人工智能基础:命题逻辑与推理方法
"这是一份关于人工智能导论的文档,源自成都信息工程大学的期末复习资料。文档涵盖了命题逻辑、一阶谓词逻辑、演绎逻辑推理、溯因不确定推理以及非单调推理等多个核心概念。"
在人工智能领域,逻辑是理解和构建智能系统的基础。命题逻辑(Propositional Logic)是逻辑推理的基础,用于表示和处理简单的真值表达式,如(P->Q)∧(P->¬R)。这种表达式由连接词(¬, ∧, ∨, →, ⇔)组成,用来组合不同的命题形成更复杂的逻辑结构。一阶谓词逻辑(First-Order Predicate Logic)则引入了常量、谓词、函数和变量,使得表达能力更加强大,可以描述更为复杂的事实和关系。
在讲授逻辑推理时,文件提到了演绎(Deductive)和溯因(Abductive)两种方法。演绎推理基于逻辑规则,从一般到特殊,如所有的球在盒子里都是黑色的(所有A都是B),如果这些球来自盒子(A),那么这些球是黑色的(B)。而溯因推理则是从特定观察(例如,这些球是黑色的B)推断可能的原因(可能是来自盒子的A)。它并不保证结论的必然性,而是提出最有可能的解释。
此外,文件还涉及了归纳推理(Induction),这是从特定实例或观察中概括出一般规律的过程。例如,通过观察到从盒子中取出的球是黑色的,我们可以推测盒子里的所有球可能都是黑色的。
框架(Frame)的概念是人工智能中知识表示的一种方式,它有多个槽(Slots),每个槽代表与其他框架或值的关系。槽可能有多个方面(Facets),表示关系的不同方面。
非单调推理是人工智能中的重要概念,它涉及到推理规则在新信息加入后可能会改变其有效性。例如,演绎推理不是非单调的,因为它基于的前提不变,结论始终成立。而归纳和溯因推理则可能因为新信息而修改或撤销先前的结论。
这份文档提供了人工智能基础知识的概览,对学习者来说,理解和掌握这些概念对于深入理解AI的工作原理至关重要。通过复习这些内容,学生能够更好地准备期末考试,并建立起坚实的人工智能理论基础。
Lecture 07
Hill Climbing(爬山法):梯度下降
Recall from CSPs lecture: simple, general idea
Start wherever
Repeat: move to the best neighboring state
If no neighbors better than current, quit
What’s particularly tricky(难办的) when hill-climbing for multiclass logistic regression(倒退)?
Optimization over a continuous space
Infinitely many neighbors!
How to do this efficiently?
Lecture 08
决策树:ID3、C4.5
• Advantage of attribute-decrease in uncertainty
• Entropy(熵) of Y before you split
H ( y )=−P( y=T )log P( y=T )−P( y =F )log P( y=F)=−5/6 log(¿5 /6)−1/6 log(¿1/6)¿¿
• Entropy after split: Weighted by probability of following each branch,
H (Y
|
X )=
∑
j=1
v
P( X=x
j
)
∑
i= 1
❑
P(Y = y
j
|
X=x
j
)log
2
P(Y = y
j
|
X=x
j
)
• Information gain is difference:
IG
(
X
)
=H
(
Y
)
−H
(
Y
|
X
)
Gain(S , A )≡ Entropy(S)−
∑
v∈ Values ( A )
|
S
v
|
|
S
|
Entropy (S
v
)
ID3:
Maximize information gain
info
(
D
)
=−
∑
i =1
m
p
i
log
2
(
p
i
)
inf o
A
(
D
)
=
∑
j= 1
v
|
D
j
|
|
D
|
info
(
D
j
)
gain
(
A
)
=info
(
D
)
−inf o
A
(
D
)
C4.5
ID3 tends to split on attributes with more values
Maximize information gain ratio
split_info
A
(D)=−
∑
j=1
v
❑
|
D
j
|
¿ D∨¿ log
2
¿¿
ID3 步骤:
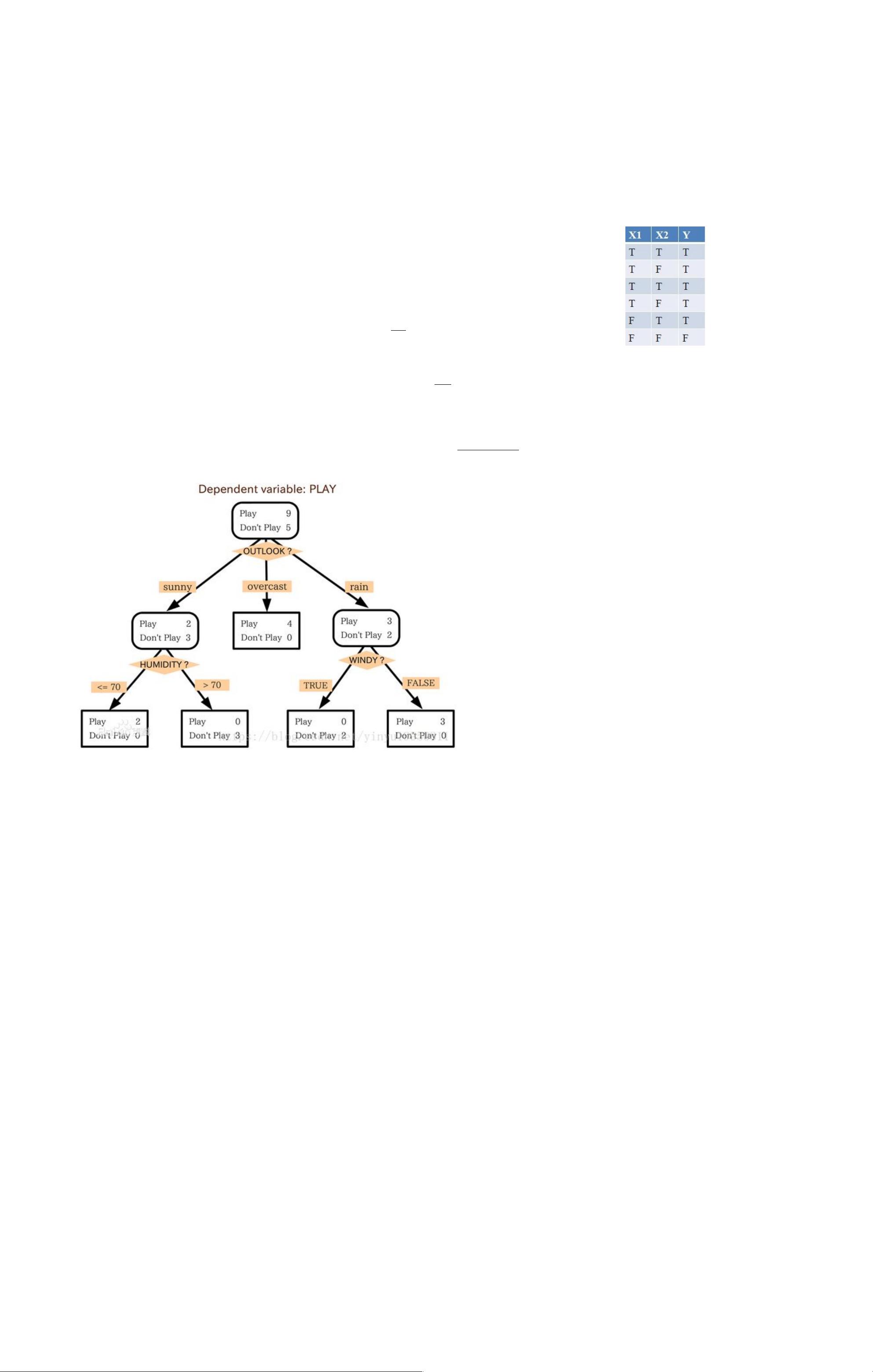
1. Start with a training data set, which we'll call S. It should have attributes(属性) and classifications(类别). The attributes of PlayTennis are outlook, temperature
humidity, and wind, and the classificationis whether or not to play tennis. There are 14 observations.
2. Determine the best attribute in the data set S. The first attribute ID3 picks in our example is outlook. We'll go over the definition of “best attribute” shortly.
