深入解读CUDA共享内存的高效应用
版权申诉
23 浏览量
更新于2024-12-09
收藏 163KB PDF 举报
资源摘要信息:"0728-极智开发-解读cuda share memeory"
CUDA (Compute Unified Device Architecture)是NVIDIA推出的一种通用并行计算架构,它允许开发者利用NVIDIA的GPU(图形处理器)进行高性能的计算。CUDA的出现极大地推动了并行计算的发展,使得原本只用于图像渲染的GPU能够用于科学计算、数据分析、人工智能等多种计算密集型任务。
CUDA的共享内存(Shared Memory)是GPU中的一种重要资源,它为线程块(Thread Block)中的线程提供了一种快速的共享存储机制。共享内存比全局内存的访问速度快得多,因此,合理利用共享内存是提高CUDA程序性能的关键。
在理解CUDA共享内存之前,我们需要先了解一些基础概念:
1. **线程层次结构**:
CUDA中的线程被组织成一个三维的网格(Grid),每个网格可以包含多个线程块(Block),而每个线程块又包含多个线程(Thread)。共享内存就是在线程块的级别上提供的,只有同一块中的线程才能访问同一块共享内存。
2. **全局内存与共享内存**:
全局内存是所有线程都可以访问的内存,但其访问速度相对较慢。而共享内存具有更高的访问速度,但其空间有限,并且只能被同一块中的线程访问。
3. **内存访问模式**:
CUDA中有两种内存访问模式:静态内存访问和动态内存访问。共享内存通常用于静态内存访问模式,因为它在编译时就可以确定数据的访问模式,从而更有效地利用硬件特性。
在CUDA程序中使用共享内存的几个关键步骤包括:
1. **声明共享内存**:
在核函数(Kernel Function)中声明共享内存数组,通过`__shared__`关键字来修饰。例如:`__shared__ int sharedArray[256];`
2. **初始化共享内存**:
通常情况下,共享内存的初始化需要在核函数内部通过线程协作完成。线程块中的每个线程负责将全局内存中的数据复制到共享内存中的特定位置。
3. **同步**:
在共享内存的使用过程中,使用`__syncthreads()`函数实现线程同步。这个函数确保了所有线程在继续执行之前都已经完成了对共享内存的访问,从而避免竞态条件。
4. **利用共享内存进行计算**:
线程块内的线程可以利用共享内存中已经加载的数据进行计算,提高数据访问效率。
在理解共享内存的同时,还需要注意以下几点:
- **性能优化**:
充分利用共享内存可以大幅度提升内存访问速度,减少对全局内存的访问次数,从而降低内存访问的延迟,提升整体计算性能。
