R-FCN:基于区域的全卷积网络目标检测
需积分: 30 5 浏览量
更新于2024-09-09
收藏 8.62MB PDF 举报
"R-FCN (Region-based Fully Convolutional Networks) 是一种用于精确高效目标检测的技术,由微软研究院的研究人员提出。该方法通过在全卷积网络中引入位置敏感得分图,解决了图像分类中的平移不变性和目标检测中的平移变异性之间的矛盾。R-FCN可以自然地采用最先进的残差网络(ResNets)作为其图像分类器的基础,以实现目标检测。在PASCAL VOC数据集上,如2007设置,R-FCN达到了83.6%的mAP(平均精度),并且在测试时速度达到每图像170毫秒,比Faster R-CNN快2.5到20倍。"
R-FCN(区域基全卷积网络)是一种深度学习模型,专门设计用于目标检测任务。传统的区域基检测器,如Fast/Faster R-CNN,会在每个候选区域上执行昂贵的子网络计算,这大大增加了计算成本。R-FCN则采用了一种全新的方法,它构建了一个完全卷积的区域基检测器,几乎所有的计算都在整个图像上共享,极大地提高了效率。
关键创新在于位置敏感得分图(Position-Sensitive Score Maps)。在图像分类任务中,网络通常追求平移不变性,即无论目标在图像中的位置如何,其分类结果都应保持不变。然而,在目标检测中,我们需要对目标的位置非常敏感。位置敏感得分图就是为了解决这一问题而提出的,它允许网络在保持分类能力的同时,捕捉目标的位置信息。
R-FCN利用了当时最新的深度学习架构——残差网络(Residual Networks,ResNets)。ResNets通过引入残差块,解决了深度神经网络中的梯度消失问题,使得更深的网络能够训练得更好。R-FCN将ResNets作为其基础模型,从而在保持高性能的同时,实现了目标检测的端到端训练和高效推理。
在性能方面,R-FCN在PASCAL VOC数据集上展示了与Faster R-CNN相当甚至更优的结果。PASCAL VOC是一个广泛用于目标检测和分割任务的数据集,包含多个类别。R-FCN在2007年的数据集上达到了83.6%的mAP,这是一个衡量检测精度的重要指标。同时,R-FCN的测试速度远超Faster R-CNN,显示了其在实际应用中的优势。
R-FCN是目标检测领域的重大进步,它通过创新的位置敏感得分图和利用ResNets,实现了高性能和高效率的平衡。这一技术不仅推动了目标检测领域的研究,也为后续的工作提供了重要的参考和启发。
ƉĞƌͲZŽ/
conv
RoI
pool
conv
RoIs
conv
ZWE
vote
feature
maps
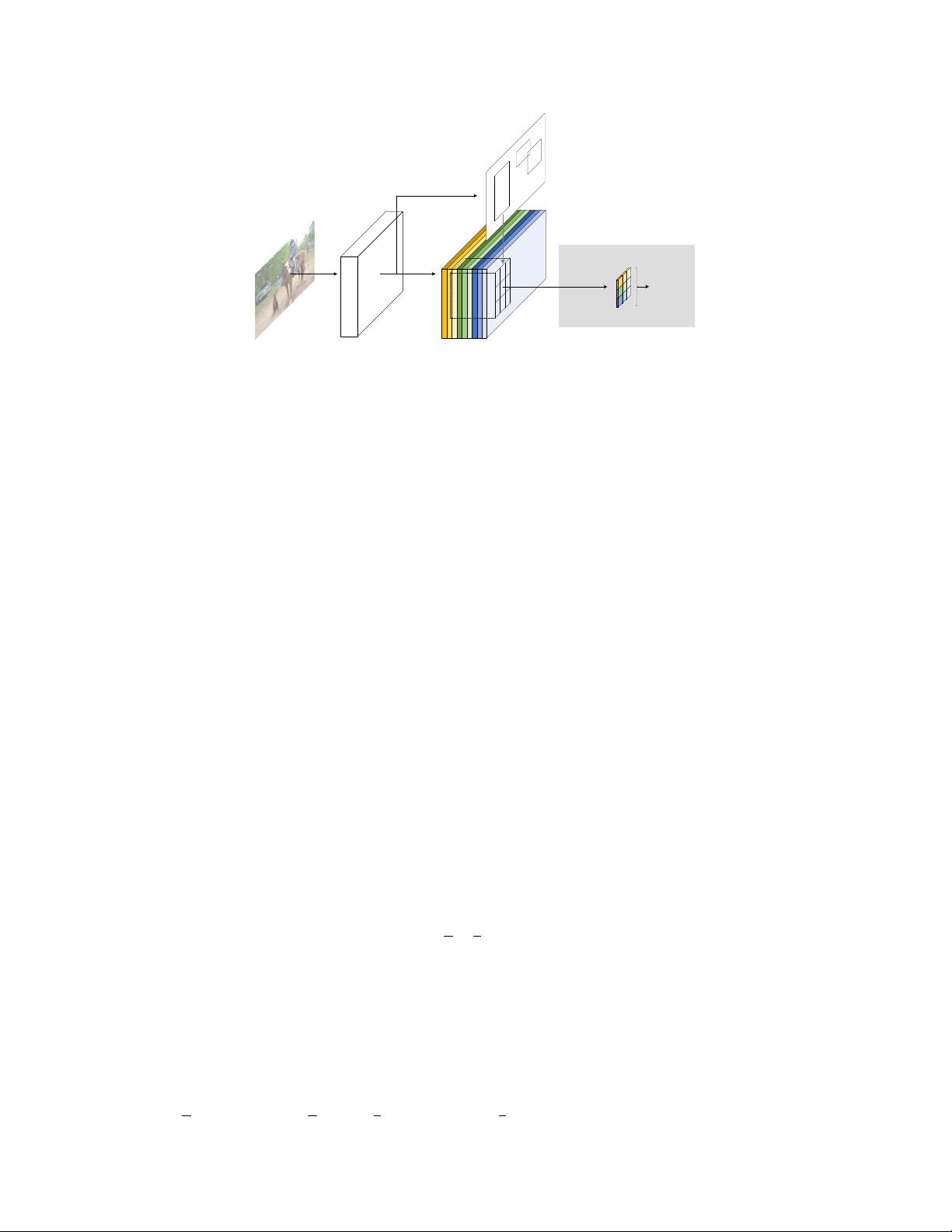
Figure 2: Overall architecture of R-FCN. A Region Proposal Network (RPN) [
18
] proposes candidate
RoIs, which are then applied on the score maps. All learnable weight layers are convolutional and are
computed on the entire image; the per-RoI computational cost is negligible.
accuracy on several benchmarks [
5
,
13
,
20
]. We extract candidate regions by the Region Proposal
Network (RPN) [
18
], which is a fully convolutional architecture in itself. Following [
18
], we share
the features between RPN and R-FCN. Figure 2 shows an overview of the system.
Given the proposal regions (RoIs), the R-FCN architecture is designed to classify the RoIs into object
categories and background. In R-FCN, all learnable weight layers are convolutional and are computed
on the entire image. The last convolutional layer produces a bank of
k
2
position-sensitive score
maps for each category, and thus has a
k
2
(C + 1)
-channel output layer with
C
object categories (
+1
for background). The bank of
k
2
score maps correspond to a
k × k
spatial grid describing relative
positions. For example, with
k × k = 3 × 3
, the 9 score maps encode the cases of {top-left, top-center,
top-right, ..., bottom-right} of an object category.
