Lucene全文检索引擎解析与源码分析
版权申诉
91 浏览量
更新于2024-07-05
收藏 1.42MB PDF 举报
"开放源代码的全文检索引擎Lucene归类.pdf"
全文检索引擎Lucene是一种广泛使用的开源全文搜索引擎库,由Apache软件基金会维护。它提供了强大的文本分析、索引和搜索功能,允许开发者构建高效的搜索应用。Lucene最初设计为Java库,但现在也支持其他编程语言,如Python(通过PyLucene)和.NET(通过Lucene.NET)。本资源深入介绍了Lucene的核心概念、系统结构以及源码实现分析。
全文检索系统是基于全文检索理论构建的软件系统,它包括索引创建、查询处理和结果展示等核心功能。在Lucene中,这一过程涉及以下几个主要组件:
1. 文本分析引擎:负责将原始文本预处理成可索引的形式。这包括分词、去除停用词、词形还原等步骤,以便于后续的索引和搜索操作。
2. 索引引擎:创建倒排索引,这是一种高效的数据结构,可以快速定位文档中包含特定词汇的位置。每个词项都有一个列表,列出包含这个词的所有文档及其在文档中的位置。
3. 查询引擎:接收用户的查询字符串,解析并转换成内部查询表示,然后在索引中执行查询,找到相关文档。
4. 对外接口:提供API供开发者集成到自己的应用程序中,允许灵活定制查询逻辑和结果处理。
在图1.1所示的结构中,全文检索引擎作为核心,支持各种外围应用系统的构建。这些外围应用可能包括Web界面、数据导入工具、结果排序和过滤策略等。Lucene的开放源代码特性使得开发者可以根据需求对其进行扩展或定制,例如添加对新语言或特殊文本格式的支持,如XML或HTML。
Lucene的优势在于其性能和灵活性。通过优化的索引结构和查询算法,它可以处理大规模的数据集,提供实时搜索体验。同时,Lucene的模块化设计允许开发者根据实际场景调整各个组件,以适应不同的业务需求。
对于中文全文检索,Lucene提供了ikanalyzer、smartcn等分词器,解决了中文分词这一挑战。这些分词器能够有效地将汉字序列拆分成有意义的词语,从而实现中文文本的正确索引和搜索。
总结来说,Lucene作为一个强大的全文检索工具,是构建高级搜索功能的基石。它不仅提供了基础的搜索功能,而且允许开发者深入到源码层面进行优化和扩展,以满足各种复杂的应用场景。通过理解和掌握Lucene,开发者可以创建出高效、精准且易于维护的全文检索应用。
