义分隔符,`encoding`指定文件的编码方式,`na_values`则定义如何处理缺失值。这些选项有助于确保数据的正确读取和处理。
通过以上步骤,你可以确保你的开发环境满足机器学习项目的需求,并且能够有效地管理和预处理数据,为后续的数据分析、特征工程和模型训练做好准备。在这个过程中,数据的清洗和格式化是至关重要的,它们直接影响到模型的性能和结果的准确性。理解并熟练掌握这些基础操作,是进入机器学习实践的第一步。
thousands=',',delimiter='\t', encoding='latin1', na_values="n/a")
gdp_per_capita_.shape
1.3 预处理数据预处理数据
将OECD's(经合组织)生活满意度数据和IMF's(国际货币基金组织)的人均GDP数据合并在一起
pd.DataFrame.pivot
pd.DataFrame.rename
pd.DataFrame.set_index
pd.DataFrame.merge
pd.DataFrame.sort_values
def prepare_country_stats(oecd_bli, gdp_per_capita):
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"] # 过滤
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value") # 透视
gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True) # 更改轴标签
gdp_per_capita.set_index("Country", inplace=True) # 重置索引
full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,
left_index=True, right_index=True) # 合并
full_country_stats.sort_values(by="GDP per capita", inplace=True) # 排序
remove_indices = [0, 1, 6, 8, 33, 34, 35] # 移除某些国家
keep_indices = list(set(range(36)) - set(remove_indices))
return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices] # 全部国家信息
np.c_
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]] y = np.c_[country_stats["Life satisfaction"]]
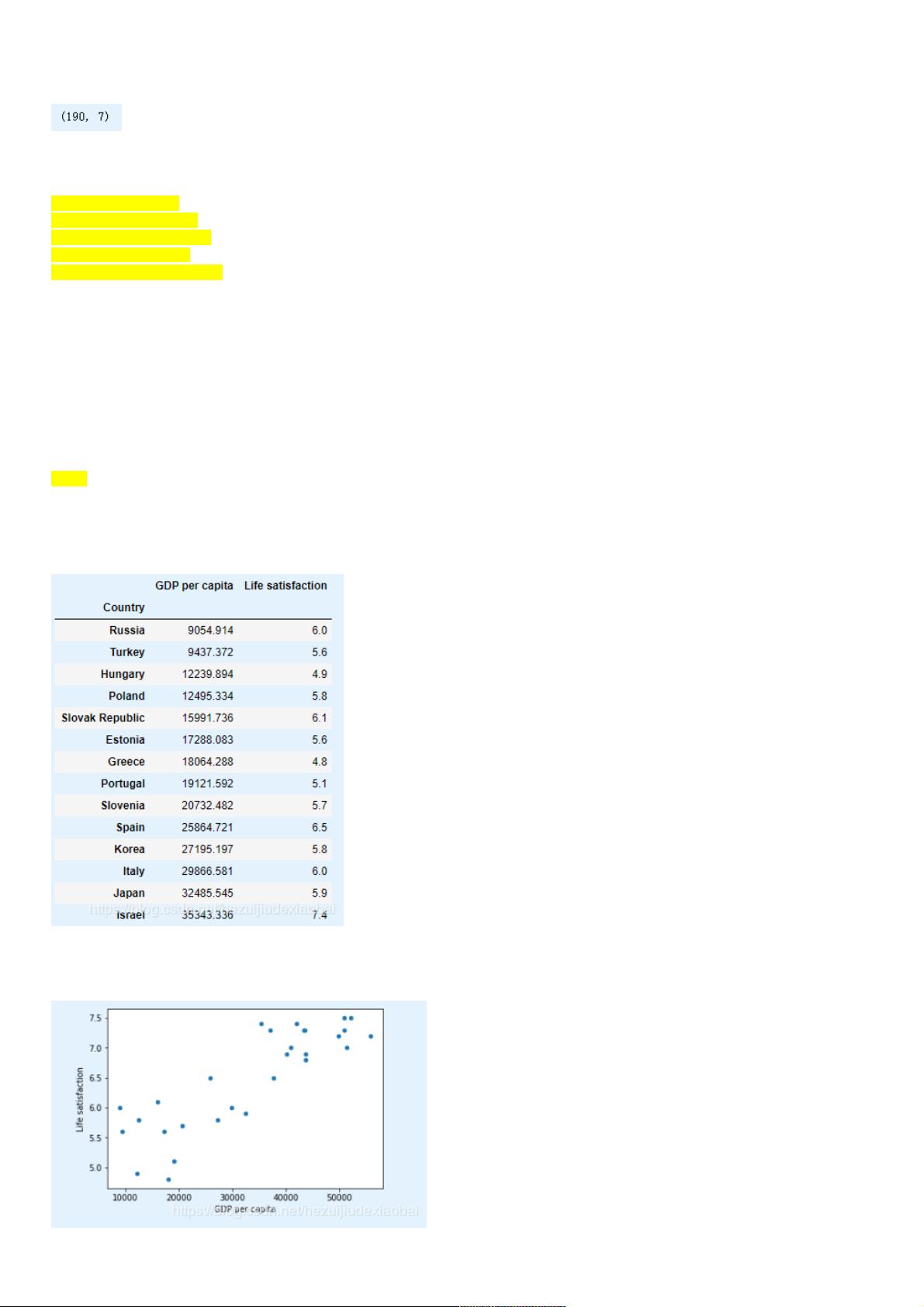
country_stats
1.4 数据可视化数据可视化
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
1.5 线性回归模型线性回归模型
剩余10页未读,继续阅读
2019-08-16 上传
2020-12-09 上传
2022-02-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38733885
- 粉丝: 8
- 资源: 941
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