R-FCN ends with a position-sensitive RoI pooling layer. This layer aggregates the outputs of the
last convolutional layer and generates scores for each RoI. Unlike [
8
,
6
], our position-sensitive RoI
layer conducts selective pooling, and each of the
k × k
bin aggregates responses from only one score
map out of the bank of
k × k
score maps. With end-to-end training, this RoI layer shepherds the last
convolutional layer to learn specialized position-sensitive score maps. Figure 1 illustrates this idea.
Figure 3 and 4 visualize an example. The details are introduced as follows.
Backbone architecture.
The incarnation of R-FCN in this paper is based on ResNet-101 [
9
], though
other networks [
10
,
23
] are applicable. ResNet-101 has 100 convolutional layers followed by global
average pooling and a 1000-class fc layer. We remove the average pooling layer and the fc layer and
only use the convolutional layers to compute feature maps. We use the ResNet-101 released by the
authors of [
9
], pre-trained on ImageNet [
20
]. The last convolutional block in ResNet-101 is 2048-d,
and we attach a randomly initialized 1024-d 1
×
1 convolutional layer for reducing dimension (to be
precise, this increases the depth in Table 1 by 1). Then we apply the
k
2
(C + 1)
-channel convolutional
layer to generate score maps, as introduced next.
Position-sensitive score maps & Position-sensitive RoI pooling.
To explicitly encode position
information into each RoI, we divide each RoI rectangle into
k × k
bins by a regular grid. For an RoI
rectangle of a size
w × h
, a bin is of a size
≈
w
k
×
h
k
[
8
,
6
]. In our method, the last convolutional layer
is constructed to produce
k
2
score maps for each category. Inside the
(i, j)
-th bin (
0 ≤ i, j ≤ k − 1
),
we define a position-sensitive RoI pooling operation that pools only over the (i, j)-th score map:
r
c
(i, j | Θ) =
X
(x,y )∈bin(i,j)
z
i,j,c
(x + x
0
, y + y
0
| Θ)/n. (1)
Here
r
c
(i, j)
is the pooled response in the
(i, j)
-th bin for the
c
-th category,
z
i,j,c
is one score map
out of the
k
2
(C + 1)
score maps,
(x
0
, y
0
)
denotes the top-left corner of an RoI,
n
is the number
of pixels in the bin, and
Θ
denotes all learnable parameters of the network. The
(i, j)
-th bin spans
bi
w
k
c ≤ x < d(i + 1)
w
k
e
and
bj
h
k
c ≤ y < d(j + 1)
h
k
e
. The operation of Eqn.(1) is illustrated in
3
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-16 上传
2023-06-09 上传
2021-05-15 上传
2021-05-06 上传
2018-12-24 上传









