Linux块IO:多队列SSD访问在多核系统上的引入
需积分: 38 29 浏览量
更新于2024-09-10
1
收藏 359KB PDF 举报
"这篇技术文章探讨了Linux操作系统中块I/O在多核系统上处理固态硬盘(SSD)访问的挑战与优化。作者Matias Bjørling、Jens Axboe、David Nellans和Philippe Bonnet分别来自哥本哈根信息技术大学和Fusion-io公司,他们分析了随着存储设备I/O性能的飞速提升,尤其是由于NAND闪存设备的数据并行设计,原有的块层架构已经成为了系统整体性能的瓶颈,尤其是在高NUMA(Non-Uniform Memory Access,非一致内存访问)因素的处理器系统中。文章提出了新一代的块层设计,旨在应对多核系统中配备单个存储设备时的千万级IOPS处理需求,并展示了该设计在核心数量增加,甚至是多插槽NUMA系统上的良好扩展性。"
文章详细讨论了以下几个关键知识点:
1. **存储设备的性能演变**:过去五年间,存储设备的I/O操作每秒(IOPS)性能从数百跃升至数十万,预计未来五年将进一步提升到数千万。这种增长主要归功于NAND闪存技术的发展,其数据并行设计显著提升了读写速度。
2. **块I/O层的瓶颈**:传统的Linux块I/O层最初设计用于处理数千IOPS,但在如今的高性能存储设备面前,这个层次已经成为限制整体存储系统性能的关键因素,特别是在那些具有高NUMA特性的多核系统中。
3. **NUMA系统的影响**:NUMA架构在多核系统中,不同核心访问内存的速度和延迟不一致,这会加剧块I/O层的性能问题,尤其是在处理高速SSD时。
4. **新一代块层设计**:作者提出了一个能够处理千万级别IOPS的新一代块层设计,该设计专为多核系统中的单一存储设备优化,旨在打破现有的性能限制。
5. **扩展性和性能**:实验结果表明,这个新设计可以随着核心数量的增加优雅地扩展,即使在有多个处理器插槽的NUMA系统中,仍能保持良好的性能表现。
6. **分类与主题**:根据文章的类别和主题描述,可以将其归类为计算机系统组织下的I/O系统和存储体系结构领域,特别是关注多核系统和高IOPS环境下的优化问题。
通过这些改进,Linux操作系统将更好地适应高性能存储设备的需求,提升数据中心和服务器的存储性能,尤其是在大规模并行处理和大数据应用中。
Linux Block IO: Introducing Multi-queue SSD Access on
Multi-core Systems
Matias Bjørling
*†
Jens Axboe
†
David Nellans
†
Philippe Bonnet
*
*
IT University of Copenhagen
{mabj,phbo}@itu.dk
†
Fusion-io
{jaxboe,dnellans}@fusionio.com
ABSTRACT
The IO performance of storage devices has accelerated from
hundreds of IOPS five years ago, to hundreds of thousands
of IOPS today, and tens of millions of IOPS projected in five
years. This sharp evolution is primarily due to the introduc-
tion of NAND-flash devices and their data parallel design. In
this work, we demonstrate that the block layer within the
operating system, originally designed to handle thousands
of IOPS, has become a bottleneck to overall storage system
performance, specially on the high NUMA-factor processors
systems that are becoming commonplace. We describe the
design of a next generation block layer that is capable of
handling tens of millions of IOPS on a multi-core system
equipped with a single storage device. Our experiments
show that our design scales graciously with the number of
cores, even on NUMA systems with multiple sockets.
Categories and Subject Descriptors
D.4.2 [Operating System]: Storage Management—Sec-
ondary storage; D.4.8 [Operating System]: Performance—
measurements
General Terms
Design, Experimentation, Measurement, Performance.
Keywords
Linux, Block Layer, Solid State Drives, Non-volatile Mem-
ory, Latency, Throughput.
1 Introduction
As long as secondary storage has been synonymous with
hard disk drives (HDD), IO latency and throughput have
been shaped by the physical characteristics of rotational de-
vices: Random accesses that require disk head movement
are slow and sequential accesses that only require rotation
of the disk platter are fast. Generations of IO intensive al-
gorithms and systems have been designed based on these
two fundamental characteristics. Today, the advent of solid
state disks (SSD) based on non-volatile memories (NVM)
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage and that copies
bear this notice and the full citation on the first page. To copy otherwise, to
republish, to post on servers or to redistribute to lists, requires prior specific
permission and/or a fee.
SYSTOR ’13 June 30 - July 02 2013, Haifa, Israel
Copyright 2013 ACM 978-1-4503-2116-7/13/06 ...$15.00.
