Hadoop:云计算的分布式框架解析
需积分: 9 191 浏览量
更新于2024-07-29
收藏 355KB PDF 举报
"云计算开源框架Hadoop介绍"
Hadoop是一个由Apache基金会开发的开源框架,主要应用于大规模数据处理和分析。它的设计目标是处理和存储海量数据,尤其适用于那些不适合在单机或传统数据库上运行的大规模数据分析应用。Hadoop的核心组成部分包括Hadoop分布式文件系统(HDFS)和MapReduce计算模型。
1. **什么是Hadoop?**
Hadoop是由Google的MapReduce和GFS(Google文件系统)论文启发而诞生的。HDFS为大数据存储提供了高容错、高吞吐量的支持,而MapReduce则负责数据的处理和计算。这两个组件共同构成了Hadoop的基础架构,使得用户可以在大量廉价硬件上运行分布式应用程序,实现大数据的高效处理。
2. **为什么要选择Hadoop?**
Hadoop的优势在于其可扩展性和弹性。通过增加更多的硬件节点,Hadoop集群可以轻松地扩展存储和处理能力。此外,它支持数据的容错机制,即使部分节点故障,数据也能被安全恢复。Hadoop的开源性质也意味着开发者可以根据需求进行定制和优化。
3. **使用场景**
Hadoop常用于互联网日志分析、推荐系统、社交媒体分析、基因序列分析、视频转码、大数据挖掘等领域。它的强大之处在于能够处理PB级别的非结构化和半结构化数据。
4. **环境与部署**
部署Hadoop需要一个集群环境,通常包括NameNode、DataNode、ResourceManager和NodeManager等组件。NameNode负责元数据管理,DataNode存储数据块,ResourceManager协调任务分配,NodeManager管理每个节点上的任务执行。
5. **实施步骤**
实施Hadoop通常包括配置集群、安装软件、初始化HDFS、启动服务、测试Hadoop功能等步骤。在部署过程中,需要考虑网络拓扑、硬件配置、安全性等因素。
6. **Hadoop中的命令**
Hadoop提供了丰富的命令行工具,如hadoop fs用于文件操作,hadoop jar用于运行MapReduce程序,hadoop dfsadmin用于管理HDFS等。
7. **Hadoop基本流程**
MapReduce的基本流程包括数据输入、数据切片、Map阶段(数据处理)、Shuffle阶段(数据排序和分区)、Reduce阶段(结果汇总)以及输出结果。
8. **日志分析业务场景和代码范例**
在日志分析场景中,Hadoop可以快速处理大量服务器日志,提取关键信息,如用户行为、系统性能指标等,帮助企业进行决策分析。
9. **Hadoop集群测试**
测试Hadoop集群通常涉及性能测试、稳定性测试和压力测试,确保在各种负载条件下系统的正确性和可靠性。
