马尔科夫决策过程详解:构成、稳态与无限步数MDP策略
需积分: 0 81 浏览量
更新于2024-08-05
收藏 680KB PDF 举报
本篇文档是关于智能系统设计与应用的课后练习参考答案,主要涉及马尔科夫决策过程(Markov Decision Process, MDP)的相关概念和问题解答。马尔科夫假设的核心在于状态转移只依赖当前状态和上一步的行动,而不考虑过去的历史。一个完整的MDP包含四个基本元素:
1. 状态集合S:代表所有可能的状态,如文中提到的"high"、"low"等,对于吸尘机器人来说可能代表清扫或待机状态。
2. 行动集合A:表示在每个状态下可以选择的动作,如吸尘机器人的问题中,可能是"search"(搜索)、"wait"(等待)和"recharge"(充电)。
3. 转移函数T(s′|s,a):描述了在执行某个动作a后,从状态s转移到下一个状态s'的概率分布。
4. 奖励函数R(s,a):给出了在执行某个动作a时,在当前状态s获得的即时回报。
稳态MDP 是指转移函数和奖励函数不随时间变化的MDP,它可以通过决策网络表示,如图1所示,其中每个节点代表一个状态,边上的箭头和权重表示了状态转移的概率和奖励。
问题2探讨的是无限步数MDP中的策略选择,根据折扣因子γ的不同,确定性策略πleft和πright的优劣。当γ=0时,没有未来奖励的影响,所以总是选择左行动为最优;当γ=0.5时,两个策略都同样好;而当γ=0.9时,右行动由于其长远考虑的特性变得更优。
问题3涉及计算吸尘机器人的最优状态值函数,即贝尔曼最优方程。对于high和low两种状态,分别求解最优状态值,这涉及到动态规划的过程,通过迭代更新状态值,直到达到最优解。贝尔曼方程给出了状态价值函数的递归定义,涉及了概率转移和奖励的加权平均。
本文档提供了对马尔科夫决策过程基础理论和具体应用实例的深入解析,对于理解和设计依赖状态转移和决策策略的智能系统具有重要的参考价值。
刘旭辉 智能系统设计与应用 Homework 4-6 Problem 3 (continued)
数的Bellman最优方程.
Solution
两个状态的Bellman最优值函数可分别表示为:
v
∗
(h) = max
p(h|h, s) [r(h, s, h) + γv
∗
(h)] + p(1|h, s) [r(h, s, 1) + γv
∗
(1)]
p(h|h, w ) [r(h, w, h) + γv
∗
(h)] + p(1|h, w ) [r(h, w , 1) + γv
∗
(1)]
= max
α [r
s
+ γv
∗
(h)] + (1 − α) [r
s
+ γv
∗
(1)]
1 [r
w
+ γv
∗
(h)] + 0 [r
w
+ γv
∗
(1)]
= max
r
s
+ γ [αv
∗
(h) + (1 − α)v
∗
(1)]
r
w
+ γv
∗
(h)
v
∗
(l) = max
βr
s
− 3(1 − β) + γ [(1 − β)v
∗
(h) + βv
∗
(1)]
r
w
+ γv
∗
(l)
γv
∗
(h)
Bellman最优方程由具体的r
s
, r
w
, α, β, γ的值确定.
