Hadoop与HBase基础配置教程
需积分: 3 162 浏览量
更新于2024-07-26
收藏 1.64MB DOCX 举报
"这是关于Hadoop和HBase的基础配置文档,由个人学习心得和网络资料整理而成。"
在本文档中,我们将深入探讨Hadoop和HBase这两个关键的大数据处理技术。Hadoop是一个开源软件框架,专门用于可靠的、可扩展的分布式计算。其核心在于提供了一种能够在计算机集群上进行大规模数据处理的简单编程模型。
Apache Hadoop包含以下几个主要子项目:
1. Hadoop Common:支持其他Hadoop子项目的通用工具集,包括文件系统交互、网络通信、日志管理和故障检测等。
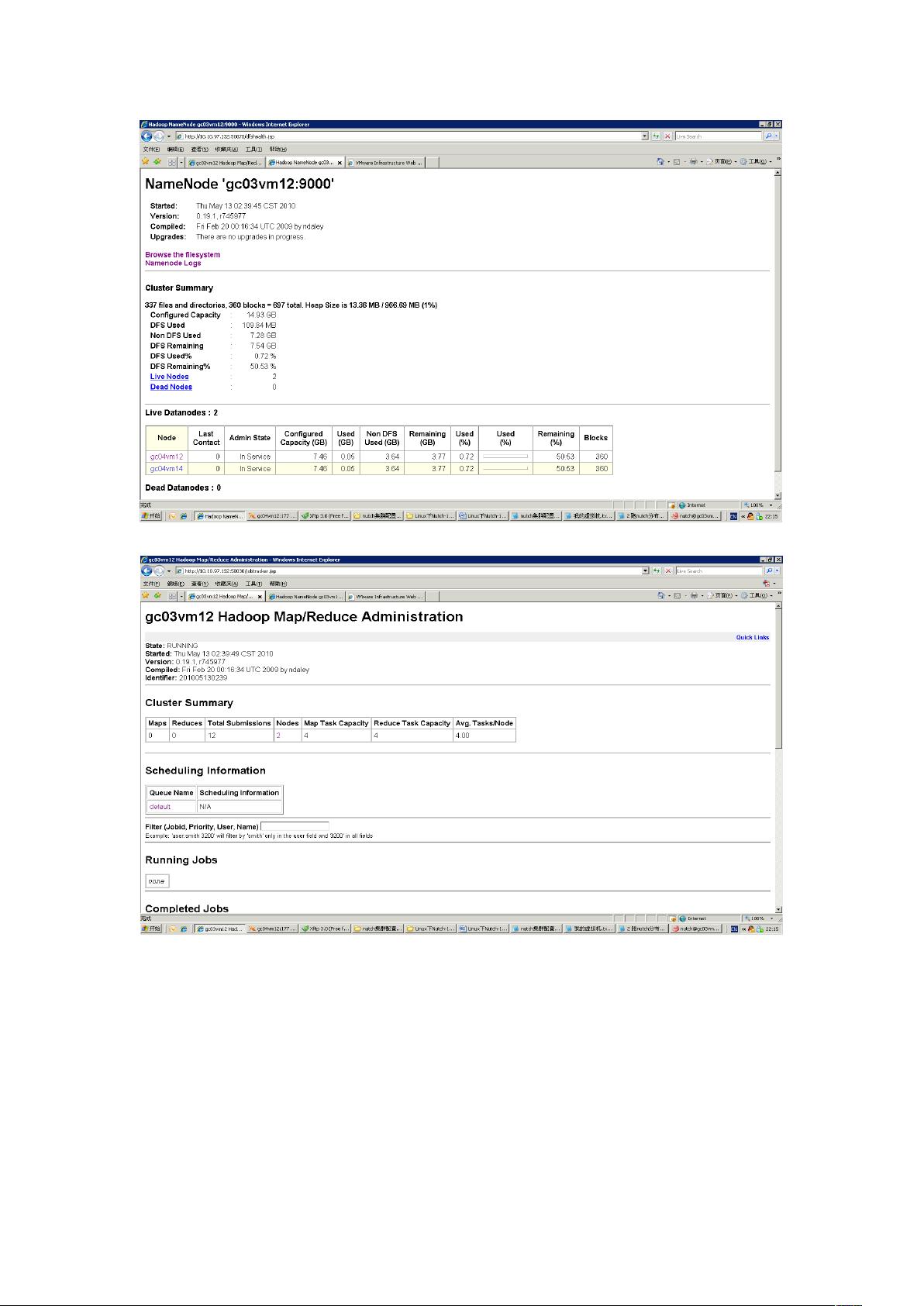
2. Hadoop Distributed File System (HDFS):这是一个分布式文件系统,能够高吞吐量地访问应用程序数据。HDFS设计的目标是在单个服务器扩展到数千台机器的集群上,每台机器都提供本地计算和存储能力。通过在应用层检测和处理失败,HDFS能够在硬件可能出现故障的集群上提供高可用性服务。
3. Hadoop MapReduce:这是一个用于在计算集群上分布式处理大型数据集的软件框架。MapReduce将复杂的数据处理任务分解为两个阶段——Map(映射)和Reduce(规约),使得数据处理变得更加并行化和高效。
除了这些核心组件,还有与Hadoop相关的其他Apache项目,例如:
1. Avro:一个数据序列化系统,用于定义数据结构并进行跨语言的通信,它提供了紧凑的二进制格式,提高了数据传输效率。
2. Cassandra:一种可扩展的多主数据库系统,旨在处理大规模的数据分布,特别适合实时读写操作和大数据分析。
在配置Hadoop和HBase时,你需要考虑以下几个关键方面:
1. 安装与环境配置:确保所有节点的硬件配置一致,操作系统兼容,并且正确配置了Java环境。
2. Hadoop集群配置:包括设置HDFS的副本数、块大小、NameNode和DataNode的配置,以及YARN(Yet Another Resource Negotiator)的配置以管理集群资源。
3. HBase配置:定义HBase的区域服务器,设置ZooKeeper(协调分布式服务的工具)集群,以及优化HBase的内存和磁盘使用。
4. 数据模型:理解HBase的行、列族、列和时间戳的概念,以及如何根据业务需求设计合适的数据模型。
5. 性能调优:监控系统性能,调整Hadoop和HBase的参数以提高读写速度、减少延迟,以及优化资源利用率。
6. 安全性:实现用户认证、授权和审计,以保护数据安全,可能需要配置Kerberos或其他安全框架。
7. 故障恢复和容错:了解如何备份和恢复Hadoop和HBase的数据,以及如何处理节点故障。
8. 监控与维护:使用如Ambari这样的工具来监控集群健康状态,定期进行维护,包括数据清理、节点检查和性能评估。
这个文档系列将逐步引导你完成这些配置步骤,同时也会介绍如何利用Hadoop和HBase处理实际的大数据问题。无论你是初学者还是经验丰富的开发者,这个文档都将是你理解并掌握这两个强大工具的宝贵资源。