10. **随想**
Hadoop的设计理念——分布式计算,就像蚂蚁群一样,通过大量协作的小单元完成看似不可能的任务。这种模式对于应对数据爆炸性的增长和复杂的数据分析需求至关重要。
Hadoop的成功在于它简化了大数据处理的复杂性,使得企业可以以相对较低的成本处理海量数据,为大数据时代的数据分析和挖掘提供了强大的工具。随着云计算的发展,Hadoop也成为了云环境中重要的大数据处理框架。
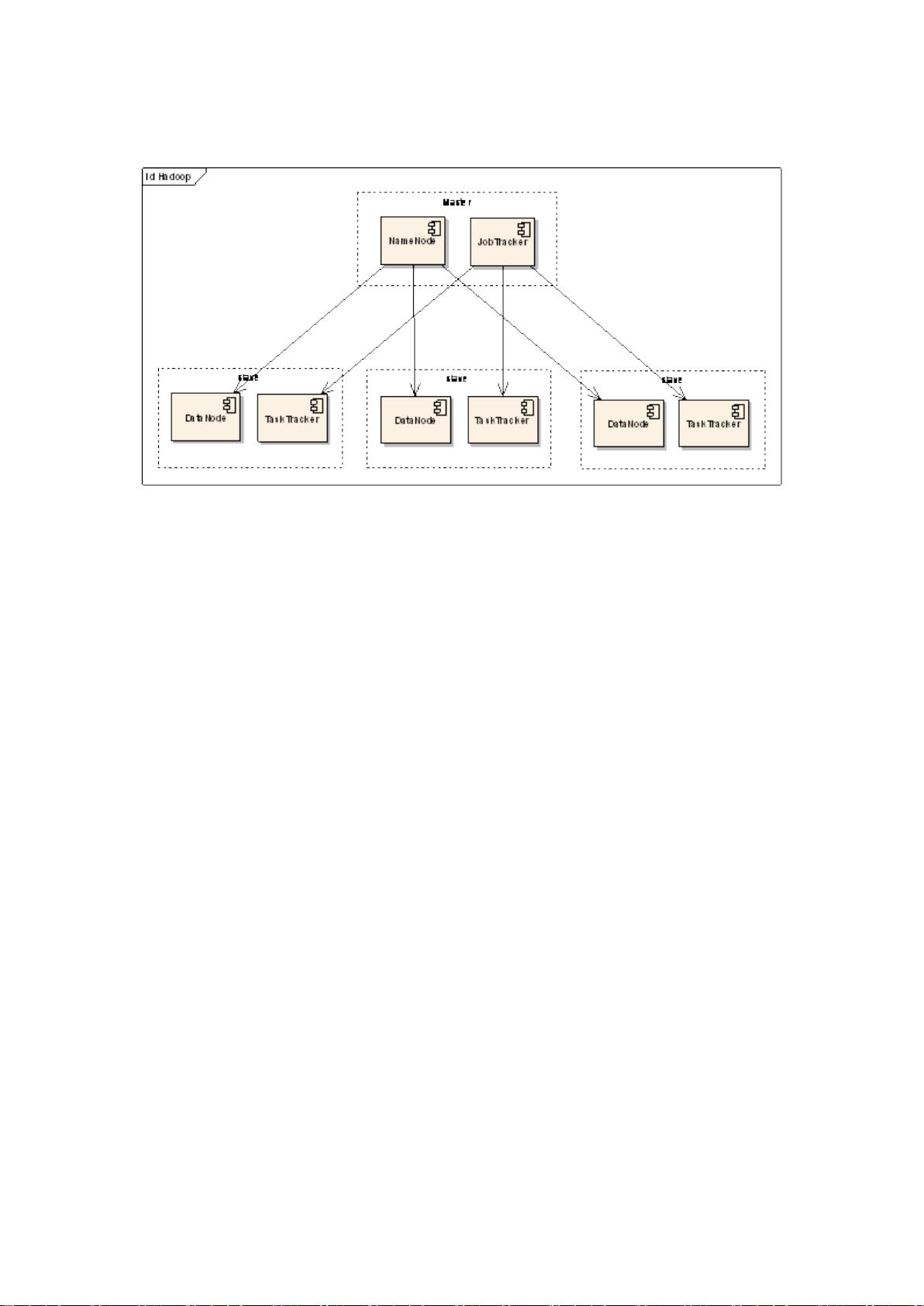
下面综合 MapReduce 和 HDFS 来看 Hadoop 的结构:
图 3:Hadoop 结构示意图
在 Hadoop 的系统中,会有一台 Master,主要负责 NameNode 的工作以及 JobTracker 的工作。
JobTracker 的主要职责就是启动、跟踪和调度各个 Slave 的任务执行。还会有多台 Slave,每
一台 Slave 通常具有 DataNode 的功能并负责 TaskTracker 的 工作。TaskTracker 根据应用要
求来结合本地数据执行 Map 任务以及 Reduce 任务。
说到这里,就要提到分布式计算最重要的一个设计点:Moving Computation is Cheaper than
Moving Data。就是在分布式处理中,移动数据的代价总是高于转移计算的代价。简单来说
就是分而治之的工作,需要将数据也分而存储,本地任务处理本地数据然后归总,这样才会
保证分布式计算的高效性。
为什么要选择 Hadoop?
1.可扩展:不论是存储的可扩展还是计算的可扩展都是 Hadoop 的设计根本。
2.经济:框架可以运行在任何普通的 PC 上。
3.可靠:分布式文件系统的备份恢复机制以及 MapReduce 的任务监控保证了分布式处理的
可靠性。
4.高效:分布式文件系统的高效数据交互实现以及 MapReduce 结合 Local Data 处理的模式,
为高效处理海量的信息作了基础准备。
使用场景
个人觉得最适合的就是海量数据的分析,其实 Google 最早提出 MapReduce 也就是为了海量
数据分析。同时 HDFS 最早是为了搜索引擎实现而开发的,后来才被用于分布式计算框架
中。海量数据被分割于多个节点,然后由每一个节点并行计算,将得出的结果归并到输出。
同时第一阶段的输出又可以作为下一阶段计算的输入,因此可以想象到一个树状结构的分布
式计算图,在不同阶段都有不同产出,同时并行和串行结合的计算也可以很好地在分布式集
群的资源下得以高效的处理。
剩余15页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2008-12-15 上传
2022-11-18 上传
2021-09-29 上传
2021-09-03 上传
2011-03-13 上传









