TensorFlow内存管理:深入理解BFC算法
91 浏览量
更新于2024-08-31
收藏 114KB PDF 举报
"本文介绍了TensorFlow内存管理中的BFC(Best-Fit with Coalescing)算法,包括算法的基本思想、申请和释放过程以及bins数据结构。"
在TensorFlow中,内存管理是一个关键环节,以确保高效的计算和避免内存碎片。BFC算法是用于设备内存管理的一种策略,它基于Doug Lea的malloc(dlmalloc)实现,但更为简化。BFC算法的核心目标是高效地分配和回收内存,减少内存碎片,并保持内存空间的利用率。
1. BFC算法基本思想
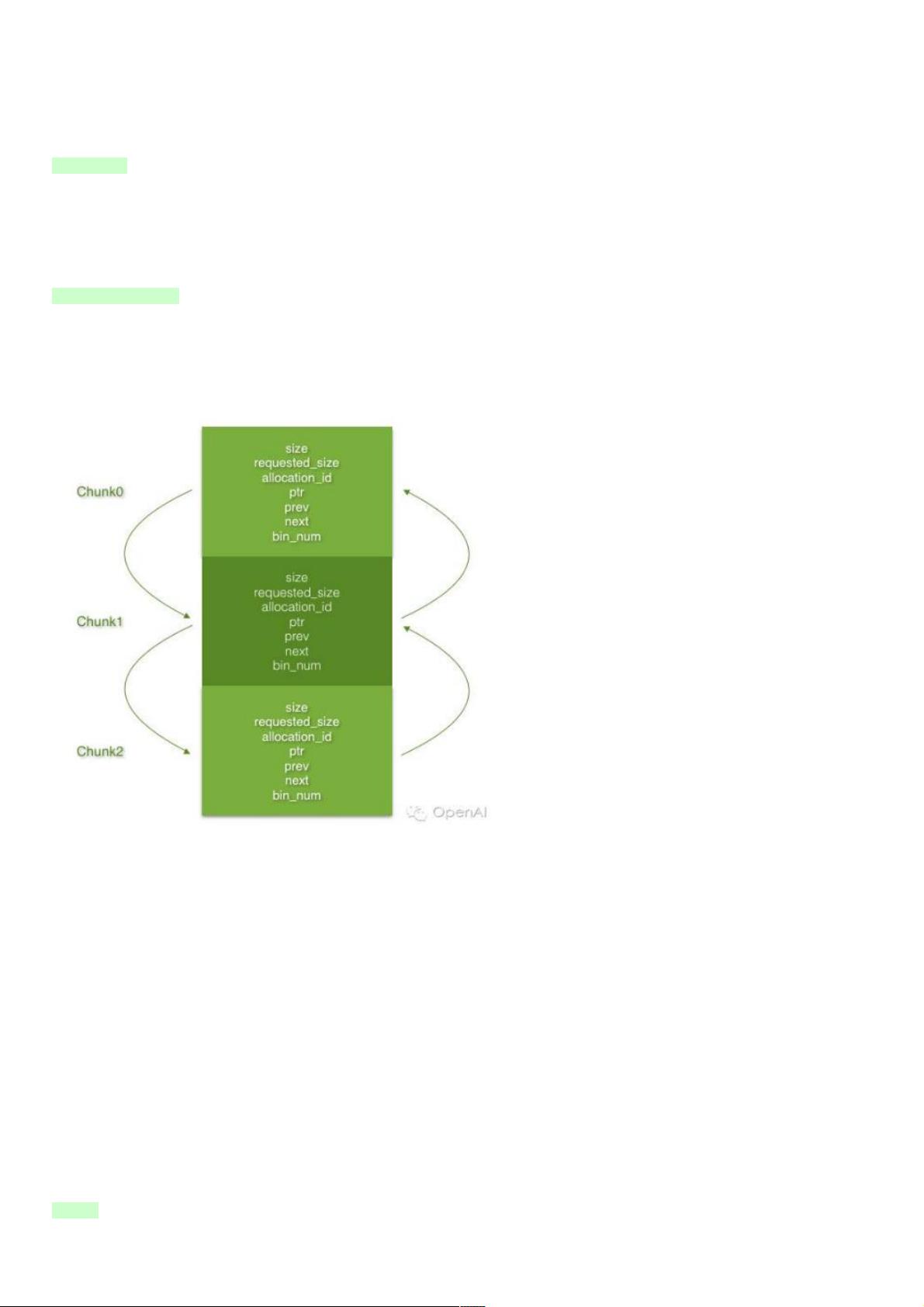
BFC算法通过一个按地址升序排列的Chunk双向链表来组织内存空间。每个Chunk包含关于其大小、请求大小、占用状态、基址以及前驱和后继Chunk的信息。算法主要涉及两个核心操作:split和merge。
2. 分配过程(malloc)
当用户请求内存时,BFC算法会遍历Chunk链表寻找合适的内存块。如果找到的内存块大小超过请求的两倍,它将被split成两部分,较小的部分分配给用户,较大的部分留在链表中。这个过程可以有效地避免大的内存块被过度分割,从而降低碎片的产生。
3. 释放过程(free)
释放内存时,被释放的Chunk会被标记为空闲,并检查其前驱和后继Chunk是否也为空闲。如果是,BFC算法会执行merge操作,将这三个连续的空闲Chunk合并成一个大块,以减少内存碎片并优化内存空间的使用。
4. bins数据结构
BFC算法采用bins来进一步管理内存,bins是一组预定义大小的内存块集合。当Chunk被split后,新创建的小Chunk会被放入对应的bins中,这样在分配内存时可以根据请求大小快速定位合适的Chunk。随着内存分配次数的增加,bins中的Chunk数量会增长,但通过bins,可以更快地找到适合分配的内存块,而不是遍历整个Chunk链表。
TensorFlow的BFC内存管理算法通过split和merge操作,以及bins的数据结构,实现了高效的内存分配和回收,有效地减少了内存碎片,提升了内存使用效率。这对于大规模机器学习模型的训练和推理至关重要,因为内存的高效利用直接影响到模型的性能和运行速度。
TensorFlow内存管理内存管理bfc算法实例算法实例
今天小编就为大家分享一篇TensorFlow内存管理bfc算法实例,具有很好的参考价值,希望对大家有所帮助。一
起跟随小编过来看看吧
1. 基本介绍基本介绍
tensorflow设备内存管理模块实现了一个best-fit with coalescing算法(后文简称bfc算法)。
bfc算法是Doung Lea's malloc(dlmalloc)的一个非常简单的版本。
它具有内存分配、释放、碎片管理等基本功能。
