Transformer模型:注意力即一切
64 浏览量
更新于2024-06-18
收藏 2.06MB PDF 举报
"Transformer模型与传统序列转录方法的革新"
在深度学习领域,尤其是在自然语言处理(NLP)中,"Attention Is All You Need" 是一篇由 Ashish Vaswani、Noam Shazeer、Niki Parmar 等人于 Google Brain 和 Google Research 联合发表的重要论文。这篇论文标志着Transformer架构的诞生,它对传统的序列转录模型提出了革命性的变革。
传统的方法通常依赖于复杂的循环神经网络(RNNs)或卷积神经网络(CNNs),它们由编码器和解码器组成,通过长短期记忆(LSTM)单元或类似的递归结构处理序列数据。这些模型的性能优秀,但存在两个主要限制:一是计算复杂度高,因为它们需要逐时间步处理,限制了并行化;二是训练时间较长,因为每个时间步都需要前向传播和反向传播。
论文提出的新模型Transformer,摒弃了RNNs和CNNs中的递归和卷积层,完全依赖于自注意力机制(self-attention)。自注意力允许模型在处理每个输入元素时,同时考虑所有其他元素的信息,极大地提高了模型对全局上下文的理解。这不仅简化了模型结构,降低了模型间的依赖关系,还显著提高了并行计算能力,使得大规模训练变得更加高效。
在机器翻译任务上,如WMT2014 English-to-German的比赛,Transformer模型展现了卓越的质量,达到了28.4 BLEU分的成绩,这在当时是前所未有的,并且超越了当时的最优结果。这一突破证明了注意力机制在处理序列数据时的强大潜力,使得模型能够在保持高性能的同时,显著提升计算效率和训练速度。
Transformer的成功引起了广泛的关注,后续的研究者们在此基础上发展出了许多变体,如多头注意力、位置编码等,进一步推动了自然语言处理领域的进步。如今,Transformer已经成为现代NLP的基石,广泛应用于文本分类、文本生成、对话系统等任务中,成为了深度学习的标准工具之一。其简洁的结构和强大的性能使之成为解决序列建模问题的理想选择。"
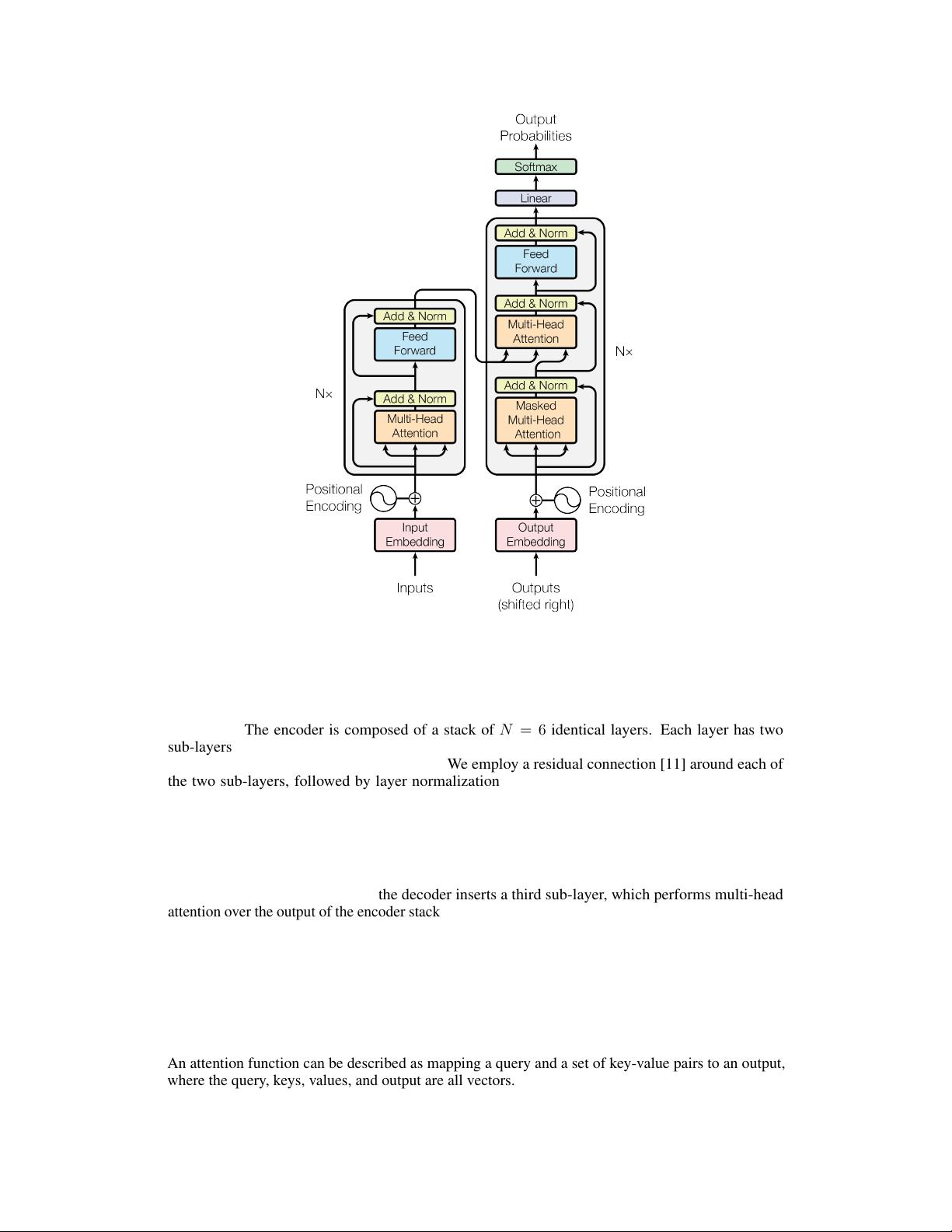
Figure 1: The Transformer - model architecture.
