Python3爬虫识别点触验证码实战教程
143 浏览量
更新于2024-09-01
收藏 371KB PDF 举报
点触验证码识别在Python3爬虫中是一个挑战性较大的任务,因为它们通常涉及到复杂的图像处理和人工智能技术。本文主要以12306网站和TouClick服务为例,讲解如何应对这种类型的验证码。
首先,点触验证码的核心在于用户需要根据提示在图像中找到并点击特定的元素,可能是文字或图形。例如,12306的验证码要求用户点击所有符合特定条件的图像,而TouClick则可能是点击特定的文字。这些元素往往经过变形、模糊处理,增加了识别的难度。
在Python3中,通常我们会使用Selenium库来模拟浏览器行为,因为它能够自动化浏览器操作,包括点击验证码中的元素。然而,直接使用Selenium进行识别并不容易,因为我们需要准确地定位到这些元素,这就需要对HTML结构有深入理解。
对于文字识别,传统的OCR(Optical Character Recognition)技术可能效果不佳,因为点触验证码的文字通常经过了特殊的变形处理。现代的深度学习模型如CNN(Convolutional Neural Networks)在图像识别上有较好的表现,但构建和训练这样的模型需要大量的标注数据和计算资源。
图像识别方面,我们可以考虑使用预训练的深度学习模型,如VGG、ResNet或Inception等,对图片进行特征提取和分类。然而,由于点触验证码的多样性,可能需要定制化训练模型来适应不同的验证码类型,这在实际操作中非常复杂。
此外,还可以考虑使用第三方API,如阿里云、腾讯云提供的图像识别服务,它们可能已经有针对这类验证码的解决方案。尽管这些服务的准确率通常较高,但可能会有费用问题,并且也可能存在误识别的风险。
识别点触验证码是一个涉及多种技术和策略的问题,包括但不限于浏览器自动化、OCR、深度学习模型以及第三方API的使用。在实际的Python3爬虫项目中,开发者需要根据具体需求和资源选择合适的方法,有时甚至需要结合多种技术来提高识别的成功率。同时,为了遵守网站的反爬策略和道德规范,应当尽量避免大规模、高频次的验证码识别,以免对网站服务器造成负担。
Python3爬虫关于识别点触点选验证码的实例讲解爬虫关于识别点触点选验证码的实例讲解
在本篇文章里小编给大家整理了关于Python3爬虫关于识别点触点选验证码的实例讲解内容,需要的朋友们可以
参考下。
上一节我们实现了极验验证码的识别,但是除了极验其实还有另一种常见的且应用广泛的验证码,比较有代表性的就是点触验
证码。
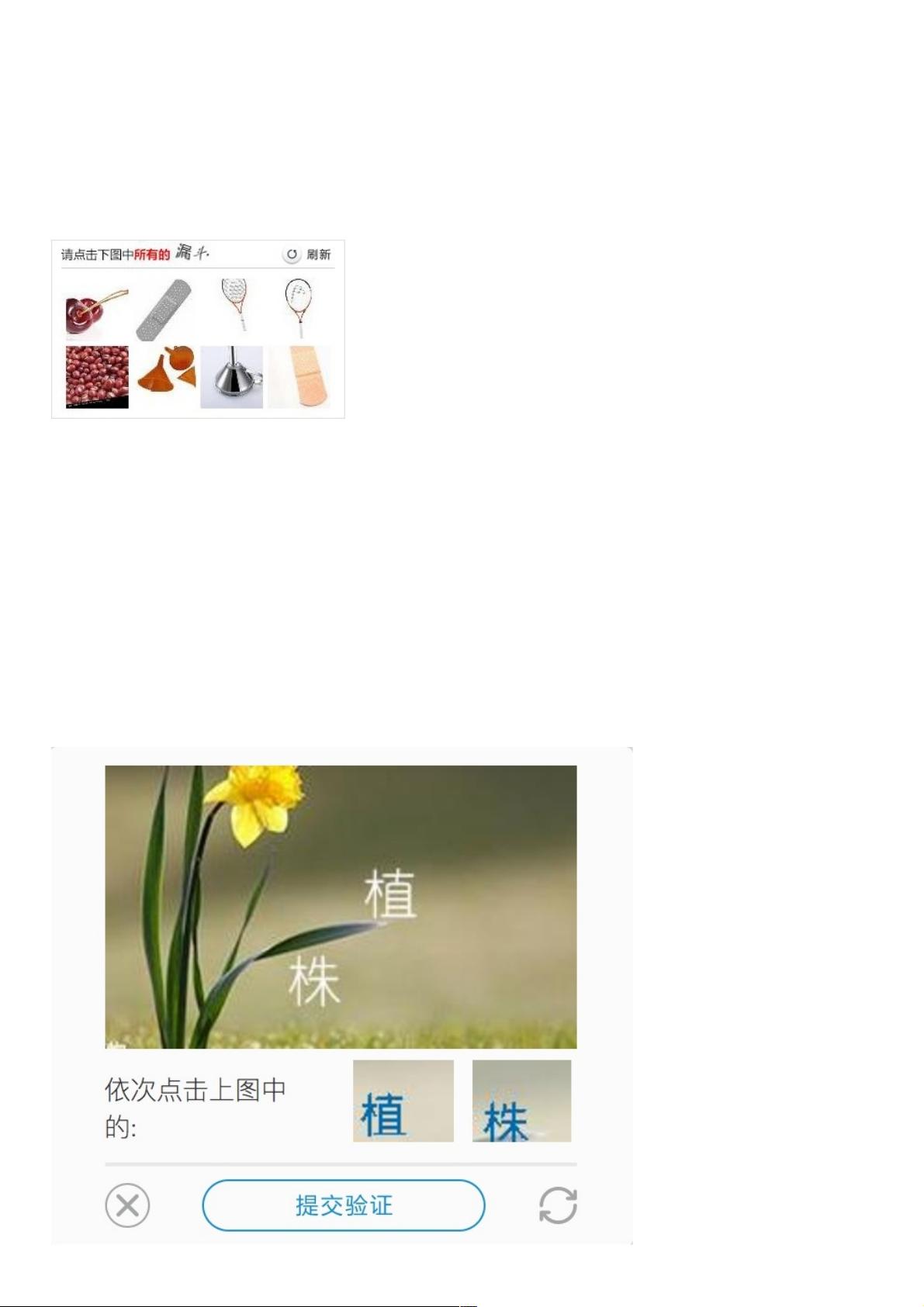
可能你对这个名字比较陌生,但是肯定见过类似的验证码,比如 12306,这就是一种典型的点触验证码,如图所示:
我们需要直接点击图中符合要求的图,如果所有答案均正确才会验证成功,如果有一个答案错误,验证就会失败,这种验证码
就可以称之为点触验证码。
另外还有一个专门提供点触验证码服务的站点,叫做 TouClick,其官方网站为:https://www.touclick.com/,本节就以它为例
讲解一下此类验证码的识别过程。
1. 本节目标本节目标
本节我们的目标是用程序来识别并通过点触验证码的验证。
2. 准备工作准备工作
本次我们使用的 Python 库是 Selenium,使用的浏览器为 Chrome,在此之前请确保已经正确安装好了 Selenium 库、
Chrome浏览器并配置好了 ChromeDriver,相关流程可以参考第一章的说明。
3. 了解点触验证码了解点触验证码
TouClick 官方网站的验证码样式如图 8-19 所示:
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-06-10 上传
2020-12-31 上传
2020-09-20 上传
2019-08-12 上传
2021-01-20 上传

weixin_38558660
- 粉丝: 2
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