2. bfc基本算法思想基本算法思想
1. 数据结构数据结构
整个内存空间由一个按基址升序排列的Chunk双向链表来表示,它们的直接前趋和后继必须在地址连续的内存空间。Chunk结
构体里含有实际大小、请求大小、是否被占用、基址、直接前趋、直接后继、Bin索引等信息。
2. 申请申请
用户申请一个内存块(malloc)。根据chunk双链表找到一个合适的内存块,如果该内存块的大小是用户申请的大小的二倍以
上,那么就将该内存块切分成两块,这就是split操作。
返回其中一块给用户,并将该内存块标识为占用
Spilt操作会新增一个chunk,所以需要修改chunk双链表以维持前驱和后继关系
如果用户申请512的空间,正好有一块1024的chunk2是空闲的,由于1024/512 =2,所以chunk2 被split为2块:chunk2_1和
chunk2_2。返回chunk2_1给用户并将其标志位占用状态。
3. 释放释放
用户释放一个内存块(free)。先将该块标记为空闲。然后根据chunk数据结构中的信息找到其前驱和后继内存块。如果前驱
和后继块中有空闲的块,那么将刚释放的块和空闲的块合并成一个更大的chunk(这就是merge操作,合并当前块和其前后的
空闲块)。再修改双链表结构以维持前驱后继关系。这就做到了内存碎片的回收。
如果用户要free chunk3,由于chunk3的前驱chunk2也是空闲的,所以将chunk2和chunk3合并得到一个新的chunk2',大小为
chunk2和chunk3之和。
3. bins
1. bins数据结构数据结构
下载后可阅读完整内容,剩余6页未读,立即下载
2020-12-20 上传
点击了解资源详情
2021-05-15 上传
2021-02-09 上传
2022-07-25 上传
2007-08-31 上传
2008-11-26 上传
2021-01-21 上传
点击了解资源详情

weixin_38658982
- 粉丝: 7
- 资源: 940
 我的内容管理
展开
我的内容管理
展开







最新资源
- flex快速入门教程中文版
- jstl js编程实例
- Moss+自定义Feature
- 跟我一起makefile
- XPath+教程.pdf
- thinking in java 4 edition(英文,高清)
- 电力系统谐波测量方法综述
- conextop-en-串口转以太网soc单芯片CXT32SI1X NeChip
- conextop-cn-串口转以太网soc单芯片CXT32SI1X NeChip
- ADC0809AD转换器基本应用技术
- Java Struts教程
- AJAX In Action(中文版) .pdf
- Source-Insight.pdf-经典教程
- 汇编实现二叉树的建立与遍历
- <需求规格说明书>编写参考指南
- Keil C51中文教程