,;!(-(-1>>!831-@29
A,;>'-1(+--!8>+'@29
%="6 ;>>3'!+(+''8>++@29
%="?;!+'+(3'8!++!29
%="?^;('3^
.................................................
%7;-8-G(9
;>+!>1!;(((
% ";
,;'(+!1'''8>3!@29
%="?;-+!3(+38--29
%="?;3-!3'-+3'83(>@29
%="6 ;-!>>>!!8-->@29
%="?^;(3^
%="6 ^;33^
C;4,-(!;>;>"4+((
;>+!>++;(((
% ";
,;'(+!1'''8>3!@29
%="?;-+!3(+38--29
%="?;-'>'31+8-1@29
%="6 ;3-('33!>+8-'@29
%="?^;(3^
%="6 ^;3^
C;4,-(!;>;1"4+((
;>+!>(';(((
% ";
,;'(+!1'''8>3!@29
%="?;-+!3(+38--29
%="?;-'>'31+8-1@29
%="6 ;3-('33!>+8-'@29
%="?^;(3^
%="6 ^;3^
C;4,-(!;>;1"4+((
?7;N;** ;((>(

剩余63页未读,继续阅读
2018-08-28 上传
2013-01-07 上传
2014-08-11 上传
2012-09-14 上传
2021-06-21 上传
点击了解资源详情
点击了解资源详情
2019-08-11 上传
2013-11-11 上传

sabrinachen21
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 非常不错的在线邮件群发系统官方版v1.1
- ng-auth:角度中的简单身份验证受限状态
- 4Coders-MeuCandidatoIdeal:黑客马拉松透明度巴西应用程序
- Memory-Game:原生Android记忆游戏应用
- 心情MTV网站系统官方版 v2.0
- 红警2mix文件加密器
- chasqientrega:https
- 广告牌彩灯闪烁控制程序+设计说明.rar
- frontend-boilerplate
- aspectjs:aspectjs切面编程
- mail-bot:基于条件的邮件机器人
- Hotel_website:CSS中的基本酒店网站
- 手机九宫格html5网站模板
- 水国类数据集(CV专用)
- 中国城市区域数据.zip
- ASOFI3D_时域各向异性地震建模_c语言_地震建模_时域_各向异性_ASOFI3D_建模_地震_3D
