Hive查询与大数据课程:排序、聚集与连接操作解析
版权申诉
173 浏览量
更新于2024-07-07
收藏 1.31MB PPTX 举报
该课程是一套全面的大数据与云计算教程,涵盖了从基础到高级的各种主题。包括Hadoop的介绍、安装、MapReduce原理、YARN、HDFS、Hive、HBase、Pig、Zookeeper、Sqoop、Flume、Kafka、Storm、Spark、Oozie、Impala、Solr、Lily、Titan、Neo4j以及Elasticsearch等内容。特别是对Hive查询进行了详细讲解,包括ORDERBY和SORTBY的区别、DISTRIBUTE BY和CLUSTER BY的使用,以及如何在Hive中进行内连接操作。
在大数据处理领域,Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。在Hive查询中,ORDER BY用于全局排序,但这种方法可能会导致性能瓶颈,因为它依赖单个reducer处理所有数据。相反,SORT BY则在每个reducer内部进行局部排序,更适合大数据集的处理。DISTRIBUTE BY则用于控制数据的分布,确保相同值的行被分配到相同的reducer中,这对于后续的聚集操作非常有用。如果DISTRIBUTE BY和SORT BY的列相同,可以使用CLUSTER BY简化语法。
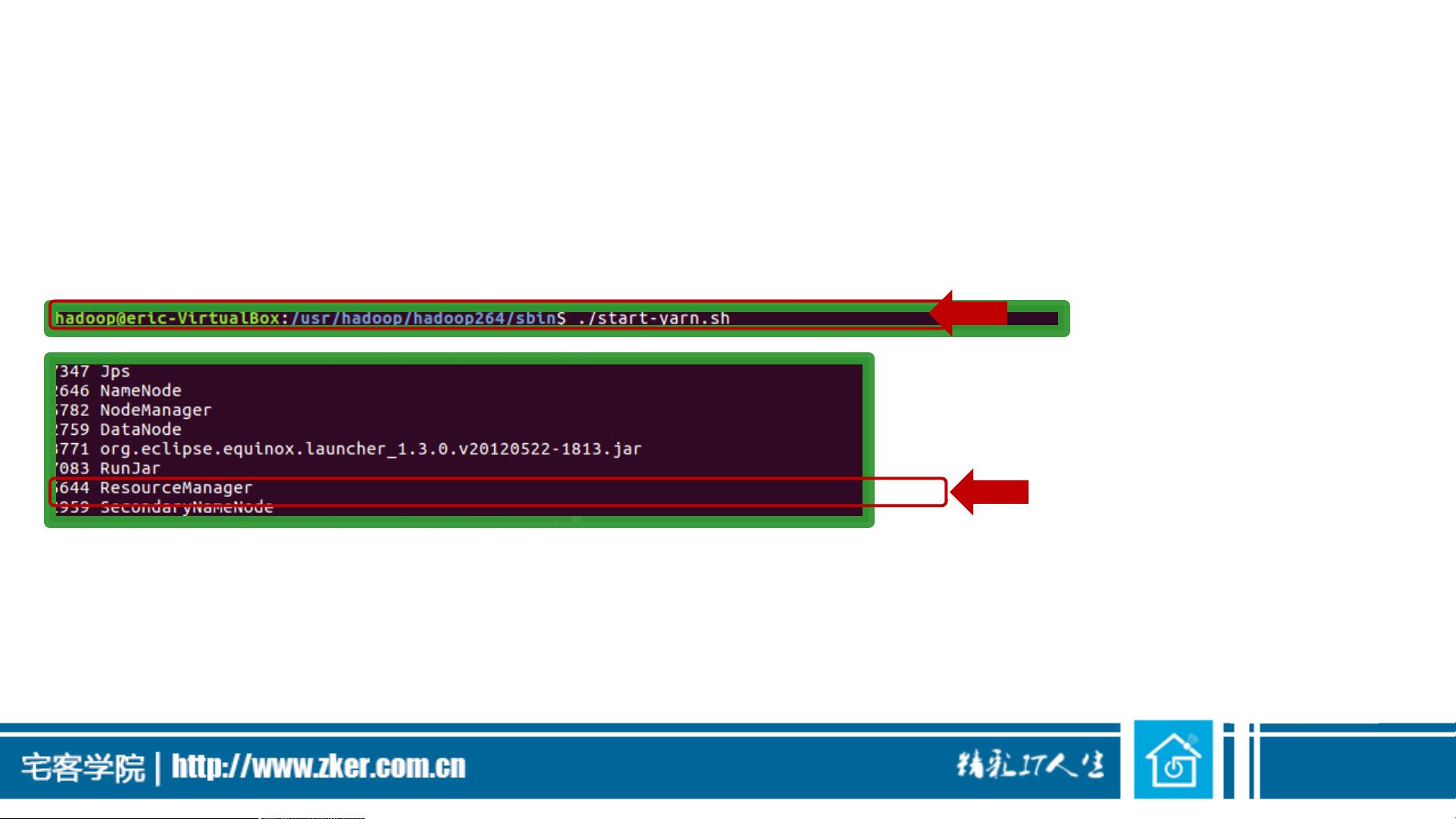
