双向链表:存储结构与操作详解
需积分: 16 100 浏览量
更新于2024-09-26
收藏 172KB DOC 举报
本文档主要介绍了双向链表的存储结构及其与线性链表的区别。首先,我们回顾了线性链表的基本存储结构,它通过指针将节点串联起来,但每个节点只能有一个指向前一个节点的指针,这导致查找节点的直接前驱较为困难。而单向链表的这种单向性是双向链表试图改进的地方。
双向链表是一种特殊的链式数据结构,每个节点有两个指针域,一个指向前一个节点(即“prior”),另一个指向后一个节点(即“next”)。这样的设计使得在双向链表中,不仅能够轻松访问前后节点,而且可以方便地实现节点的插入和删除操作。例如,删除操作中,只需更新被删除节点的前驱和后继的指针,然后释放节点内存;插入操作则涉及创建新节点,设置其前后指针,并调整相关节点的连接。
在文档中,还给出了双向链表的典型定义,包括结构体`DulNode`,其中包含了指向前趋和后继的指针。同时,列举了双向链表删除和插入操作的伪代码,展示了如何在函数`ListDelete_DuL`和`ListInsert_DuL`中具体实现这些操作。这些函数涉及到获取指定位置元素的指针,更新前后节点的连接,以及动态分配和释放内存。
最后,文档中提到的“一个完整的带头结点的线性边表类型定义”,可能是为了提供一个标准的数据结构模板,用于创建和管理双向链表。带头结点的设计使得链表的第一个节点可以直接作为其他节点的前趋,简化了操作逻辑。
总结来说,双向链表的存储结构相比线性链表具有更强的灵活性和高效性,尤其在需要频繁进行插入和删除操作时,双向链表的优势更为明显。通过理解这些概念和操作,开发者可以更好地在实际编程中应用双向链表来优化数据结构和算法性能。
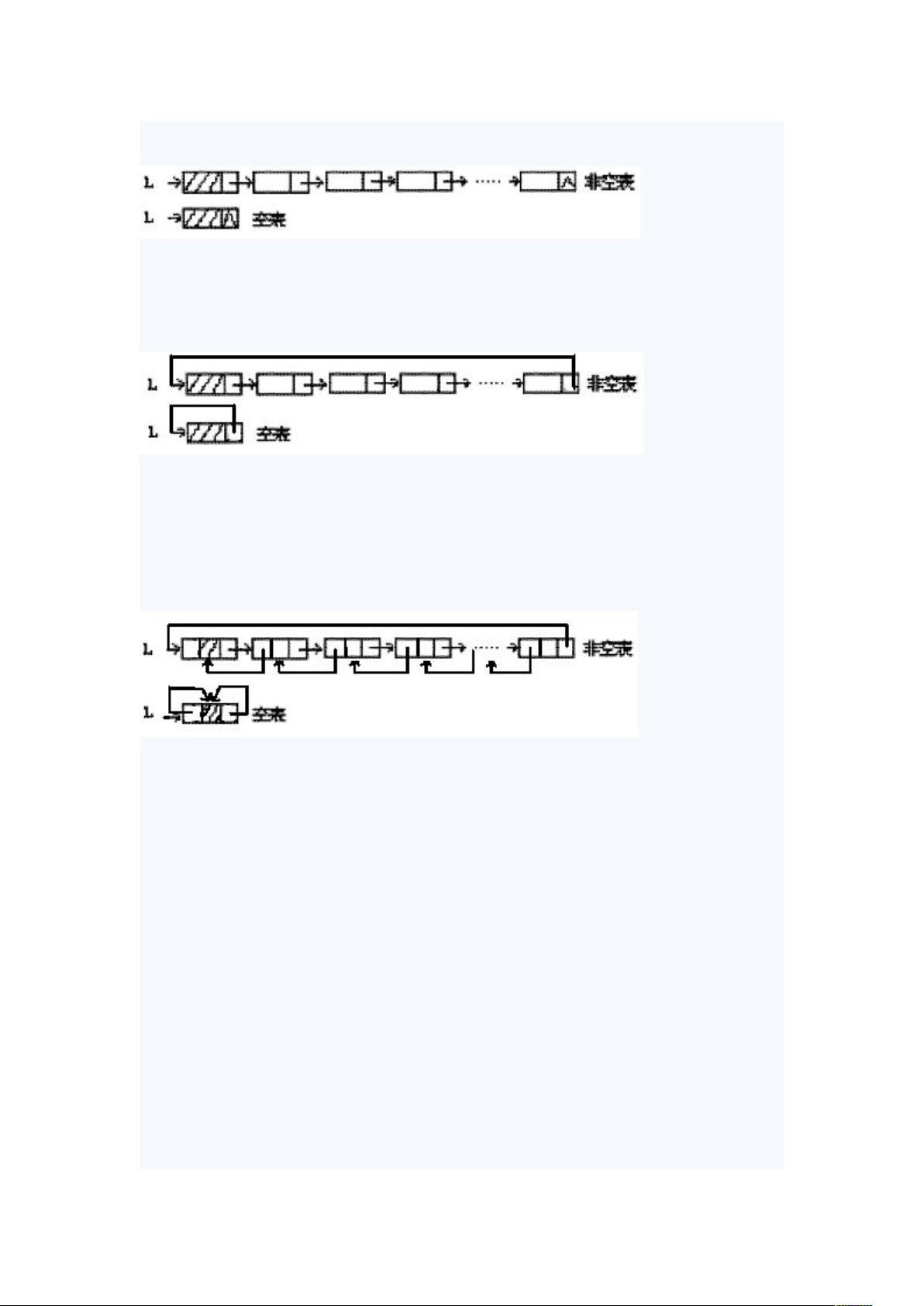
一、复习线性链表的存储结构
二、循环链表的存储结构
循环链表是加一种形式的链式存储结构。它的特点是表中最后一个结点的指针域指向头结点。
循环链表的操作和线性链表基本一致,差别仅在于算法中的循环条件不是 p 或 p->next 是否为空,
而是它们是否等于头指针。
三、双向链表的存储结构
提问:单向链表的缺点是什么?
提示:如何寻找结点的直接前趋。
双向链表可以克服单链表的单向性的缺点。
在双向链表的结点中有两个指针域,其一指向直接后继,另一指向直接前趋。
1、线性表的双向链表存储结构
typedef struct DulNode{
struct DulNode *prior;
ElemType data;
struct DulNode *next;
下载后可阅读完整内容,剩余5页未读,立即下载
2023-09-21 上传
2023-09-21 上传
2023-09-21 上传
2021-09-16 上传
2012-05-25 上传
2020-06-22 上传
2022-05-30 上传
2022-06-11 上传

liugang9931706
- 粉丝: 4
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
