Spark驱动的数据仓库迁移:从MPP到高性能分析
需积分: 10 121 浏览量
更新于2024-07-18
收藏 6.54MB PDF 举报
在"构建数据仓库"的分享中,eBay大数据架构师俞育才在QCon-Summit 2018会议上探讨了现代化数据仓库的构建过程,重点关注将MPP(大规模并行处理)数据库管理系统迁移到Spark。这一迁移的主要背景是企业寻求增加数据仓库的灵活性,扩展其处理能力,包括批处理、流处理、图分析和机器学习等任务,并实现性能和成本的最大化优化。
为什么要进行迁移:
1. 增加灵活性:迁移目标旨在提升工程和投资的灵活性,使数据仓库能够适应多样化的分析需求。
2. 扩展能力:Spark提供了统一的分析框架,支持多种数据处理场景,如Batch、Streaming、Graph和ML等。
3. 极致性能:Spark凭借In-memory计算、Catalyst查询优化器和Tungsten等特性,提供出色的性能。
4. 强大社区支持:Spark拥有活跃且丰富的社区,有利于问题解决和持续改进。
5. 兼容性:Spark具有良好的兼容性,能无缝对接现有的数据基础设施。
迁移前的准备包括明确目标,如迁移5000个目标表、20000个临时表、30PB压缩数据,以及每日处理量高达60PB的数据量,计划在一年的时间线上完成。
迁移方案分为两个部分:
- 自动化分层迁移:通过定制的自动迁移框架,如MigrationPlanner,来管理和执行数据迁移过程,处理表与作业之间的依赖关系。
- 必要的手动迁移:对于某些复杂或特殊的表结构,可能需要人工干预来进行迁移。
规划阶段涉及软硬件基础设施的准备,如资源容量评估、数据质量控制,以及优化集群性能。这包括硬件配置升级、软件环境配置,确保迁移过程中数据质量和系统的稳定性。
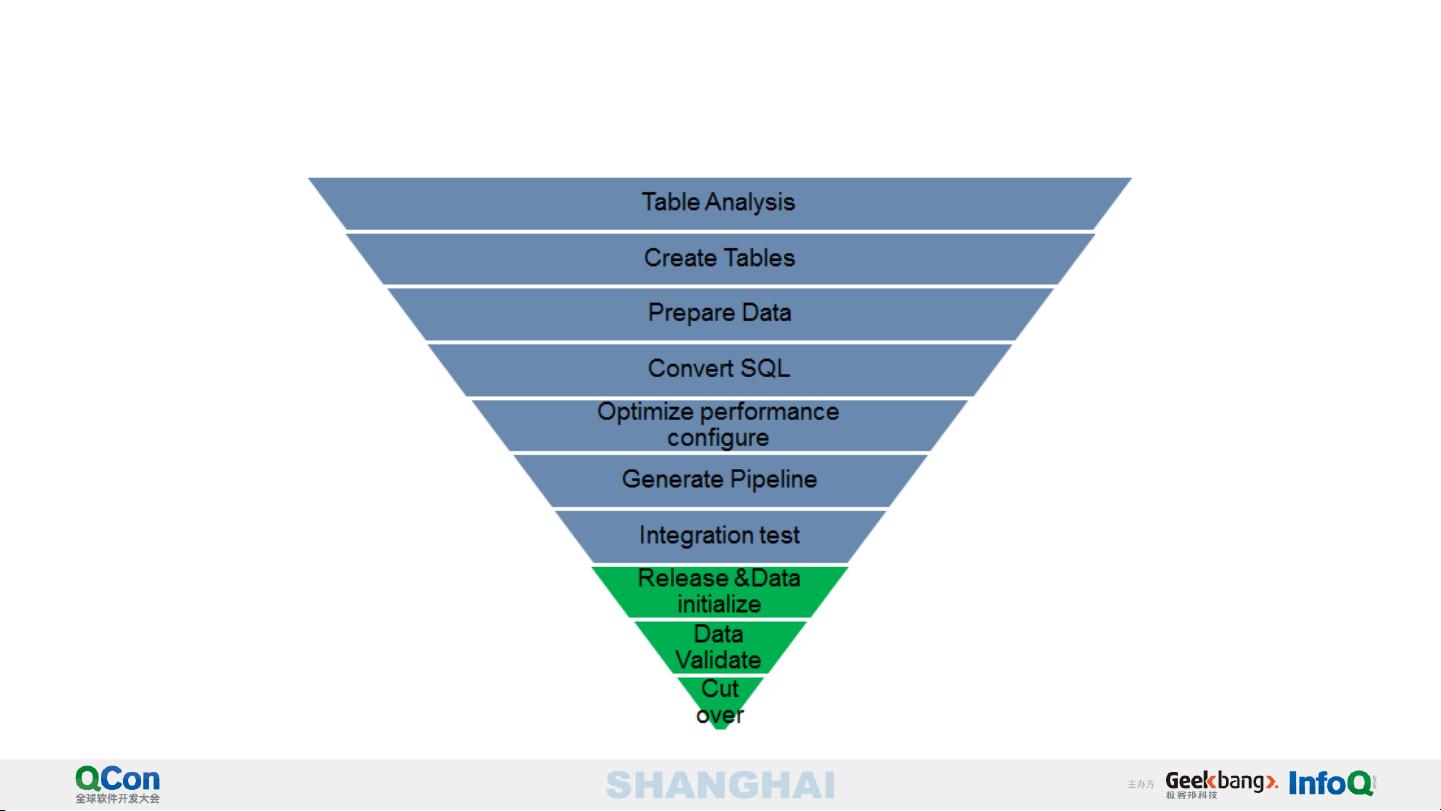
关键的迁移步骤包括:
- Metadata管理:对源和目标系统中的元数据进行整理和同步。
- MigrationEngine:负责实际的数据迁移操作。
- Controller和ProcessManager:协调整个迁移过程,监控任务执行。
- TaskInvoker:执行具体的迁移任务。
- TaskMonitor:实时跟踪任务进度和状态。