3.1 Encoder and Decoder Stacks
Encoder:
The encoder is composed of a stack of
N = 6
identical layers. Each layer has two
sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-
wise fully connected feed-forward network. We employ a residual connection [
11
] around each of
the two sub-layers, followed by layer normalization [
1
]. That is, the output of each sub-layer is
LayerNorm(x + Sublayer(x))
, where
Sublayer(x)
is the function implemented by the sub-layer
itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding
layers, produce outputs of dimension d
model
= 512.
Decoder:
The decoder is also composed of a stack of
N = 6
identical layers. In addition to the two
sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head
attention over the output of the encoder stack. Similar to the encoder, we employ residual connections
around each of the sub-layers, followed by layer normalization. We also modify the self-attention
sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This
masking, combined with fact that the output embeddings are offset by one position, ensures that the
predictions for position i can depend only on the known outputs at positions less than i.
3.2 Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output,
where the query, keys, values, and output are all vectors. The output is computed as a weighted sum
of the values, where the weight assigned to each value is computed by a compatibility function of the
query with the corresponding key.
3
encode包括N=6个完全相同的layer,每个layer有两个sub-layer:即multi-head
self-attention、fully connected feed-forward network。
对这两个sub-layer都执行残差连接,随后都有一个normalization layer。
残差连接
skip
connection
decode与encode相比,插入了第三个sub-layer,以对
encode的输出执行multi-head attention
这个masking,加上输出嵌入
被一个位置偏移的事实,确
保了位置i的预测只能依赖于
位置i以前的已知输出。
剩余14页未读,继续阅读
2019-02-26 上传
2024-09-15 上传
2023-07-25 上传
2024-06-27 上传
2024-03-08 上传

lucky_chaichai
- 粉丝: 7113
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源数据结构:全球开源项目中使用的数据结构
- quiron:Modulo QtQuick para cargar en Unik Qml Engine-Modulo deaplicaciónpara Ayuda Memoria de DatosAstrológicos
- accyrding-policy-aloha.zip_TreeView控件_Visual_Basic_
- LogKyrcach
- 算法和数据结构:使用JavaScript实现的常见排序算法,数据结构和其他算法挑战的交互式概述
- led发光管(PE).rar_嵌入式/单片机/硬件编程_C/C++_
- 用于读取和写入图像数据的Python库-Python开发
- 第十三届中国大学生服务外包创新创业大赛-A08基于 FPGA 的铝片表面工业缺陷检测系统
- gdxextras:Libgdx的一些额外工具
- clean-undefined:删除未定义的对象字段
- Women-in-Big-Data-South-Africa:本笔记本介绍了Zindi竞赛(南非大数据中的女性-南非女性为户主的家庭)。 我们将快速浏览数据,展示如何创建模型,估算您在Zindi上获得的得分,准备提交并进入排行榜。 我还提供了一些有关如何获得更高分数的提示-一旦您第一次提交,这些都可能给您一些下一步尝试的想法
- 正方教务通用安卓
- libradio-开源
- 数据结构算法:此存储库包括我在本科期间所做的数据结构程序和算法。 这些是我自己用C ++从头开始编写的功能齐全的算法。 -要求:Microsoft Visual Studio 2019-打开sln文件以打开整个项目
- lilt:Lilt终端模拟器-用于Linux,macOS和其他类似Unix的系统的简单便携式终端模拟器
- siptapi-开源