2012
2011
2010
4K Read IOPS
0
200k
400k
600k
800k
1M
785000
608000
498000
90000
60000
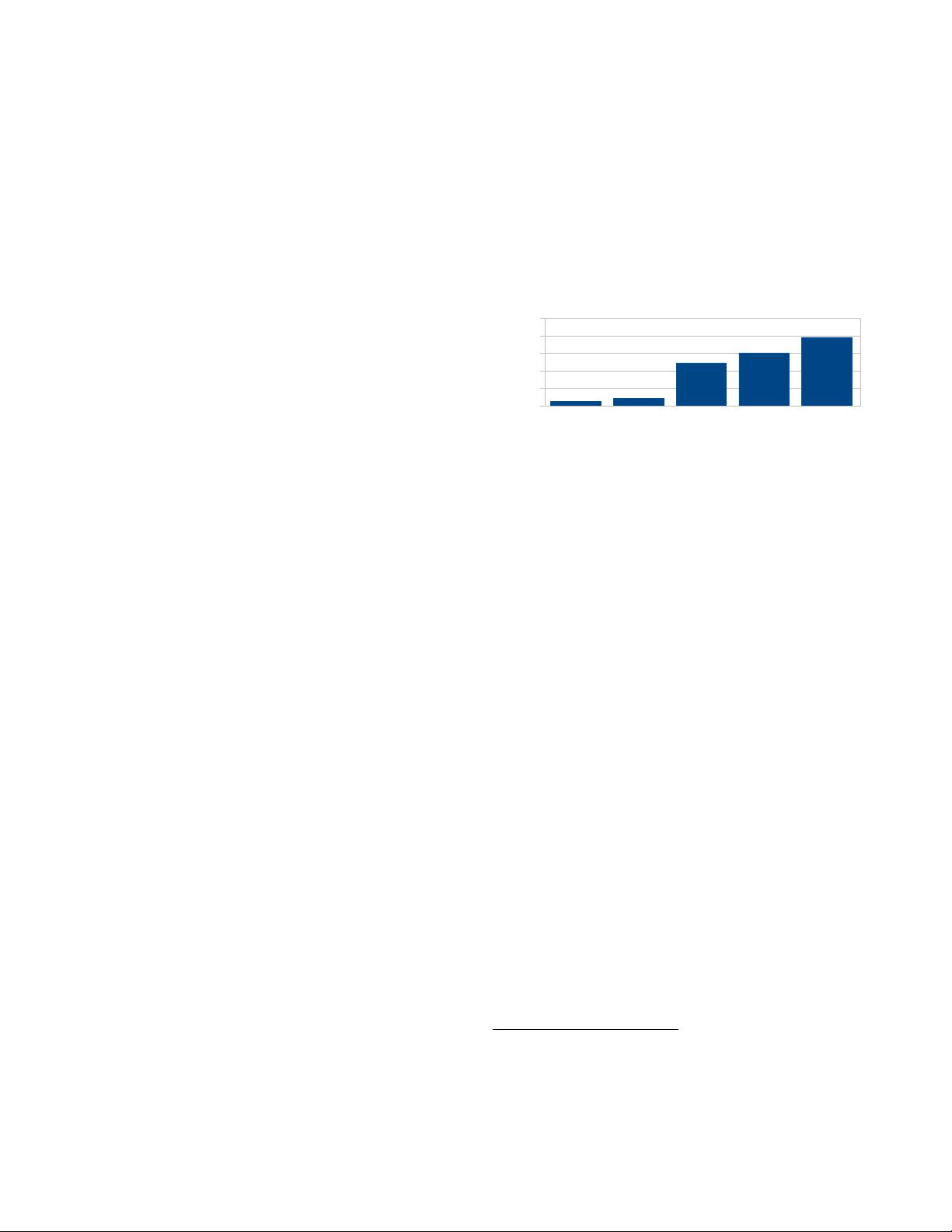
SSD 1 SSD 2 SSD 3 SSD 4 SSD 5
Figure 1: IOPS for 4K random read for five SSD
devices.
(e.g., flash or phase-change memory [11, 6]) is transforming
the performance characteristics of secondary storage. SSDs
often exhibit little latency difference between sequential and
random IOs [16]. IO latency for SSDs is in the order of tens
of microseconds as opposed to tens of milliseconds for HDDs.
Large internal data parallelism in SSDs disks enables many
concurrent IO operations which, in turn, allows single de-
vices to achieve close to a million IOs per second (IOPS)
for random accesses, as opposed to just hundreds on tradi-
tional magnetic hard drives. In Figure 1, we illustrate the
evolution of SSD performance over the last couple of years.
A similar, albeit slower, performance transformation has
already been witnessed for network systems. Ethernet speed
evolved steadily from 10 Mb/s in the early 1990s to 100 Gb/s
in 2010. Such a regular evolution over a 20 years period has
allowed for a smooth transition between lab prototypes and
mainstream deployments over time. For storage, the rate of
change is much faster. We have seen a 10,000x improvement
over just a few years. The throughput of modern storage de-
vices is now often limited by their hardware (i.e., SATA/SAS
or PCI-E) and software interfaces [28, 26]. Such rapid leaps
in hardware performance have exposed previously unnoticed
bottlenecks at the software level, both in the operating sys-
tem and application layers. Today, with Linux, a single
CPU core can sustain an IO submission rate of around 800
thousand IOPS. Regardless of how many cores are used to
submit IOs, the operating system block layer can not scale
up to over one million IOPS. This may be fast enough for
today’s SSDs - but not for tomorrow’s.
We can expect that (a) SSDs are going to get faster, by
increasing their internal parallelism
1
[9, 8] and (b) CPU
1
If we look at the performance of NAND-flash chips, access
times are getting slower, not faster, in timings [17]. Access
time, for individual flash chips, increases with shrinking fea-
ture size, and increasing number of dies per package. The
decrease in individual chip performance is compensated by
improved parallelism within and across chips.
下载后可阅读完整内容,剩余9页未读,立即下载
2021-02-09 上传
2021-05-23 上传
2021-05-23 上传
2021-05-23 上传
2021-05-23 上传
2021-05-23 上传
2021-05-23 上传
2021-05-23 上传

老猫望月
- 粉丝: 1
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
