Python数据挖掘:PCA降维与KMeans聚类实践
需积分: 0 82 浏览量
更新于2024-08-05
1
收藏 3.04MB PDF 举报
"Python数据挖掘课程讲解PCA降维操作及subplot子图绘制,结合Kmeans对糖尿病数据集进行聚类分析。"
PCA(主成分分析)是一种常用的特征降维技术,它通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量。PCA的主要目的是减少数据的复杂性,同时最大化数据中的方差,从而保留最重要的信息。
1. PCA降维操作
PCA的核心思想是找到原始数据的新坐标系,使得新坐标系下的数据方差最大。这个新坐标系就是数据的主要成分,即主成分。在Python中,可以使用`sklearn.decomposition.PCA`库来进行PCA操作。首先,我们需要对数据进行标准化处理,然后应用PCA转换,最后选取保留大部分方差的前几个主成分作为新的特征空间。
2. Python中Sklearn的PCA扩展包
`sklearn.decomposition.PCA`提供了PCA的实现,包括拟合数据、转换数据和获取主成分等方法。通过设置参数`n_components`,可以指定保留的主成分数量。此外,PCA还支持可选的中心化和缩放方法,如`whiten`参数,用于将数据归一化到单位范数。
3. Matplotlib的subplot函数绘制子图
`matplotlib.pyplot.subplot`是用于创建多图布局的函数,它可以创建网格化的子图。通过指定行数、列数和当前图编号,可以在特定位置创建一个新的子图。例如,`plt.subplot(2, 2, 1)`会在2x2的网格中创建左上角的子图。在数据可视化中,subplot函数常用于在同一图形窗口中比较不同特征或模型的效果。
4. K-means聚类
K-means是一种简单且常用的无监督学习算法,用于将数据集分成K个不同的类别。每个类别由其类簇中心定义,而类簇中心是该类别内所有数据点的均值。在Python中,可以使用`sklearn.cluster.KMeans`进行K-means聚类。通过对糖尿病数据集进行K-means聚类,我们可以观察不同类别的分布情况,并通过`subplot`绘制出各类别的散点图,以理解数据的结构和群体特性。
在实际操作中,通常会先用PCA进行降维,然后使用K-means对降维后的数据进行聚类,这样既能减少计算复杂性,又能通过可视化分析聚类结果。PCA有助于识别和去除噪声,K-means则帮助我们发现数据的内在结构。两者结合使用,能够有效地分析高维数据集,尤其在数据可视化和预处理阶段发挥重要作用。
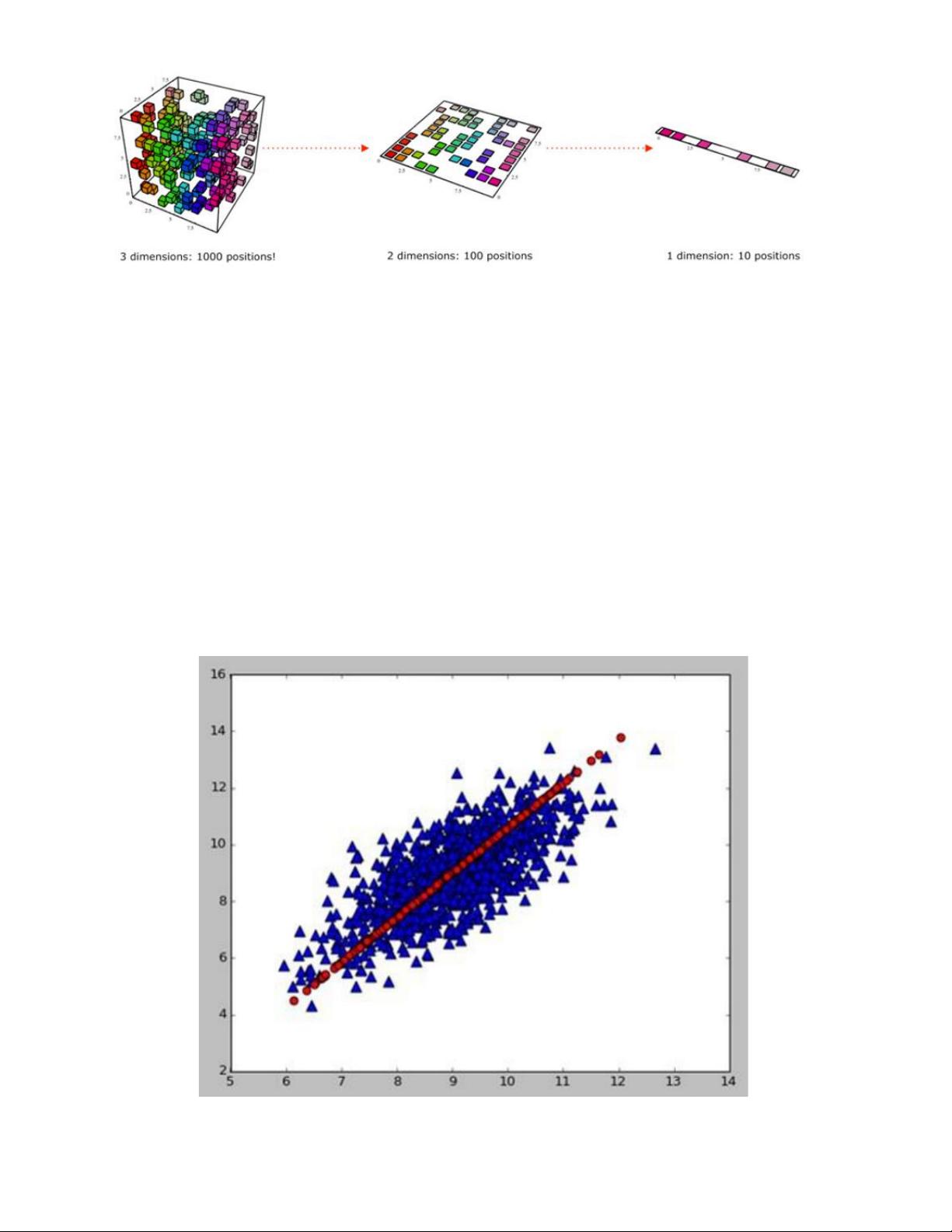
下面着重介绍PCA。
降维的本质是学习一个映射函数f:X->Y,其中X是原始数据点,用n维向量表示。Y
是数据点映射后的r维向量,其中n>r。通过这种映射方法,可以将高维空间中的数据点
主成分分析
(Principal Component Analysis,PCA)是一种常用的线性降维数据
分析方法,其实质是在能尽可能好的代表原特征的情况下,将原特征进行线性变换、映射
至低纬度空间中。
PCA通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换
后的这组变量叫主成分,它可用于提取数据的主要特征分量,常用于高维数据的降维。
该方法的重点在于:能否在各个变量之间相关关系研究基础上,用较少的新变量代替
原来较多的变量,而且这些较少新变量尽可能多地保留原来较多的变量所反映的信息,又
能保证新指标之间保持相互无关(信息不重叠)。
图形解释:
上图将二维样本的散点图降为一维表示,理想情况是这个1维新向量包含
第3页 共13页
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情









