Sentence-BERT:BERT网络的创新改造,提升语义搜索效率
需积分: 1 53 浏览量
更新于2024-08-03
收藏 536KB PDF 举报
Sentence-BERT(SBERT)是由Nils Reimers和Iryna Gurevych在Unibversity of Darmstadt的Ubiquitous Knowledge Processing Lab (UKP-TUDA)及计算机科学系提出的开创性工作。该研究发表于2019年,针对BERT(Devlin等人,2018年)和RoBERTa(Liu等人,2019年)在处理诸如语义文本相似性(STS)等句子对回归任务时所取得的卓越性能进行了改进。原始的BERT架构设计虽然强大,但在处理语义相似性搜索和无监督任务,如聚类时存在显著的问题,因为其要求同时处理两个输入句子,这导致了巨大的计算开销。
SBERT的核心创新在于引入了Siamese和Triplet网络结构。Siamese网络是一种双胞胎网络结构,两个网络共享同一权重,用于同时处理两个输入句子,从而产生对应的嵌入表示。这种设计消除了每次比较都需要独立处理两个句子的需求,大大减少了计算成本。Triplet网络则进一步提升了模型的对比能力,通过学习相似度和距离关系,使得模型能更准确地判断出两个句子之间的相对位置。
通过这种方式,SBERT能够生成具有语义意义的句子嵌入,这些嵌入可以使用余弦相似性进行高效比较。相比于使用BERT或RoBERTa进行大规模句子对相似性搜索,SBERT将查找10,000个句子中最相似的一对所需的时间从大约65小时(约6500万次推理计算)缩短至约5秒,同时保持了与BERT相当的准确性。这一改进不仅提高了效率,也使得BERT在更多实际应用中,如信息检索、文本分类和情感分析等领域,变得更加实用和便捷。
Sentence-BERT是对预训练BERT模型的优化,通过引入轻量级的网络结构和高效的相似度评估方法,它极大地降低了在处理大量文本数据时的计算负担,使得基于语义的自然语言处理任务变得更加可行。这项工作的成果不仅提升了学术界对深度学习模型在自然语言理解中的理解和实践,也为实际场景中的实时性和可扩展性提供了新的解决方案。
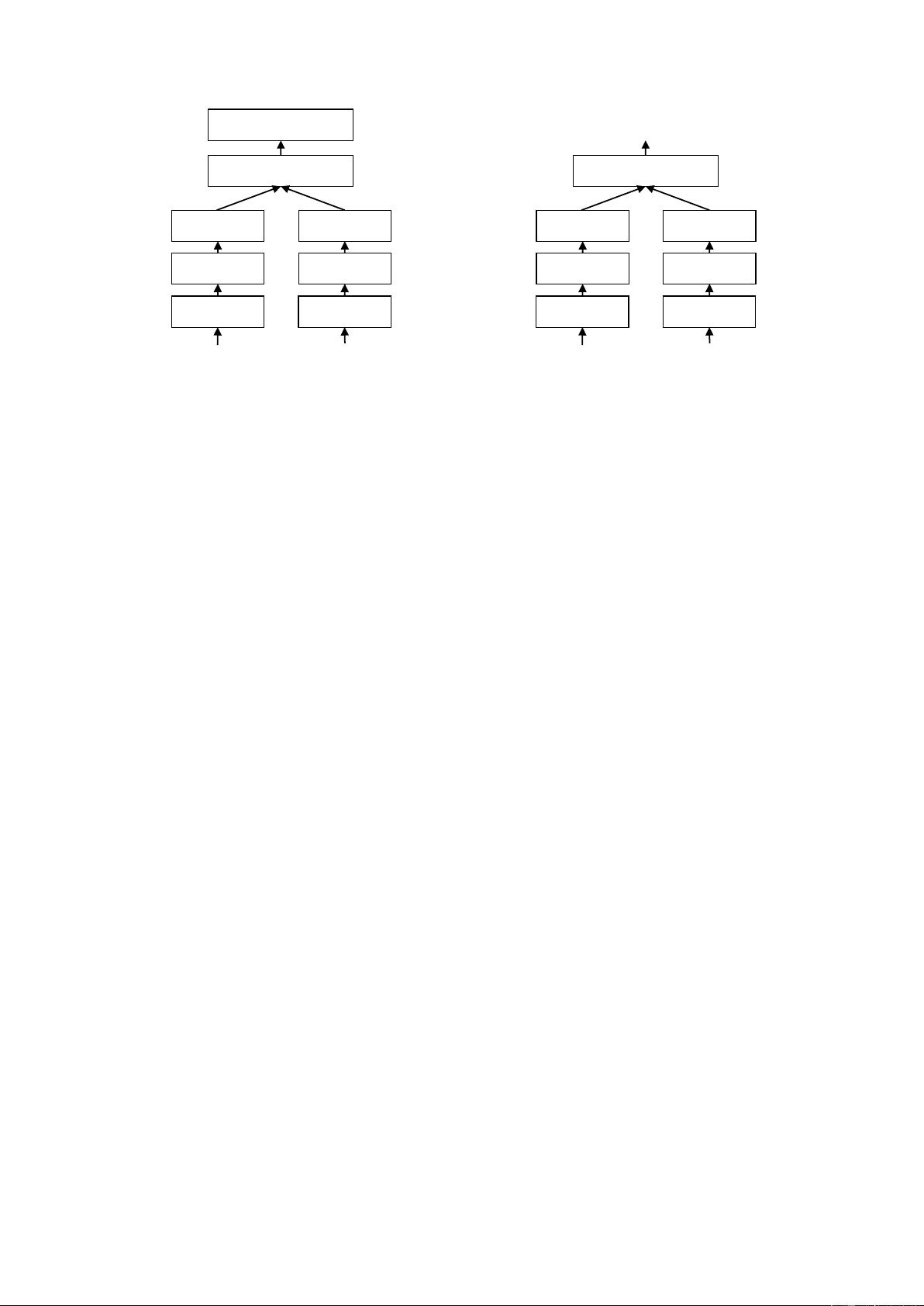
Sentence A Sentence B
BERT BERT
u v
pooling pooling
(u, v, |u-v|)
Softmax classifier
Figure 1: SBERT architecture with classification ob-
jective function, e.g., for fine-tuning on SNLI dataset.
The two BERT networks have tied weights (siamese
network structure).
computed candidate embeddings using attention.
This idea works for finding the highest scoring
sentence in a larger collection. However, poly-
encoders have the drawback that the score function
is not symmetric and the computational overhead
is too large for use-cases like clustering, which
would require O(n
2
) score computations.
Previous neural sentence embedding methods
started the training from a random initialization.
In this publication, we use the pre-trained BERT
and RoBERTa network and only fine-tune it to
yield useful sentence embeddings. This reduces
significantly the needed training time: SBERT can
be tuned in less than 20 minutes, while yielding
better results than comparable sentence embed-
ding methods.
3 Model
SBERT adds a pooling operation to the output
of BERT / RoBERTa to derive a fixed sized sen-
tence embedding. We experiment with three pool-
ing strategies: Using the output of the CLS-token,