3. Split S into subsets that correspond to the possible values of the best attribute. Under outlook, the possible values are sunny, overcast, and rain, so the data is split into
three subsets(rows 1, 2, 8, 9, and 11 for sunny; rows 3, 7, 12, and13 for overcast; and rows 4, 5, 6, 10, and 14 for rain).
4. Make a decision tree node that contains the best attribute. The outlook attribute takes its rightful place at the root of the PlayTennis decision tree.
5. Recursively(递归) make new decision tree nodes with the subsets of data created in step #3. Attributes can't be reused. If a subset of data agrees on the
classification, choose that classification. If there are no more attributes to split on, choose the most popular classification. The sunny data is split further on humidity
because ID3 decides that within the set of sunny rows(1, 2, 8, 9, and 11), humidity is the best attribute.The two paths result in consistent classifications——sunny/high
humidity always leads to no and sunny/normal humidity always leads to yes——so the tree ends after that. The rain data behaves in a similar manner, except with the
wind attribute instead of the humidity attribute. On the other hand, the overcast data always leads to yes without the help of an additional attribute, so the tree ends
immediately.
决策树问题:overfitting(过度拟合)
Overfitting:
When you stop modeling the patterns in the training data (which generalize)
And start modeling the noise (which doesn’t)
如何避免
How can we avoid overfitting?
stop growing when data split not statistically significant
grow full tree, then post-prune(修剪后)
如何控制
Limit the hypothesis(假设) space
E.g. limit the max depth of trees
Easier to analyze
Regularize the hypothesis selection
E.g. chance cutoff
Disprefer most of the hypotheses unless data is clear
Usually done in practice
Lecture 09
Classification from similarity
Case-based(基于实例) reasoning
Predict an instance’s label using similar instances
Nearest-neighbor classification
1-NN: copy the label of the most similar data point
K-NN: vote the k nearest neighbors (need a weighting scheme(方案))
Key issue: how to define similarity
Trade-offs: Small k gives relevant neighbors, Large k gives smoother functions
K-Means(欧氏距离)
An iterative(迭代) clustering algorithm
Pick K random points as cluster centers (means)
Alternate:
Assign data instances to closest mean
Assign each mean to the average of its assigned points
Stop when no points’ assignments change
剩余11页未读,继续阅读
6797 浏览量
2023-02-16 上传
2022-11-25 上传
395 浏览量
217 浏览量
2022-12-15 上传
2023-09-19 上传

伊织萌
- 粉丝: 3623
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







