缓存双淘汰策略解决主从DB与缓存一致性问题
需积分: 14 158 浏览量
更新于2024-09-10
收藏 184KB DOCX 举报
"主从DB与cache一致性:探讨数据库主从延迟导致的缓存数据不一致问题及解决方案,包括缓存双淘汰策略"
在分布式系统中,数据一致性是一个至关重要的问题,尤其是在采用主从数据库复制和读写分离策略的情况下。主从DB与cache一致性主要关注如何避免由于数据库主从延迟或读取从库时导致的脏数据进入缓存,从而影响系统的正确性。
当系统出现“异常时序”或“读从库”情况,可能会引入脏数据到缓存中。为了解决这个问题,一种常见的方法是采用“缓存双淘汰”策略,它包括以下三种方案:
1. **Timer异步淘汰**:启动一个定时器线程,该线程会在一段时间后异步地执行第二次缓存淘汰,确保数据的最终一致性。
2. **总线异步淘汰**:利用消息总线(如Kafka或RabbitMQ)在数据库更新时发送消息,订阅这些消息的服务端接收到后进行第二次缓存淘汰。
3. **读binlog异步淘汰**:监听数据库的binlog日志,当检测到与缓存相关的写操作时,异步处理并淘汰对应的缓存条目。
数据不一致通常发生在以下两种情况:
**单库情况下的并发读写**:
在服务层并发读写数据库时,如果一个请求在写操作后因业务逻辑计算而被阻塞,另一个请求可能会在此期间读取到旧数据并将其放入缓存。这在异常时序下可能导致脏数据入缓存。
**主从同步和读写分离**:
在主从数据库架构中,读请求可能在主库写操作完成和从库同步完成之间进行,如果读请求访问了从库,就可能读取到旧数据并写入缓存。这种延迟导致的不一致是由于主从同步时间差引起的。
为了解决这些问题,有人提出先操作数据库再淘汰缓存,但这可能导致短暂的“幻读”现象,即在写操作完成后的一段时间内,其他事务仍然能读到旧数据。因此,这种方法并不理想。
优化思路通常是通过延时处理或使用上述的缓存双淘汰策略。在写请求完成后,可以等待一个预设的时间(如主从同步的平均延迟时间)再进行缓存淘汰,这样可以降低读到旧数据的概率。此外,还可以采用更高级的策略,比如基于版本号的缓存管理,或者使用乐观锁等机制,确保在并发环境下也能保持数据一致性。
