百度知识图谱:构建与应用详解
百度知识图谱是百度公司开发的一种基于自然语言处理(Natural Language Processing, NLP)技术构建的知识管理工具,它在搜索引擎优化和用户查询解答中发挥着关键作用。知识图谱的构建流程涉及知识挖掘(Knowledge Mining)、语义计算(Semantic Computation)等多个步骤,旨在创建一个结构化的知识库,方便理解和提供准确的信息。
首先,构建知识图谱的核心步骤包括知识的采集(KnowledgetoMine)。在这个阶段,百度知识图谱关注两种主要实体:命名实体(Named Entities)和普通实体(Normal entities)。命名实体通常涉及到人、地点、组织等传统类别,如电影《中国合伙人》中的主角和相关机构。而随着互联网的发展,新的类别也不断涌现,如电影、电视剧、音乐、书籍和软件等,这些都纳入了知识图谱的范畴,并且细化了分类,例如组织类别下可能进一步细分为学校、医院、政府等子类。
除了基本的命名实体识别,还涉及到更深入的语义关系挖掘,比如hyponymy学习,即通过层次结构来表示实体之间的上下位关系,如“电影”与“励志电影”、“中国合伙人”之间的关系。这种关系有助于提供更精确的答案和推荐。
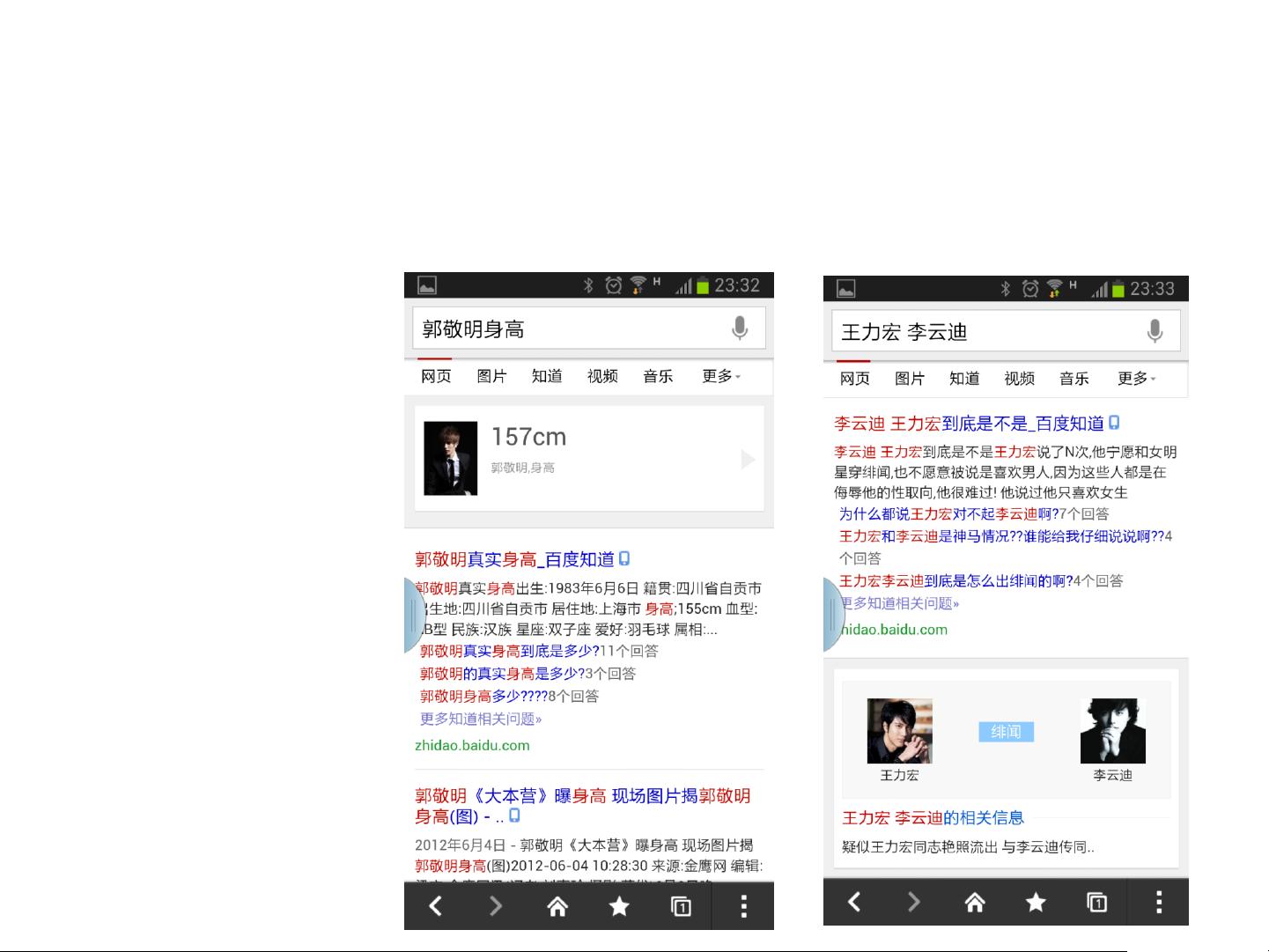
对于用户搜索场景,百度知识图谱在PC搜索和移动搜索中都提供了不同的功能。在PC搜索中,它支持精确答案的提供,能够快速给出直接、准确的问题解答。而在移动搜索方面,除了精确答案,还包括列表推荐服务,根据用户的查询意图,智能地展示相关的信息列表,帮助用户更快找到所需内容。
此外,学习命名实体的过程并非孤立的,百度知识图谱会利用查询日志(Query logs)作为数据源,通过对用户搜索行为的分析,动态捕捉和学习新的命名实体及其变化,这体现了知识图谱的实时性和适应性,尤其是在软件、游戏和小说等新兴领域,新实体的出现和名称的非正式性成为知识图谱学习的一个重要挑战。
百度知识图谱通过NLP技术和丰富的知识矿藏,构建了一个动态且精细的知识网络,极大地提升了搜索体验,是现代搜索引擎的重要组成部分,对于提升搜索引擎的智能化水平和用户满意度具有重要意义。
Zhixin for Baidu Mobile Search
• Exact answers
剩余38页未读,继续阅读
2019-11-29 上传
2021-09-20 上传
2023-01-16 上传
2019-01-07 上传
2019-08-11 上传

sinat_40260360
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