computing the mean of all output vectors (MEAN-
strategy), and computing a max-over-time of the
output vectors (MAX-strategy). The default config-
uration is MEAN.
In order to fine-tune BERT / RoBERTa, we cre-
ate siamese and triplet networks (Schroff et al.,
2015) to update the weights such that the produced
sentence embeddings are semantically meaningful
and can be compared with cosine-similarity.
The network structure depends on the available
Sentence A Sentence B
BERT BERT
u v
pooling pooling
cosine-sim(u, v)
-1 … 1
Figure 2: SBERT architecture at inference, for exam-
ple, to compute similarity scores. This architecture is
also used with the regression objective function.
training data. We experiment with the following
structures and objective functions.
Classification Objective Function. We con-
catenate the sentence embeddings u and v with
the element-wise difference |u− v| and multiply it
with the trainable weight W
t
∈ R
3n×k
:
o = softmax(W
t
(u, v, |u − v|))
where n is the dimension of the sentence em-
beddings and k the number of labels. We optimize
cross-entropy loss. This structure is depicted in
Figure 1.
Regression Objective Function. The cosine-
similarity between the two sentence embeddings
u and v is computed (Figure 2). We use mean-
squared-error loss as the objective function.
Triplet Objective Function. Given an anchor
sentence a, a positive sentence p, and a negative
sentence n, triplet loss tunes the network such that
the distance between a and p is smaller than the
distance between a and n. Mathematically, we
minimize the following loss function:
max(||s
a
− s
p
|| − ||s
a
− s
n
|| + , 0)
with s
x
the sentence embedding for a/n/p, || · ||
a distance metric and margin . Margin ensures
that s
p
is at least closer to s
a
than s
n
. As metric
we use Euclidean distance and we set = 1 in our
experiments.
3.1 Training Details
We train SBERT on the combination of the SNLI
(Bowman et al., 2015) and the Multi-Genre NLI
剩余10页未读,继续阅读
2023-07-18 上传
2021-05-27 上传
2023-04-30 上传
2021-05-01 上传
2021-06-18 上传
2024-03-09 上传
2023-11-19 上传
2021-07-07 上传
点击了解资源详情

林戈的IT生涯
- 粉丝: 1w+
- 资源: 111
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