Problem 4
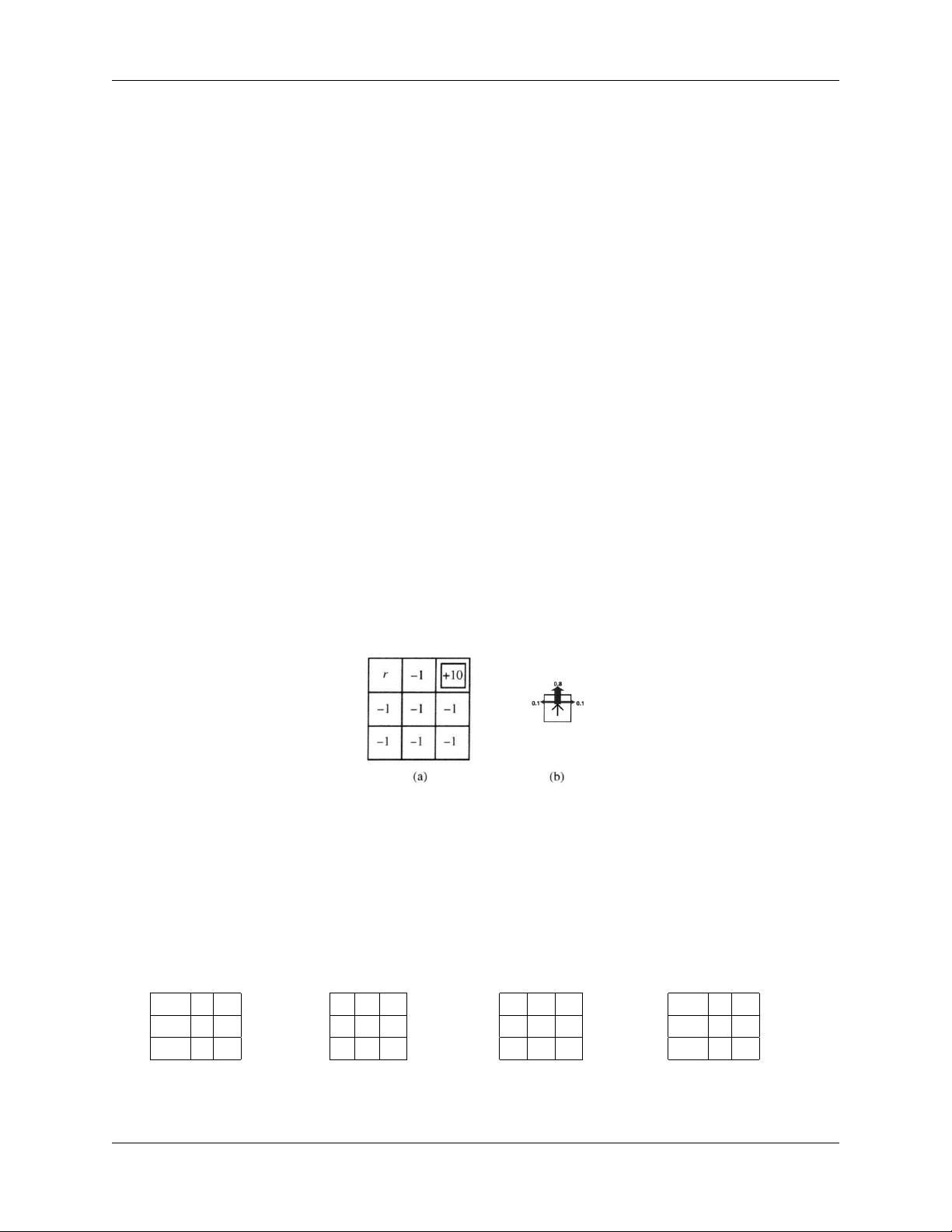
考虑图3(a)中的3×3世界,每个格子中的数值表示的是R(s),即状态s的立即奖赏,右上角含有+10的
格子是终止状态(进入终止状态得到+10的奖赏后, 采取任意行动都会导致情节结束). 转移模型如
图3(b)所示, 它表 示的含义是,以0.8的概率向选择的方向移动,各以0.1的概率向与它垂直的两个方 向
移动. 假设Agent的可选行动为上(U), 下(D), 左(L), 右(R),使用折扣因子为0.99的折扣奖赏定义效用(即
回报). 对于下面的每种情况,计算最优策略.
图 3: 3x3网格世界及其转移模型
1. r = 100
2. r = −3
3. r = 0
4. r = 3
Solution
u/l l .
u l d
u l l
r = 100时的最优策略
r r .
r r u
r r u
r = −3时的最优策略
r r .
u u u
u u u
r = 0时的最优策略
u/l l .
u l d
u l l
r = 3时的最优策略
3
剩余12页未读,继续阅读
2022-08-03 上传
2022-03-11 上传
119 浏览量
2022-02-15 上传
2011-12-05 上传
125 浏览量
2021-10-06 上传
2023-04-01 上传
2022-08-03 上传

行走的瓶子Yolo
- 粉丝: 36
- 资源: 342
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
