PCA与K-近邻:手写数字识别代码详解与实践
需积分: 9 179 浏览量
更新于2024-08-04
收藏 273KB PDF 举报
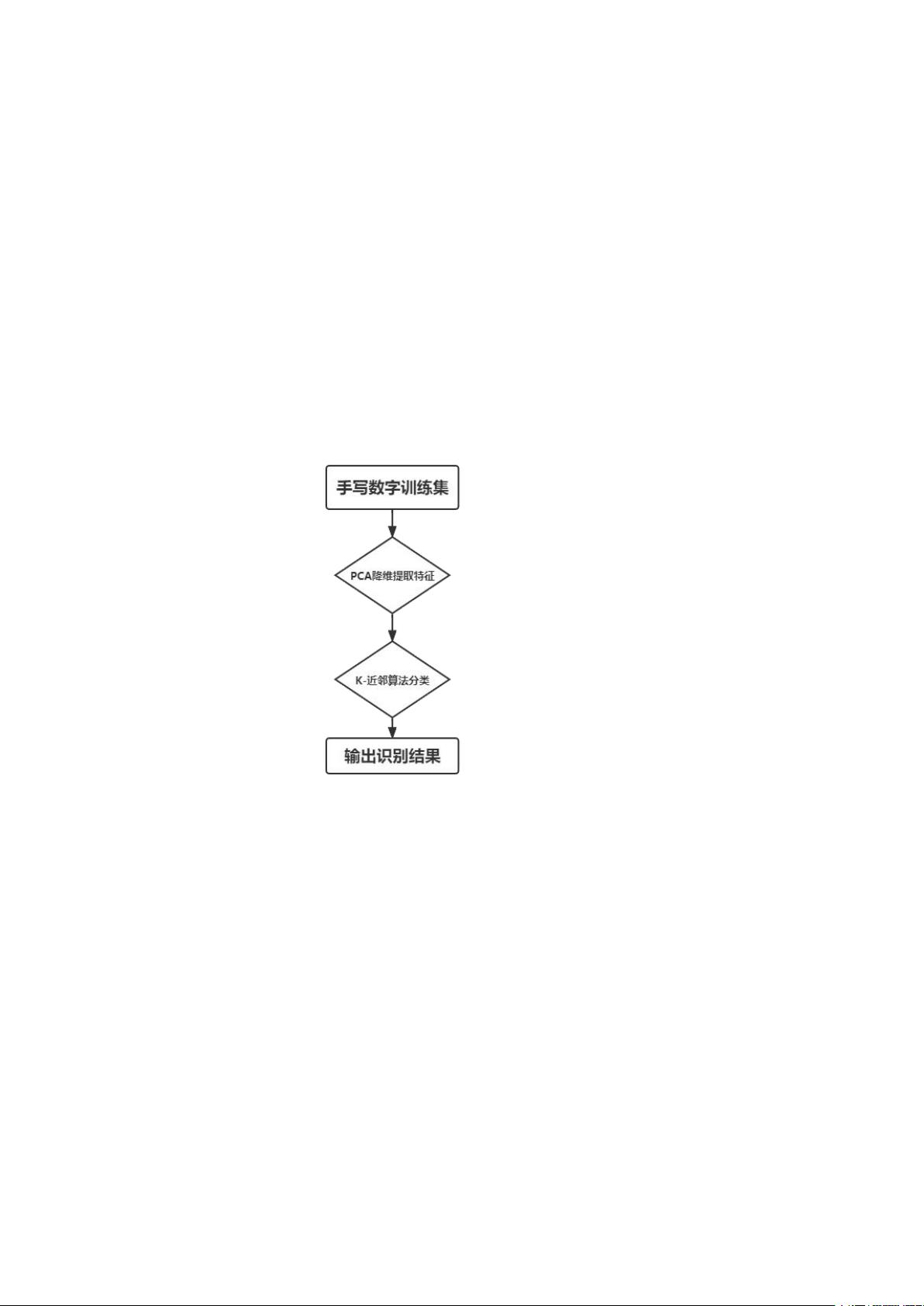
本文档详细介绍了基于PCA(主成分分析)与K-近邻算法的手写数字识别系统的设计与实现。首先,研究内容聚焦于解决手写识别中的问题,由于手写体的个性化和多样性,使得计算机在识别时面临挑战。本项目旨在开发一个系统,通过PCA特征提取减少数据维度,并利用K-近邻算法进行精确分类。
系统设计的基础包括硬件环境,如高性能的Intel酷睿i7处理器、华硕主板、内存、固态硬盘、显卡等,以及软件环境,如使用Spyder集成的Python 3.9环境。实验使用了scikit-learn这个流行的Python机器学习库,它提供了PCA算法和KNN等工具,便于实现算法操作。
数据集方面,scikit-learn自带的手写数字识别数据集包含1797个训练样本,每张图片原始尺寸为8*8像素。特征提取是关键步骤,通过PCA算法,先将图片数据转化为矩阵,然后进行零均值化处理,接着计算协方差矩阵,提取出主成分特征。最后,降维后的数据被用于后续的分类过程。
分类过程依赖于K-近邻算法,对于每个测试样本,会计算其与训练样本之间的距离,选择最近的K个样本作为邻居,根据这些邻居的类别进行预测。这种方法简单直观,但计算量可能会随着数据集增大而增加。
这份文档提供了一个完整的实践案例,展示了如何结合PCA的降维技术和K-近邻算法进行手写数字识别,对于理解和实现此类机器学习项目具有很高的参考价值。
基于
PCA
与
K-
近邻算法手写数字识别系
统的设计与实现
1.题目的主要研究内容
(1)手写识别是常见的图像识别任务。计算机通过手写体图片来识别出图
片中的字,与印刷字体不同的是,不同人的手写体风格迥异,大小不一, 造成
了计算机对手写识别任务的一些困难。 本实验主要研究数字手写体识别方法,
基于 PCA 特征提取并试用了 K-近邻算法去对数据进行识别。
(2)系统流程图
2. 题目研究的工作基础或实验条件
(1)硬件环境 CPU Intel 酷睿 i7 10700K 、主板华硕 PRIME Z490-P 1 、内
存 金 士 顿 16GB DDR5 3200MHz 、 固 态 硬 盘 三 星 970 EVO Plus NVMe M.2
(500GB)、显卡 NVIDIA GeForce RTX 2060 SUPER Founders Edition 、华硕玩
家国度 ROG 、电源华硕 ROG、散热器华硕 ROG STRIX LC 、显示器三星
C27H711QEC、光驱华硕 SDRW-08D2S-U
(2)软件环境 Spyder 内置 Python3.9
3. 数据集描述
scikit-learn 是一个开源的 Python 机器学习工具包,拥有 PCA 算法、LDA 算
法和 KNN 等一系列基本算法的底层代码,运用其我们可以很轻易地实现我们想
下载后可阅读完整内容,剩余4页未读,立即下载
153 浏览量
2017-12-14 上传
2022-11-04 上传
2021-09-23 上传
2018-03-07 上传
2019-07-25 上传
2021-09-23 上传
2020-05-19 上传
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