在连接操作方面,Hive提供了内连接的便利。内连接是基于连接条件匹配两表中的行,生成的结果包含两个表中满足条件的对应行。在Hive中,内连接通常通过JOIN ON语句实现,连接条件可以是多个列的组合。然而,Hive不支持某些数据库系统中在FROM子句中直接指定连接表的语法,而是要求在JOIN ON后面指定连接条件。在实际运行Hive查询时,尤其是在使用YARN作为资源管理器的情况下,确保YARN已经启动,否则连接查询可能因缺少reduce任务而失败。
此外,课程还涉及其他大数据处理工具,如Pig用于数据处理的高级语言Pig Latin,Zookeeper提供分布式协调服务,Sqoop用于Hadoop和关系数据库之间的数据迁移,Kafka是消息中间件,Storm处理实时流数据,Spark提供了快速、通用和可扩展的数据处理,而Elasticsearch是强大的搜索引擎。整个课程旨在帮助学习者全面掌握大数据处理和云计算的相关技术和实践。
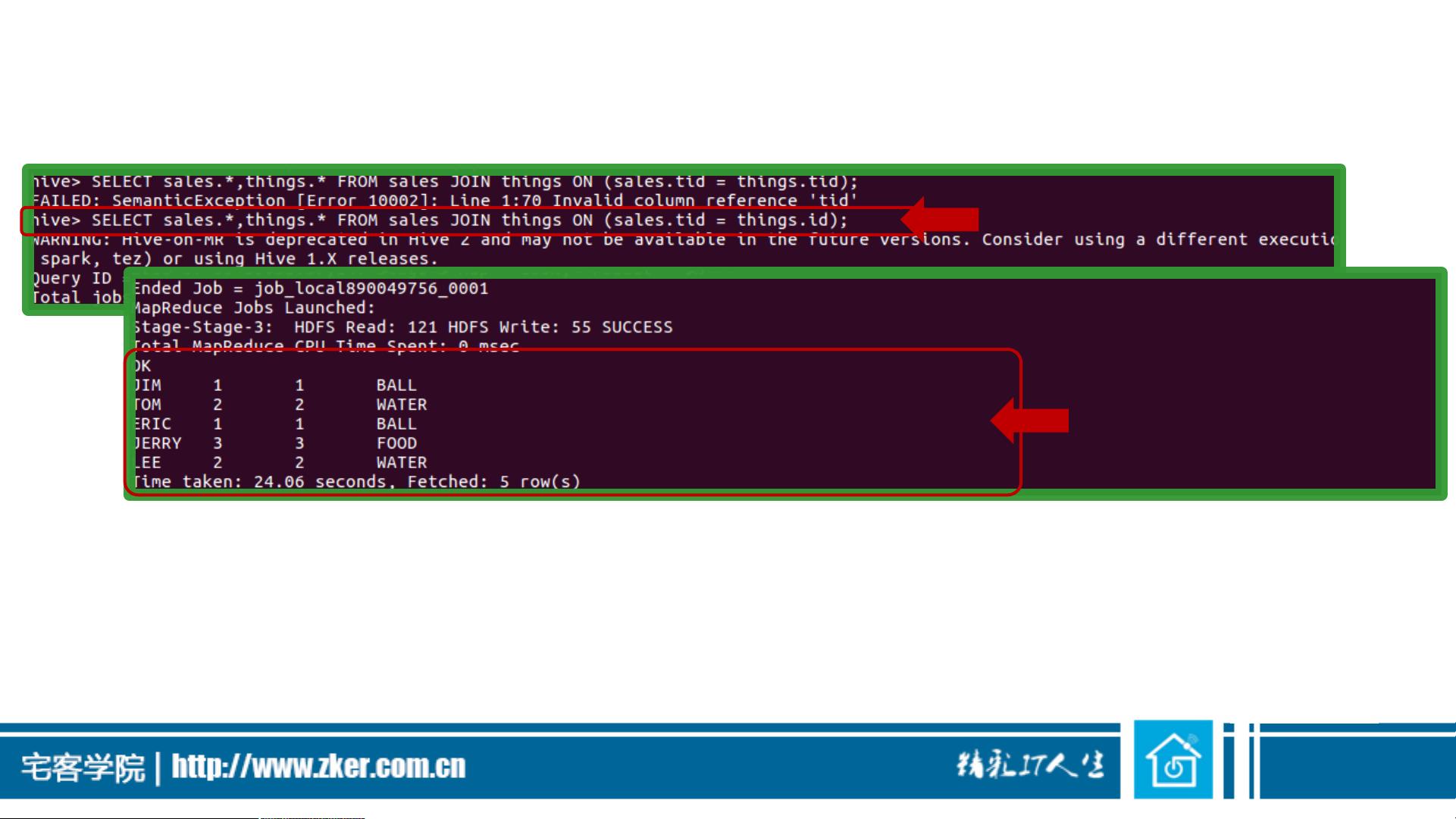
内连接
• 可以使用下面的查询语句完成内连接(类似SQL):
• 有些数据库,例如MySQL和Oracle,允许在SELECT语句的FROM子句中列
出要连接的表,而在WHERE子句中指定连接条件,但是Hive中并不支持
这种语法。
利用JOIN ON语句实现连接
连接结果
剩余31页未读,继续阅读
157 浏览量
254 浏览量
154 浏览量
155 浏览量
161 浏览量
305 浏览量
199 浏览量
158 浏览量
160 浏览量

passionSnail
- 粉丝: 469
- 资源: 7836
 我的内容管理
展开
我的内容管理
展开







