Hadoop2.x详尽安装指南:从本地到高可用
"最详细的Hadoop环境搭建"
在大数据领域,Hadoop扮演着核心角色,它为海量数据的存储和处理提供了可靠且可扩展的解决方案。本文以安装部署Apache Hadoop 2.x版本为主线,深入浅出地介绍了Hadoop的基础知识、架构组成、模块协同工作原理和技术细节。通过实际操作来理解Hadoop,对于初学者而言,这是一个非常实用的学习路径。
首先,文章指出Hadoop的安装不应仅仅被视为技术操作,而是理解Hadoop工作原理的重要途径。为了搭建Hadoop环境,首先需要准备一个Linux操作系统,因为Hadoop主要在Linux环境下运行。Linux环境的安装包括操作系统的选择、配置以及Java JDK的安装,这些都是Hadoop运行的必备条件。
在第二部分,文章简要介绍了Hadoop的本地模式安装,这是针对开发者快速验证代码或初次接触Hadoop时的简单配置。本地模式下,所有Hadoop组件都在单个Java进程中运行,不涉及分布式概念。
第三部分,文章详细讲解了Hadoop的伪分布式模式。在这一模式下,Hadoop的所有组件在一台机器的不同进程中运行,尽管看似分布式,但实际仍运行在同一操作系统内。这是学习Hadoop常用的一种方式,因为它能在单机上模拟分布式环境,方便理解各组件间的关系和交互。
第四部分,文章转向完全分布式安装,这是实际生产环境中的配置。在这种模式下,Hadoop运行在多台服务器组成的集群上,以提供更高的可用性和容错性。在分布式环境中,通常还需要解决单点故障问题,这就引出了第五部分——Hadoop的高可用性(HA)配置。
高可用性配置旨在确保即使某个组件出现故障,系统也能继续运行。在Hadoop 2.x中,HA主要通过NameNode的热备实现,即设置两个NameNode,一个为主,另一个为备用。当主NameNode故障时,备用NameNode可以无缝接管,确保服务不间断。
整个安装过程中,作者会穿插介绍相关知识点,如HDFS的工作流程、MapReduce的执行机制、YARN的资源调度等,帮助读者在实践中理解Hadoop的核心概念和技术。通过这种方式,读者不仅能够学会搭建Hadoop环境,还能逐步建立起对大数据处理框架的深刻理解。
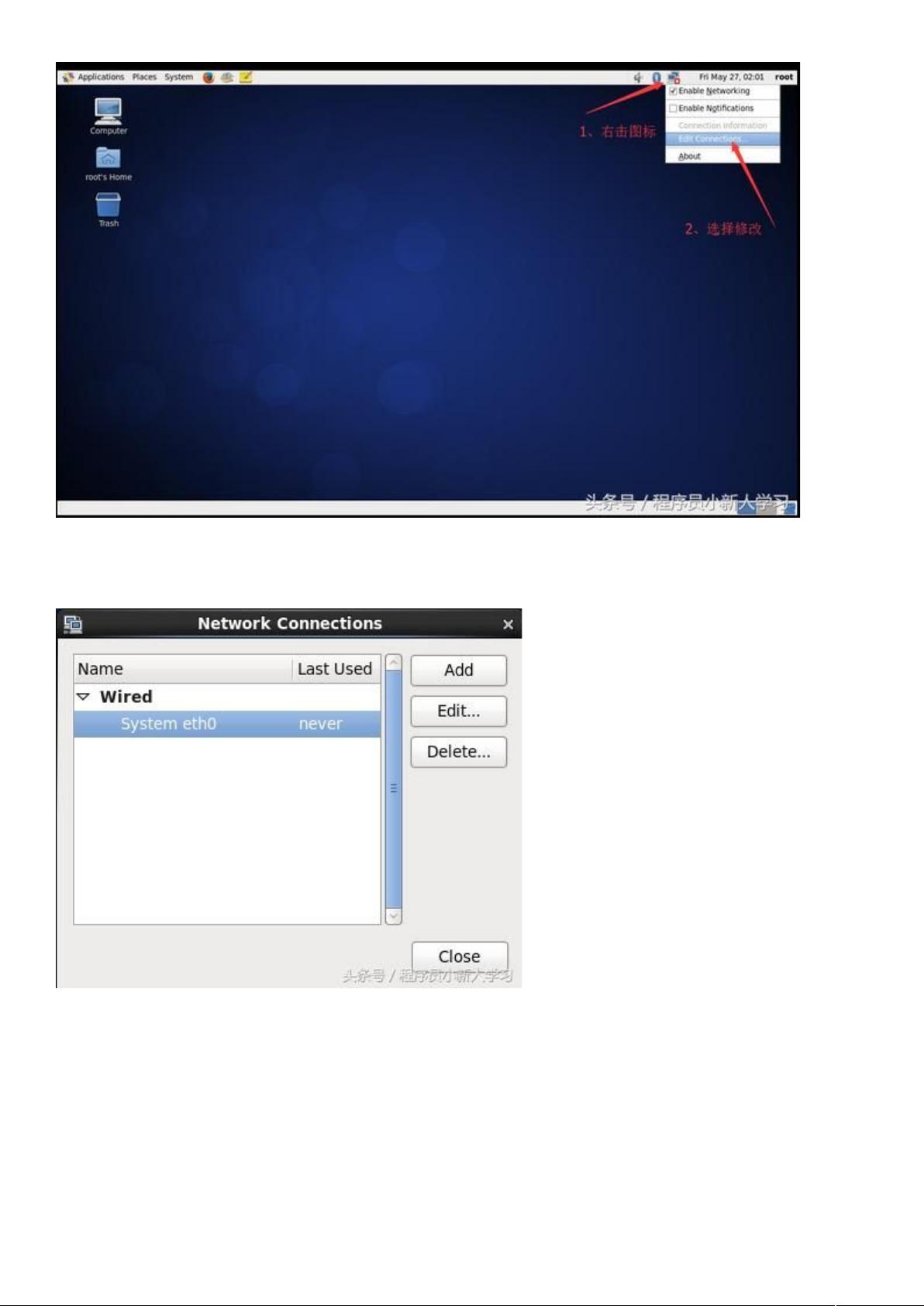
、 网络连接里列出了当前 里所有的网卡,这里只有一个网卡 06.,点击编辑。
+、 配置 ()、子网掩码、网关(和 设置的一样)、0 等参数,因为 里设置网段为
%../,所以这台机器可以设置为 %,%'-%..%. 网关和 一致,为 %,%'-%..


剩余63页未读,继续阅读
2016-06-10 上传
2023-06-06 上传
2024-04-26 上传
2023-06-12 上传
2023-04-05 上传
2024-06-21 上传
2024-10-12 上传

nhj074
- 粉丝: 2
- 资源: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
