强化学习与机器人运动控制:IROS2015讲义
需积分: 5 107 浏览量
更新于2024-07-17
收藏 2.97MB PDF 举报
"mlpc15_handout.pdf 是一本关于强化学习和机器人控制的书籍,适合于想要深入理解强化学习算法在机器人运动规划与控制中的应用的读者。书中的内容涵盖了从基本概念到在线学习和规划的方法。"
正文:
这本书籍深入探讨了强化学习这一机器学习领域的重要分支,其主要目标是找到一种控制策略,以优化系统的累积性能。在强化学习中,系统通常是未知的,需要通过数据来学习。特别地,当系统是机器人本身或其环境时,强化学习显得尤为重要。
书中首先介绍了马尔科夫决策过程(Markov Decision Process, MDP),这是强化学习的基础模型。MDP涉及观察状态x,执行动作u,并接收到奖励r。系统的动态是随机的,即x_{k+1}由x_k、u_k以及某个概率分布f决定。性能指标是累计奖励函数R_h(x_0),目标是找到控制策略u_k=h(x_k)来最大化期望的折扣回报。
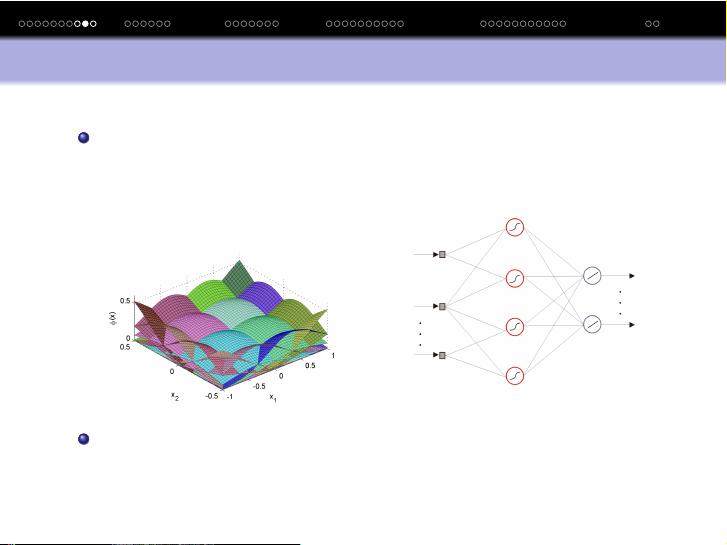
接着,书中引入了Q函数的概念,它是评估状态-动作对价值的函数。Q函数h表示的是采取动作u后,从状态x出发的预期回报。贝尔曼方程描述了Q函数如何根据当前奖励和未来的Q函数值进行更新。最优的Q函数Q^*对应于能够最大化长期回报的动作选择。
贝尔曼最优方程进一步阐述了这一点,它表示最优Q函数Q^*(x,u)等于当前奖励的期望加上下一步采取最优策略时的折扣Q函数值。这个方程是求解强化学习问题的关键,通常通过迭代算法如Q学习或SARSA等方法来逼近。
除了理论基础,书籍还涵盖了在线强化学习(Online TDRL)和在线规划(Online planning)的实践方法,这些方法允许算法在与环境交互的过程中不断学习和改进。这在机器人控制中尤其有用,因为机器人需要在实际操作中适应环境变化。
"mlpc15_handout.pdf" 提供了一个全面的框架,从基础理论到实际应用,帮助读者理解和掌握强化学习在机器人控制领域的核心思想和技术。无论是对于研究人员还是工程实践者,这本书都是一个宝贵的资源,能够引导他们探索这个充满挑战和机遇的领域。
2022-03-06 上传
2022-01-13 上传
2022-05-07 上传
2022-02-17 上传
2022-01-06 上传
2021-04-08 上传
2021-08-20 上传
109 浏览量
2022-02-17 上传

Peppa__Pig
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 华为内部linux教程
- 微软ASP.NET AJAX框架剖析
- MPEG-4 ISO 标准 ISO/IEC14496-5
- 转贴:随心所欲的Web页面打印技术
- c语言100例.doc
- JSP数据库编程指南.pdf
- 完全精通局域网-局域网速查手册
- ENVI遥感影像处理专题与实践\用户指南与实习指南.pdf
- 软考试卷06下cxys.pdf
- usb设备驱动开发详解-讲座
- 深入浅出Win32多线程程序设计
- 水文控制系统子程序详细的mp430程序
- John.Lions-Lions'.Commentary.on.UNIX.6th.Edition.with.Source.Code.pdf
- PHP和MySQL Web开发 第四版
- ArcGIS Server 9.2 javascript ADF核心 帮助文档
- java 基础及入门