确保主从DB与cache一致性是一项挑战,需要综合考虑系统架构、网络延迟和并发控制等多个因素,并采取合适的策略来最小化数据不一致的发生。
本文主要讨论这么几个问题:
(1)数据库主从延时为何会导致缓存数据不一致
(2)优化思路与方案
一、需求缘起
上一篇《缓存架构设计细节二三事》中有一个小优化点,在只有主库时,通过“串行化”的思路可以
解决缓存与数据库中数据不一致。引发大家热烈讨论的点是“在主从同步,读写分离的数据库架构下,
有可能出现脏数据入缓存的情况,此时串行化方案不再适用了”,这就是本文要讨论的主题。
二、为什么数据会不一致
为什么会读到脏数据,有这么几种情况:
(1)单库情况下,服务层的并发读写,缓存与数据库的操作交叉进行
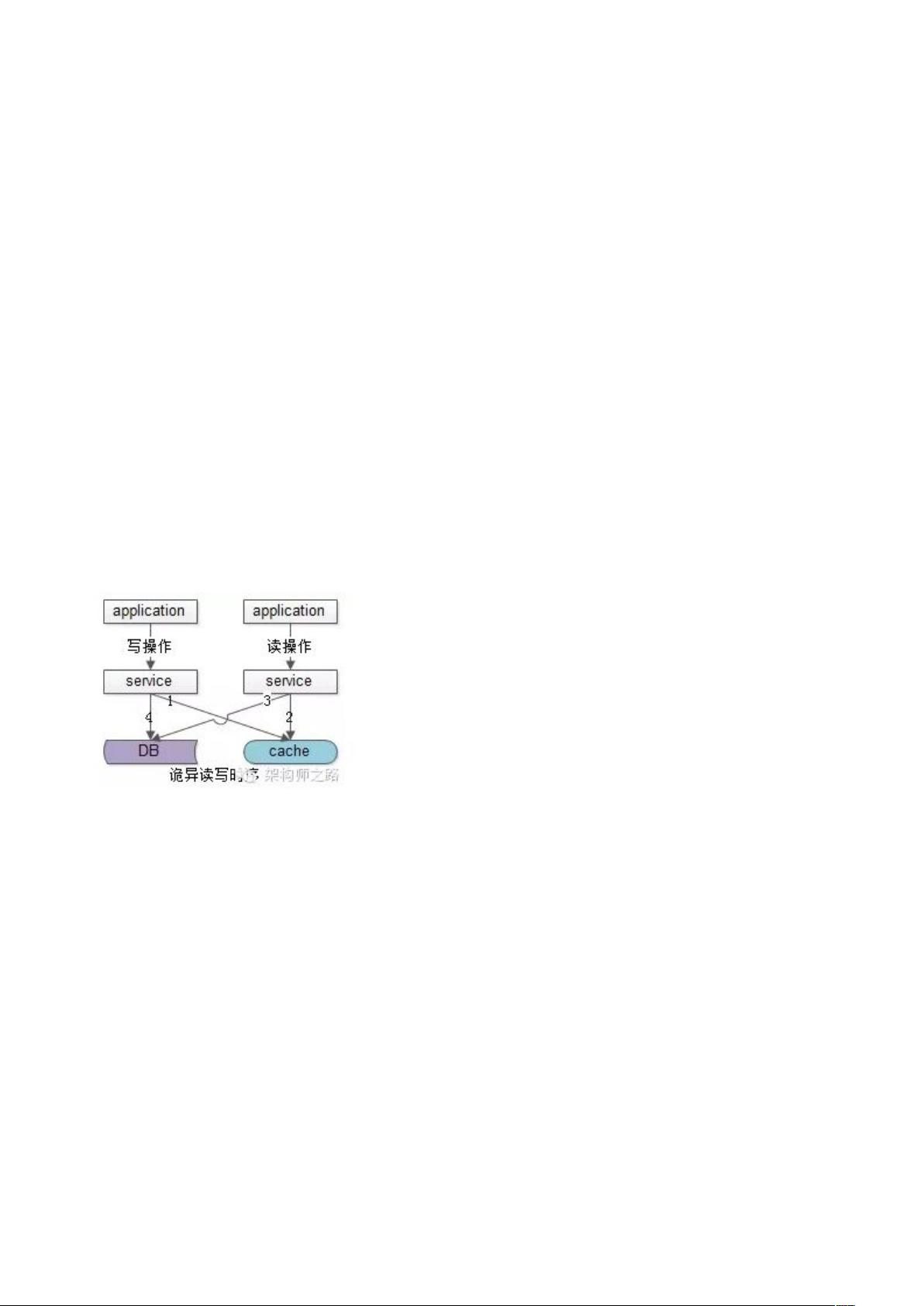
虽然只有一个 DB,在上述诡异异常时序下,也可能脏数据入缓存:
1)请求 A 发起一个写操作,第一步淘汰了 cache,然后这个请求因为各种原因在服务层卡住了
(进行大量的业务逻辑计算,例如计算了 1 秒钟),如上图步骤 1
2)请求 B 发起一个读操作,读 cache,cache miss,如上图步骤 2
3)请求 B 继续读 DB,读出来一个脏数据,然后脏数据入 cache,如上图步骤 3
4)请求 A 卡了很久后终于写数据库了,写入了最新的数据,如上图步骤 4
这种情况虽然少见,但理论上是存在的,•后发起的请求 B 在先发起的请求 A 中间完成了。
(2)主从同步,读写分离的情况下,读从库读到旧数据
下载后可阅读完整内容,剩余4页未读,立即下载
2017-03-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

hyy80688
- 粉丝: 10
- 资源: 202
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