- **内存占用**:
共享内存的空间有限,一个线程块可以使用的共享内存大小为最高16KB或32KB(取决于NVIDIA GPU的架构)。因此,需要精心设计内存的使用策略,避免超出限制。
- **内存访问模式的优化**:
并行算法的设计应考虑共享内存的访问模式,尽量让同一缓存行(Cache Line)中的数据被多个线程同时访问,以利用GPU的内存带宽。
- **避免bank冲突**:
当多个线程同时访问共享内存中同一bank的不同地址时,可能会产生bank冲突,导致性能下降。设计算法时应尽量减少bank冲突的发生。
- **使用内置函数**:
CUDA提供了内置函数,如`__shfl_up`、`__shfl_down`等,这些函数允许线程之间进行高效的数据交换,有助于减少对共享内存的显式访问,降低bank冲突的风险。
总之,CUDA共享内存是优化GPU并行计算性能的核心技术之一。通过合理设计共享内存的使用策略,开发者可以显著提升CUDA程序的执行效率和性能。在实际应用中,需要根据具体问题的计算特性和数据访问模式,灵活运用共享内存,以实现计算资源的最大化利用。
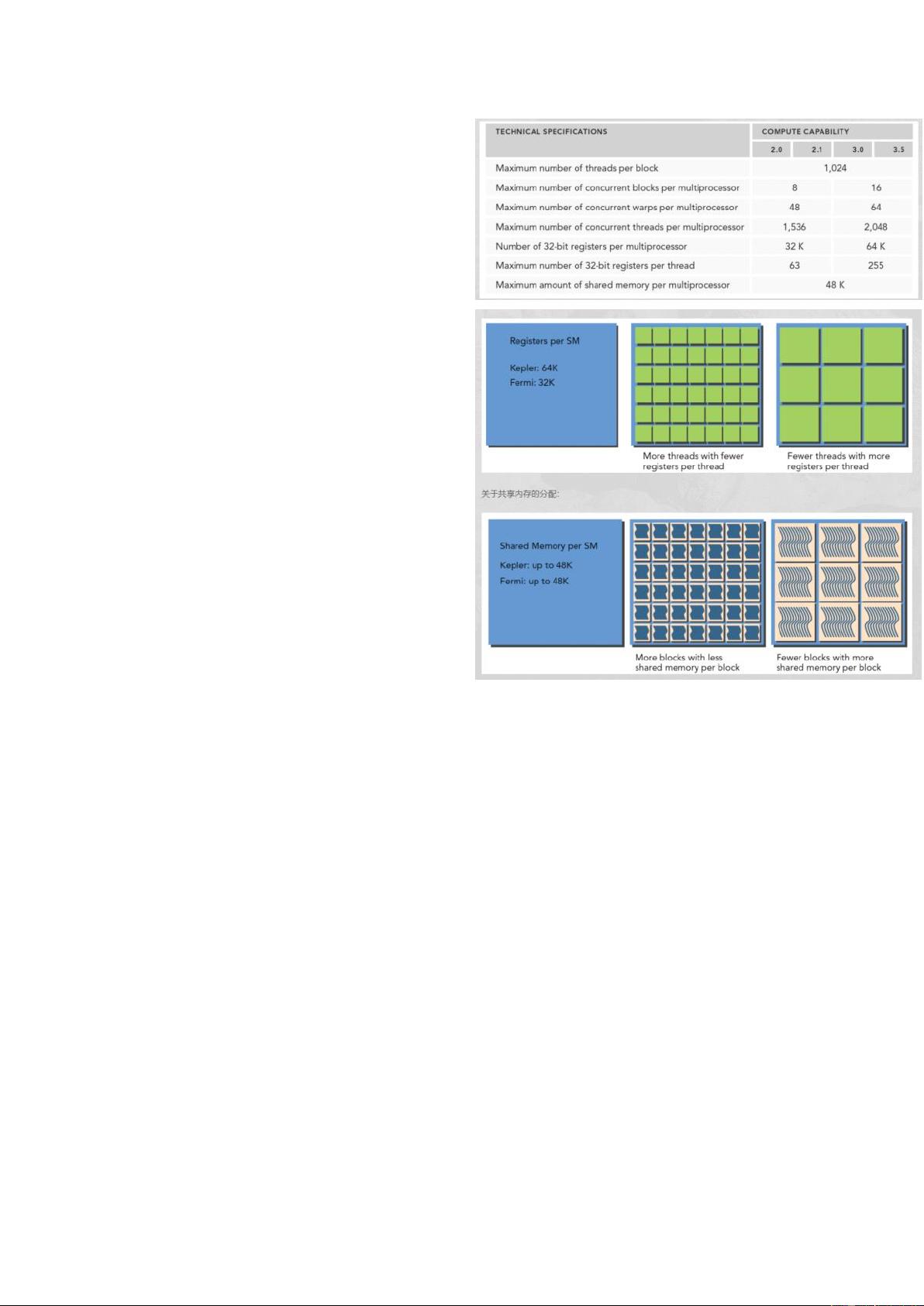
关于share memory的使用:
启动一个kernel函数等于启动一个grid,grid中有多
个blocks,
每一个block共用一块共享内存(一个multiprocessor
48k/64k)
执行的最小单位是一个thread warp,32个
trhreads,SM最多可以执行48个warps。
一个SM上被分配多少个线程块和线程束取决于SM中可
用的寄存器和共享内存,以及内核需要的寄存器和共
享内存大小。
在实际编程的时候考虑的是一个block里需要使用的
数据,将它放到smem中。注:一般blcok是16*
16,256个threads,分到8个warps中,如果是矩阵乘
法只需要将两个分块后的16*16的数据放到share
memory中,我在nms里将block设置为16*16*3之后,
应该是一个block的计算从平面到了立体,这样的
话,smem需要更大的空间,应该会导致更少的tread
warp 激活,所以导致变慢。但是如果每个block都是
计算大小是16*16,应该就不会遇到这种变慢的问
题。
Share memory
2021
年
8
月
16
日 星期一
14:21
分区 快速笔记 的第
1
页
下载后可阅读完整内容,剩余0页未读,立即下载
2024-05-11 上传

极智视界
- 粉丝: 3w+
- 资源: 1769
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
