Ubuntu上Hadoop安装配置全攻略:从单机到集群
需积分: 0 99 浏览量
更新于2024-06-19
收藏 3.64MB PDF 举报
"在Linux上安装Hadoop的详细步骤与配置"
在进行Hadoop在Linux上的安装之前,我们需要确保系统环境已经准备好。以下是安装Hadoop在Linux(这里以Ubuntu 22.04 LTS为例)上的详细步骤:
1. **前置准备**
- **安装虚拟机**:你可以选择VMware、VirtualBox或WSL来安装Ubuntu虚拟机。在分配资源时,建议至少分配4GB内存和20GB硬盘空间,以确保Hadoop运行的性能。
- **创建hadoop用户**:为了更好地管理Hadoop,我们需要创建一个名为"hadoop"的用户。可以使用以下命令创建新用户并设置密码:
```bash
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
```
- **添加管理员权限**:为了让hadoop用户有执行管理员操作的能力,需要将其添加到sudo组:
```bash
sudo adduser hadoop sudo
```
2. **安装Java环境**
Hadoop依赖Java运行,因此首先需要安装Java Development Kit (JDK)。使用以下命令安装:
```bash
sudo apt update
sudo apt install default-jdk -y
```
安装完成后,验证Java是否已正确安装:
```bash
java -version
```
3. **安装SSH并设置免密登录**
SSH用于节点间的通信,先安装SSH服务:
```bash
sudo apt install openssh-server -y
```
配置SSH免密登录,生成公钥/私钥对:
```bash
ssh-keygen -t rsa
```
接着将公钥复制到authorized_keys文件中:
```bash
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@localhost
```
4. **Hadoop安装配置**
- **实验一:单机版**
对于初学者,可以先尝试在单台机器上安装配置Hadoop。下载Hadoop二进制包,解压并配置环境变量,然后启动Hadoop服务。
- **实验二:集群版**
在多台机器上部署Hadoop集群,需要配置Hadoop的HDFS和YARN以适应集群环境,包括修改`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`等配置文件。
5. **分布式文件系统HDFS**
Hadoop的分布式文件系统(HDFS)是其核心组件,提供高容错性和高吞吐量的数据存储。HDFS允许数据分布在多台机器上,通过NameNode和DataNode节点进行管理。
6. **并行计算模型MapReduce编程实验**
MapReduce是Hadoop处理大数据的主要计算框架。它分为Map阶段和Reduce阶段,适合批处理任务。开发者可以通过编写Mapper和Reducer类实现自定义的计算逻辑。
7. **分布式数据库系统Hbase安装配置实验**
HBase是一个基于Hadoop的分布式NoSQL数据库,提供实时读写访问。安装HBase后,需要配置Hadoop的相关路径,并启动HBase服务。
8. **参考文献**
可以查阅Hadoop官方文档、社区论坛以及技术博客获取更详细的安装和使用指南。
在安装过程中,确保每个步骤都按照最佳实践进行,以保证Hadoop集群的稳定性和高效性。同时,学习理解每个组件的工作原理和配置选项,将有助于优化Hadoop的使用和解决问题。
4
在
安
装
好
SSH Server
后
,
就
可
以
登
录
本机
了
,
⾸
先
运
⾏
:
此
时
需
要
输
⼊
密
码
,
按
照
如
下
⽅
式
配
置
为
免
密
登
录
。
再
次
运
⾏
:
1.
