"大规模数据检索解决方案:数据库选择、故障处理、安全保障、检索难题、统计分析"
111 浏览量
更新于2024-01-09
收藏 2.39MB DOCX 举报
ES分布式搜索解决方案.docx中提到了大规模数据如何检索的问题,以及传统数据库和非关系型数据库的应对解决方案。
对于大规模数据的检索问题,通常有以下考虑因素:
1)选择合适的数据库:MySQL、Sybase、Oracle、达梦、神通、MongoDB、HBase等,根据实际需求和数据特点进行选择。
2)解决单点故障:采用负载均衡技术,如LVS、F5、A10等,以及分布式一致性协议,如ZooKeeper和MQ。
3)保证数据安全性:使用热备和冷备策略,以及异地多活方案,确保数据的备份和冗余,以应对数据丢失和灾难恢复。
4)解决检索难题:使用数据库代理中间件,如MySQL-proxy、Cobar、MaxScale等,将查询语句分发到各个节点进行查询,并汇总结果。
5)解决统计分析问题:通过离线和近实时的统计分析方案,对大规模数据进行分析和计算。
针对传统关系型数据库,通常采用以下解决方案:
1)通过主从备份保证数据安全性,将写操作集中在主库上,通过主从同步将数据复制到备库上。
2)使用数据库代理中间件进行心跳监测,保证数据库的高可用性,当主库故障时自动切换到备库。
3)通过代理中间件将查询语句分发到各个从库进行查询,并汇总结果,提高查询效率。
4)通过分表和分库的方式,将数据分散存储在多个表和库中,提高读写效率和扩展性。
而对于非关系型数据库,如Redis,可以采用类似的方案:
1)通过数据复制和持久化策略,保证数据的安全性和可靠性。
2)通过集群模式,将数据分散存放在多个节点中,提高读写效率和可扩展性。
3)使用数据分片和分布式一致性算法,将大规模数据进行分布式存储和查询,提高检索效率。
综上所述,针对大规模数据的检索问题,需要综合考虑数据库选择、数据安全性、单点故障、检索难题和统计分析等因素,采用合适的数据库架构和解决方案来满足需求。对于传统关系型数据库和非关系型数据库,有相应的解决方案来应对查询瓶颈和写入瓶颈,并提高数据的安全性、可用性和查询效率。
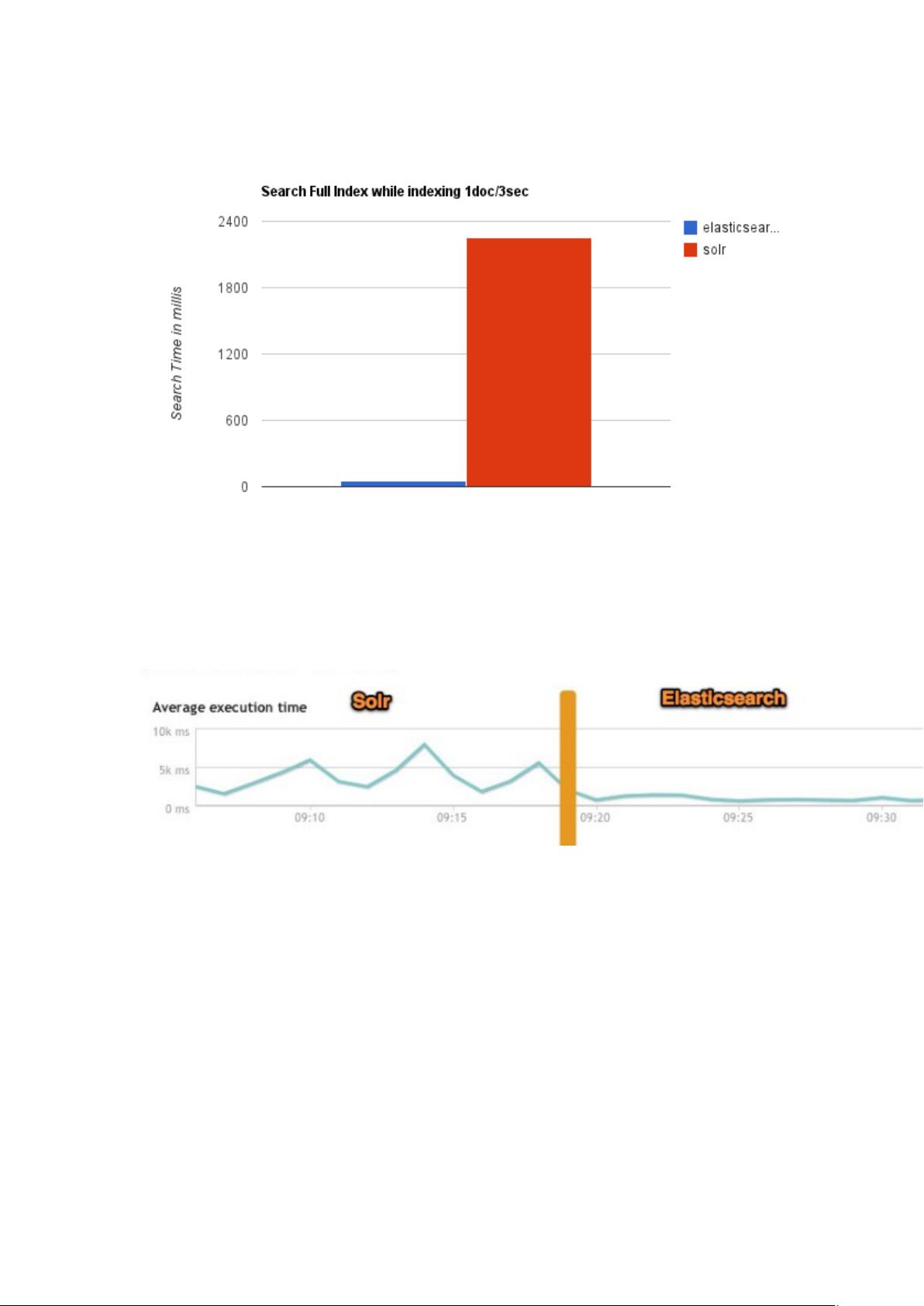
� 大型互联网公司,实际生产环境测试,将搜索引擎从 Solr 转到 Elasticsearch
以后的平均查询速度有了 50 倍的提升。
2.5.2 Elasticsearch 与 Solr 的比较总结
� 二者安装都很简单;
� Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协
调管理功能;
� Solr 支持更多格式的数据,而 Elasticsearch 仅支持 json 文件格式;
� Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功
能多有第三方插件提供;
� Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时
效率明显低于 Elasticsearch。
最终的结论:

剩余39页未读,继续阅读
2024-02-02 上传
2021-10-26 上传
2021-10-26 上传
2021-11-14 上传
2021-10-14 上传
2021-10-24 上传
2024-02-19 上传
2021-01-22 上传

Java码库
- 粉丝: 2374
- 资源: 6186
 我的内容管理
展开
我的内容管理
展开