- DDLGenerator:自动生成适配目标系统的SQL脚本。
- SQLConvertor:转换源数据以适应新环境。
- JobOptimizer:优化迁移作业的执行效率。
- PipelineGenerator:设计和生成迁移工作流程。
- ReleaseAssistant:协助版本管理和发布。
- DataMover:实际的数据移动工具。
- DataValidator:验证迁移后的数据完整性。
- Metadata-related tools:如Neo4j用于元数据管理,MySQL存储相关配置信息,以及针对不同表类型(如TableProfile、SQLFileProfile、PipelineProfile)和数据流线的详细信息(DataLinage和JobL)。
通过这样的系统化方法,企业可以高效、安全地将数据仓库迁移到Spark平台,实现数据处理能力的显著提升。



点击了解资源详情
117 浏览量
1143 浏览量
195 浏览量
178 浏览量
358 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

cancelqi
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 翁云兵的3D游戏编程入门教程:DirectX9.0详解
- 软件架构师研修讲座:从瀑布到迭代,解决开发挑战
- Java工厂模式详解:简单工厂、工厂方法、抽象工厂
- Linux零基础入门:简易教程与学习笔记
- Java面试必备:核心知识点与题目解析
- .NET面向对象深度探索:从出生到旅行
- C8051F120/130混合信号ISPFLASH微控制器数据手册详解
- SQL Server 2000数据库系统与管理
- 通用试题库管理系统:设计与实现
- 汤子瀛操作系统习题答案详解:考研必备
- UML驱动的工作流管理系统:自动化与应用趋势探讨
- 探索Visual C++编程深度:工程、MFC、DAO与调试秘籍
- 中文版Keil Cx51编译器用户手册:免费下载与改进指南
- 图布局算法详解与应用
- C语言函数调用揭秘:从源码到汇编
- 数据流图绘制解析:从描述到图表的转化步骤