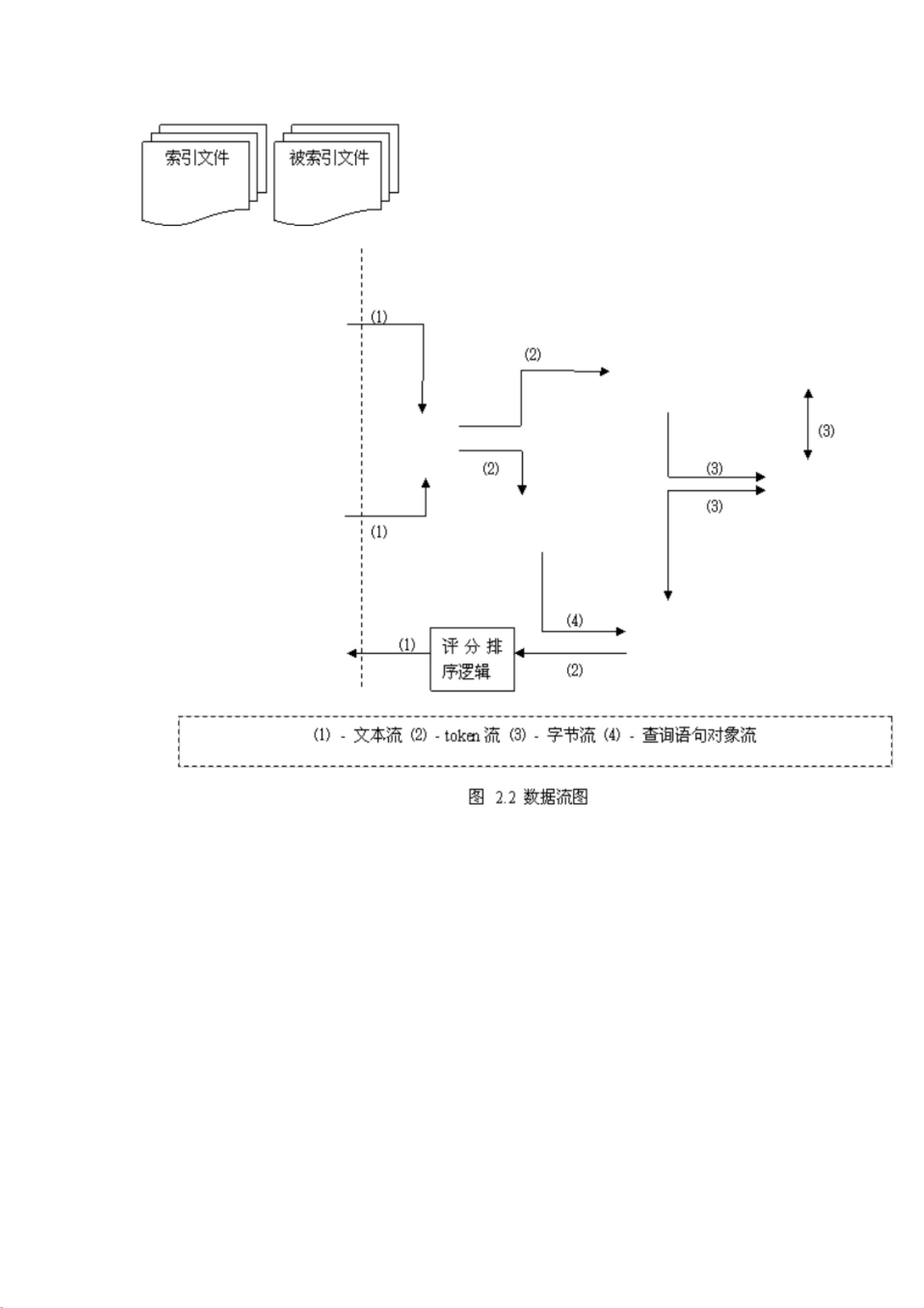
图 2.2 很好的表明了 Lucene 在内部的数据流组织情况, 并且沿着数据流的方向我们也可以对与 Lucen
e 内部的执行时序有一个清楚的了解。现在将图中的涉及到的流的类型与各个逻辑对应系统的相关部分的
关系说明一下。
图中共存在 4 种数据流,分别是文本流、 token 流、字节流与查询语句对象流。文本流表示了对于索
引目标和交互控制的抽象,即用文本流表示了将要索引的文件,用文本流向用户输出信息;在实际的实现
中,Lucene 中的文本流采用了 UCS-2[19] 作为编码,以达到适应多种语言文字的处理的目的。 Token 流是 L
ucene 内部所使用的概念,是对传统文字中的词的概念的抽象,也是 Lucene 在建立索引时直接处理的最小
单位;简单的讲 Token 就是一个词和所在域值的组合,后面在叙述文件格式时也将继续涉及到 token ,这
里不详细展开。字节流则是对文件抽象的直接操作的体现,通过固定长度的字节( Lucene 定义为 8 比特位

剩余39页未读,继续阅读
2007-07-25 上传
632 浏览量
2020-08-14 上传
2021-08-11 上传
2023-01-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

cy18065918457
- 粉丝: 0
- 资源: 7万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C8051下载线制作
- Java学习从入门到精通
- 国家标准软件开发规范---软件需求说明书规范.pdf
- 毕业设计计算机相关文章翻译
- 国家标准软件开发规范---软件配置管理计划规范.pdf
- Wrox - Beginning SQL(2005).pdf
- div+css+js 实现透明屏蔽当前页面,并弹出新层进行操作。推荐哦
- 基于J2EE的Ajax宝典
- 国家标准软件开发规范---模块开发卷宗规范.pdf
- Weblogic管理员手册
- 国家标准软件开发规范---概要设计说明书规范.pdf
- 国家标准软件开发规范---测试计划规范.pdf
- 构建嵌入式Linux系统(英文第三版)
- 国家标准软件开发规范模板---操作手册规范.pdf
- TIPTOP GP 如何进行数据的导入、导出
- ibatis 开发指南.pdf
