数据库索引原理与类型解析
40 浏览量
更新于2024-09-04
收藏 736KB PDF 举报
"数据库索引是提升数据检索速度的关键数据结构,主要分为聚集索引、非聚集索引等类型,采用如B+树或哈希等底层实现方式。创建索引能确保数据唯一性,加快检索速度,减少磁盘IO,优化系统性能,但也会带来额外的维护成本和空间占用。"
在数据库管理系统中,索引是一种关键的优化工具,它允许快速访问和检索数据。索引的本质是对表中一列或多列数据的排序结构,使得数据库系统能够迅速找到所需的数据行,从而大大提高查询性能。
1、索引的概述
索引(Index)是数据库为了加速数据查询而创建的数据结构。它使得数据库不再需要逐行扫描整个表来满足查询请求,而是可以直接定位到所需的数据。创建索引有诸多优点,包括保证数据的唯一性、提升检索速度、减少磁盘I/O操作、优化查询性能以及加速表间连接。然而,创建和维护索引也会带来额外的时间开销,并占用存储空间,且在数据更新时需要同步维护索引,这可能降低数据维护的速度。
2、索引的种类
索引的种类多样,常见的包括普通索引(非唯一索引)、主键索引(通常也是聚集索引,不允许NULL且数据唯一)、唯一索引(数据唯一,可含NULL)、组合索引(多列联合索引)以及全文索引(用于全文搜索)。不同数据库系统支持不同的索引类型,例如MySQL的InnoDB存储引擎使用B+树实现聚集索引,MyISAM则不支持聚集索引。
3、索引的底层实现原理
索引的底层实现通常基于两种主要的数据结构:B+树和哈希表。B+树是一种平衡的多路搜索树,适用于范围查询和有序数据的检索,其特点是所有叶子节点在同一层,且每个节点包含多个键值和指向子节点的指针。在MySQL中,InnoDB的索引使用B+树,每个数据页都有页目录,方便快速定位记录。而哈希索引则依赖于哈希函数,适用于等值查询,因为哈希查找通常能在常数时间内完成,但不支持范围查询。
4、聚集索引与非聚集索引
聚集索引(Clustered Index)的叶子节点直接存储了完整的数据行,数据行的物理顺序与索引顺序相同。而非聚集索引(Non-Clustered Index)的叶子节点存储的是指向数据行的指针,索引顺序与数据行的物理顺序可能不同。覆盖索引是指查询只需要从索引中就可以获取所有需要的数据,无需回表查询实际的数据行。
5、索引的最左匹配原则
在多列索引中,数据库查询优化器会遵循最左匹配原则,从左至右依次匹配索引中的列。如果查询条件不包含索引的最左侧列,那么该索引可能无法被充分利用。
6、总结
索引在数据库性能优化中扮演着至关重要的角色,选择合适的索引类型和结构,以及明智地管理索引,是数据库管理员必须掌握的技能。然而,索引并非万能解决方案,过度依赖索引也可能导致性能问题,因此在设计数据库时需要权衡利弊,根据具体的应用场景和数据访问模式来创建和使用索引。
数据库数据库 索引索引
数据库数据库 索引索引
文章目录文章目录数据库 索引1、概述2、索引的种类3、索引的底层实现原理3.1 索引的基础知识3.1 索引提高检索速度3.3 哈希索引4、聚集索引与非聚集索引4.1 聚集索引4.2 非聚集索引4.3
覆盖索引5、索引的最左分配原则6、总结
1、概述、概述
1.1 什么是索引什么是索引
索引(Index)是帮助MySQL高效获取数据的数据结构。
1.2 创建索引的优点创建索引的优点
(1)创建唯一性索引,保证数据库表中每一行数据的唯一性。
(2)加快数据的检索速度,这也是创建索引的最主要的原因加快数据的检索速度,这也是创建索引的最主要的原因。
