MapReduce shuffle过程详解与调优指南
PDF格式 | 1.32MB |
更新于2024-08-27
| 199 浏览量 | 举报
“MapReduce shuffle过程剖析及调优”
MapReduce是Hadoop生态系统中的核心组件,用于处理大规模数据并行计算。在MapReduce模型中,数据从Mapper阶段经过shuffle阶段传递到Reducer阶段,以实现基于key的聚合操作。shuffle过程是一个关键环节,因为它确保了Reducer接收到的数据已经按照key进行了排序,这对于后续的聚合操作至关重要。
在Mapper端,map函数生成的结果首先被存储在一个内存中的环形Buffer中。这个环形Buffer是一个特殊的内存数据结构,它由数据区和索引区组成,两者之间有明确的分界点。数据区用于存储Key-Value对,而索引区则记录每个Key-Value对在数据区的具体位置,包括key的起始位置、value的起始位置、partition值以及value的长度,以便于后续的排序和查找操作。
当环形Buffer达到一定容量(通常是预先设定的最大内存使用量减去预留的空间)时,会触发一个叫做Spill的过程。在这个过程中,Buffer中的数据会被写入到磁盘上的临时文件,同时进行局部排序。这个排序是基于key进行的,采用了快速排序或归并排序等高效的算法。在Mapper阶段,可能会有多次Spill操作,每次Spill都会生成一个临时文件。
随着多个Spill文件的生成,接下来会进行合并操作。这些临时文件会被合并成一个或多个大文件,这个过程通常在内存允许的情况下尽可能地合并,以减少磁盘I/O。在合并过程中,相同的key会被聚集在一起,进一步优化了数据的组织。
Reducer端接收到的是经过Mapper shuffle处理后的数据。这些数据按key排序并分发到相应的Reducer,这是因为每个Reducer负责处理一部分特定partition的key。Reducer首先读取Mapper输出的文件,然后对每个key进行聚合操作,如求和、计数等。
性能调优在shuffle过程中非常重要。可以通过调整MapReduce的配置参数来优化这一阶段,比如增大环形Buffer的大小以减少Spill次数,或者调整分区策略以平衡Reducer的工作负载。此外,还可以利用压缩来减少数据传输的体积,提高网络传输效率。
MapReduce的shuffle过程是其核心流程之一,涉及内存管理、排序、磁盘I/O和网络通信等多个层面。理解并掌握shuffle的细节对于优化MapReduce作业的性能具有重要意义,尤其是在处理大数据集时,合理的shuffle调优能够显著提升整体计算效率。