下
载
安
装
包
这
⾥
下
载
最
新
的
stable
版
本
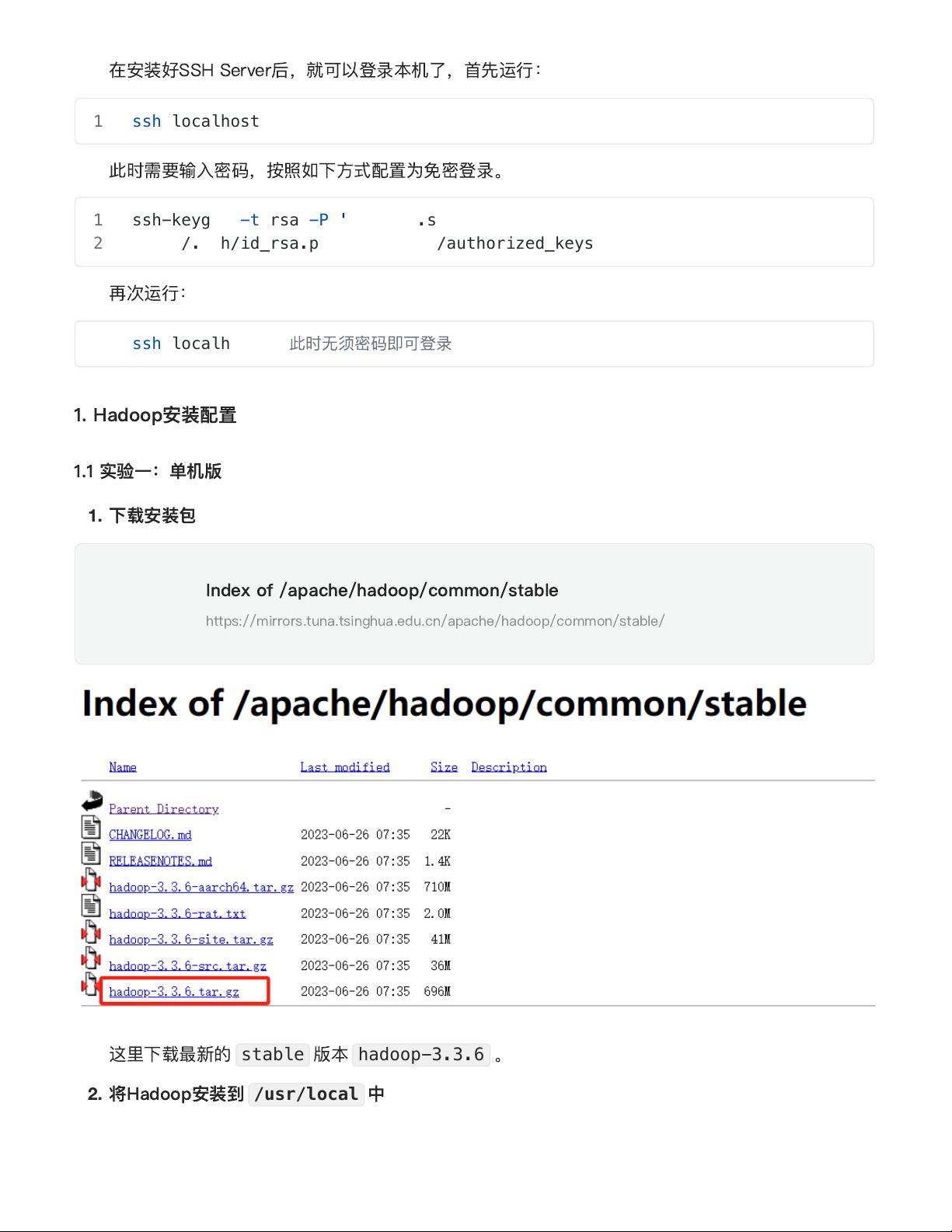
hadoop-3.3.6
。
2.
将
Hadoop
安
装
到
/usr/local
中
1. Hadoop
安
装
配
置
1.1
实
验
⼀:
单
机
版
ssh localhost1
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
1
2
ssh localhost #
此
时
⽆
须
密
码
即可
登
录
1
Index of /apache/hadoop/common/stable
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-12-19 上传
2019-01-06 上传
2018-12-24 上传
2021-10-04 上传
2020-10-14 上传
2019-09-27 上传

zhao20201122515_
- 粉丝: 14
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