(3)减少磁盘减少磁盘IO(向字典一样可以直接定位)。
(4)通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
(5)加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
1.3 数据库中创建索引的缺点数据库中创建索引的缺点
(1)创建索引和维护索引要耗费时间创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
(2)索引需要占用物理空间索引需要占用物理空间,特别是聚集索引,需要较大的空间。
(3)当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度
2、索引的种类、索引的种类
索引是关系型数据库中给数据库表中一列或多列的值排序后的存储结构,SQL的主流索引结构有B+树以及Hash结构,聚集索引以及非聚集索引用的是B+树索引。这篇文章会总结
SQL Server以及MySQL的InnoDB和MyISAM两种SQL的索引。
SQL Sever索引类型有:唯一索引,主键索引,聚集索引,非聚集索引。
MySQL 索引类型有:唯一索引,主键(聚集)索引,非聚集索引,全文索引。
(1)普通索引
使用字段关键字建立的索引,主要是提高查询速度
(2)主键索引
数据记录里面不能有 null,数据内容不能重复,在一张表里面只能有一个主键索引。
(3)组合索引
多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
(4)唯一索引
字段数据是唯一的,数据内容里面能否为 null,在一张表里面,是可
以添加多个唯一索引
(5)全文索引
对文本的内容进行分词,进行搜索。
3、索引的底层实现原理、索引的底层实现原理
3.1 索引的基础知识索引的基础知识
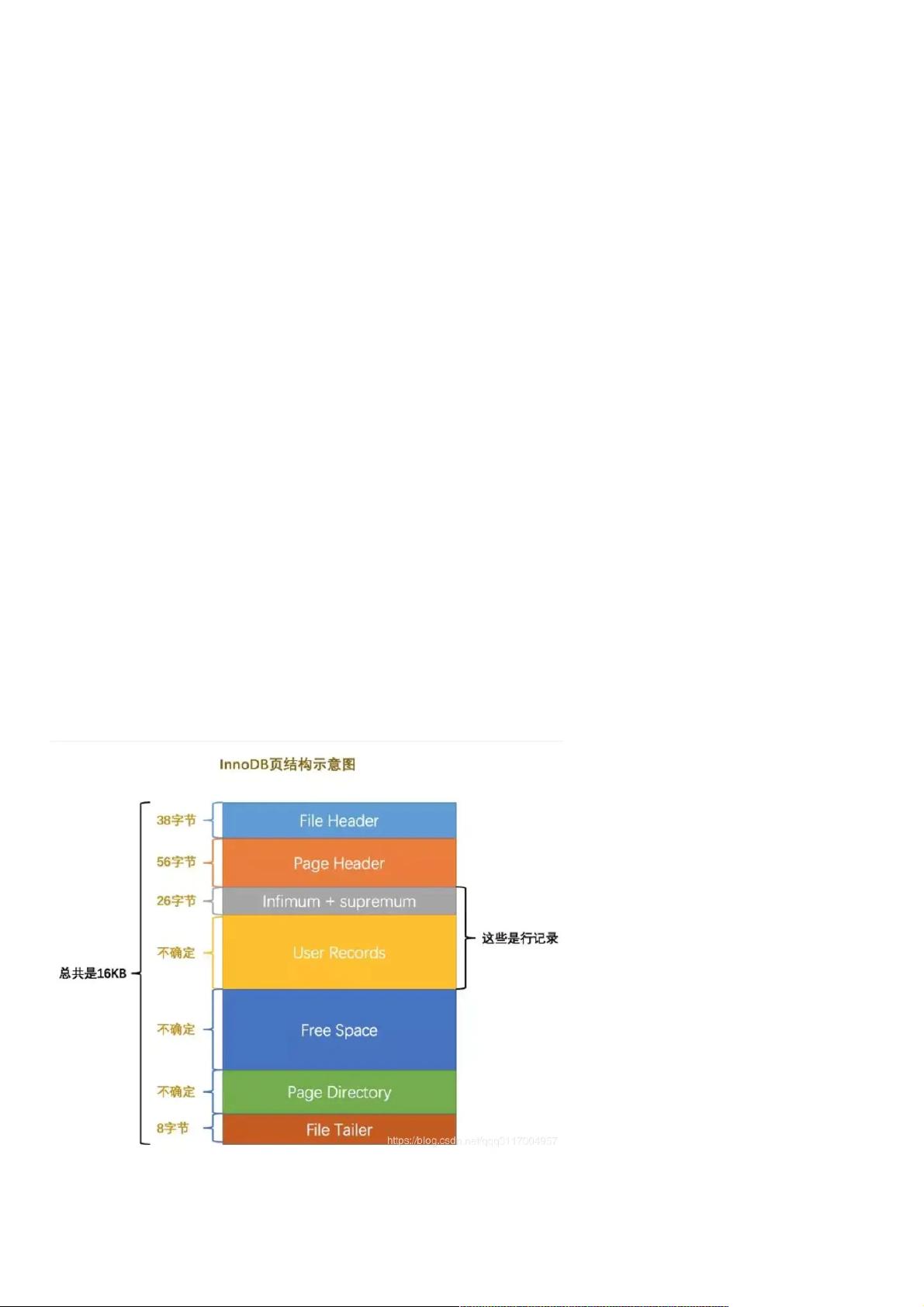
首先Mysql的基本存储结构是页(记录都存在页里边):
下载后可阅读完整内容,剩余4页未读,立即下载
2018-06-24 上传
2018-02-01 上传
2013-04-17 上传
2010-09-13 上传
2020-12-15 上传
2008-03-24 上传

weixin_38690079
- 粉丝: 2
- 资源: 950
 我的内容管理
展开
我的内容管理
展开







最新资源
- 实现在Sparton-3E板卡上的按键及开关的控制.7z
- 假设检验【实验代码+实验报告】
- cookbook:一个使用Ruby MVC表示食谱的简单应用
- ODE for Java-开源
- 三重数字
- IGSI-Game-Jam-2021:游戏Jam IGSI Tahun 2021,Tema非常规武器
- react:React练习
- 线下学习系列图标下载
- Github
- 汽车主动悬架控制.zip
- lagrange插值多项式和Newton插值多项式【三个实验代码加一个实验报告】
- suffix-automaton-vis:交互式应用程序,用于可视化如何构建后缀自动机O(n)
- i18n:Dojo 2-国际化图书馆
- Api-node-express-mariadb
- Intangible-capital-stocks:无形资本积累的参数和无形库存数据(Ewens,Peters和Wang(2020))
- speedbumps:小麻烦的收集