MapReduceshuffle过程剖析及调优过程剖析及调优
MapReduce简介
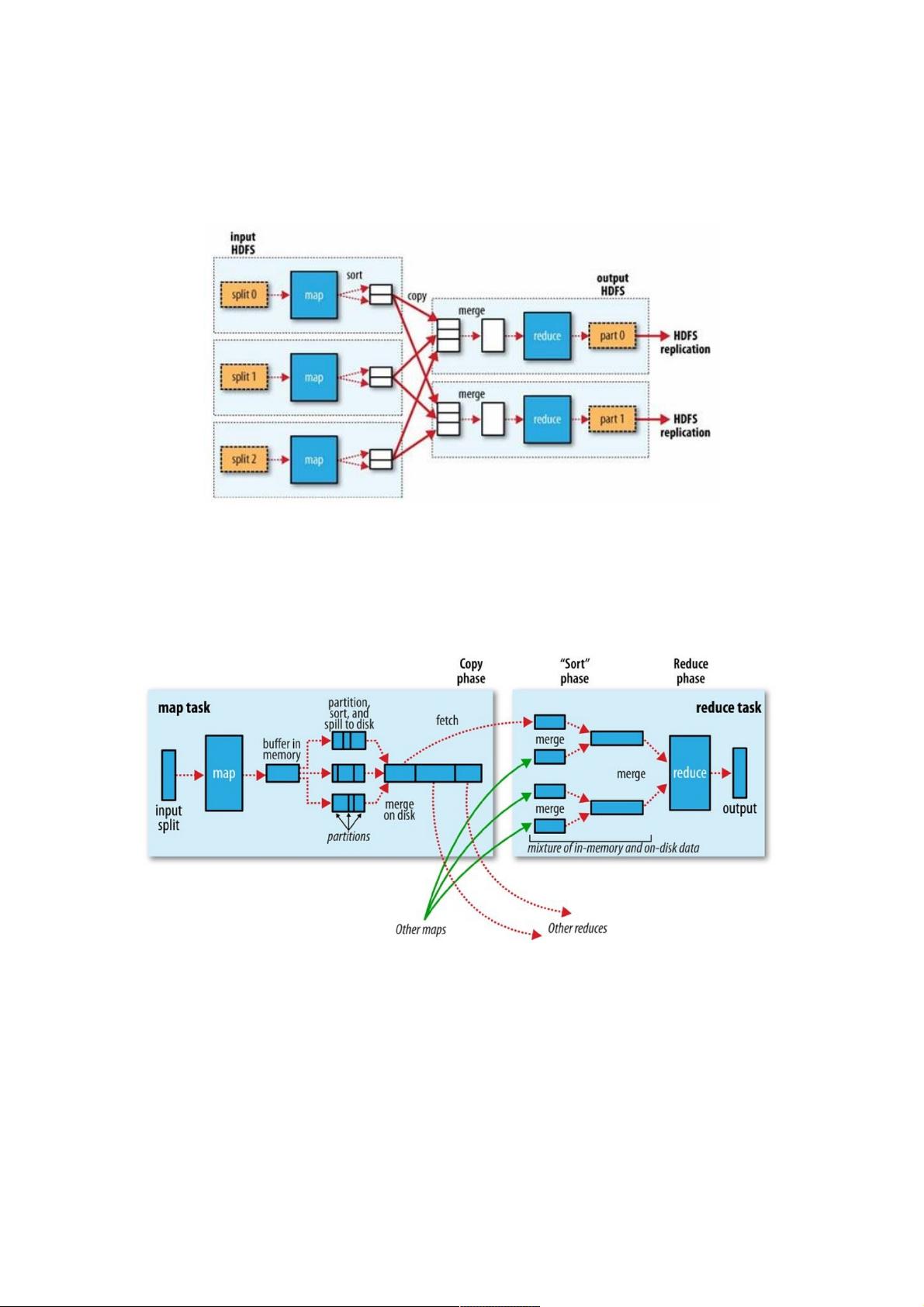
在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的。数据从Mapper输出到Reducer接收,是一
个很复杂的过程,框架处理了所有问题,并提供了很多配置项及扩展点。一个MapReduce的大致数据流如下图:
Mapper的输出排序、然后传送到Reducer的过程,称为shuffle。本文详细地解析shuffle过程,深入理解这个过程对于
MapReduce调优至关重要,某种程度上说,shuffle过程是MapReduce的核心内容。
Mapper端
当map函数通过context.write()开始输出数据时,不是单纯地将数据写入到磁盘。为了性能,map输出的数据会写入到缓冲
区,并进行预排序的一些工作,整个过程如下图:
环形Buffer数据结构
每一个map任务有一个环形Buffer,map将输出写入到这个Buffer。环形Buffer是内存中的一种首尾相连的数据结构,专门用来
存储Key-Value格式的数据:
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐







weixin_38559203
- 粉丝: 5
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- 教育组织领导与激励
- visual c++ vc++收发电子邮件.zip
- easy-location-br:轻松查找巴西各州和城市
- 电子-IAR工程模板.zip
- 易语言源码易语言监视热键例程源码.rar
- SQLite-1.0.65.0-setup.exe
- GenAlgo.zip_matlab例程_matlab_
- 模仿华丽彩虹音频播放器程序源代码,打造炫彩视听体验
- 教育科研课题的全程管理
- AndroidBackBlazeHelper:Android BackBlaze Helper是一个android库,可让Backblaze功能易于使用
- 检测图像偏斜角和偏斜图像
- hsms:HSMS协议JavaScript驱动程序
- 易语言源码易语言监视文件夹源码.rar
- 电子-16液晶屏LCD1602.zip
- 上汽大众天宝869主机5111升级固件
- dpd.zip_matlab例程_matlab_
