"基于线性回归的PM2.5值预测实验设计及数据分析"
需积分: 0 109 浏览量
更新于2023-12-23
收藏 2.76MB DOCX 举报
本次实验旨在运用学习到的线性回归知识,手动使用adagrad梯度下降方法,通过给定的监测数据来完成对PM2.5值的回归预测。实验材料包括Train.csv和Test.csv两个数据集,其中Train.csv包含了该监控站每个月前20天的完整资料,而Test.csv则从剩下的资料中取样出连续的10小时为1笔数据,前9小时所有的观测数据作为特征,第10小时的PM2.5作为目标值。共计可以取出240笔不重复的测试数据。数据中包含了18项污染物的观测数据,如AMB_TEMP、CH4、CO、NHMC等。实验的目标是根据这些特征来预测这240笔数据的PM2.5值。
在设计上,实验首先要从Train.csv数据集中获取训练数据,然后通过手动实现adagrad梯度下降方法进行模型训练,最终得出训练好的模型。接着,需要从Test.csv数据集中获取测试数据,利用训练好的模型对这些测试数据进行预测,最后评估模型的性能指标。
在实验原理上,线性回归是一种常见的机器学习方法,通过寻找输入特征和输出值之间的线性关系来进行预测。而adagrad梯度下降方法是一种优化算法,通过自适应地调整学习率,能够更快地收敛到最优解。因此,本次实验的核心在于将线性回归与adagrad梯度下降相结合,完成对PM2.5值的预测。
在实验过程中,需要对特征数据进行预处理,包括数据清洗、特征选择、特征缩放等步骤。然后,需要手动实现adagrad梯度下降算法,包括计算梯度、更新参数、设置学习率等操作。接着,将训练好的模型应用于测试数据集,得出预测结果,并通过评估指标如均方误差(MSE)、决定系数(R^2)等来评估模型的性能。
在实验实施中,需要使用Python或其他相关的编程语言来进行数据处理、模型训练和预测以及性能评估。同时,还需要结合相关的机器学习库如NumPy、Pandas、Scikit-learn等来简化实现过程,并提高效率。
总之,本次实验通过手动实现adagrad梯度下降方法结合线性回归模型,利用给定的监测数据完成了对PM2.5值的回归预测,实验过程涉及到数据处理、模型训练和预测以及性能评估等步骤,旨在通过实际操作加深对机器学习原理的理解,并掌握相关技能。
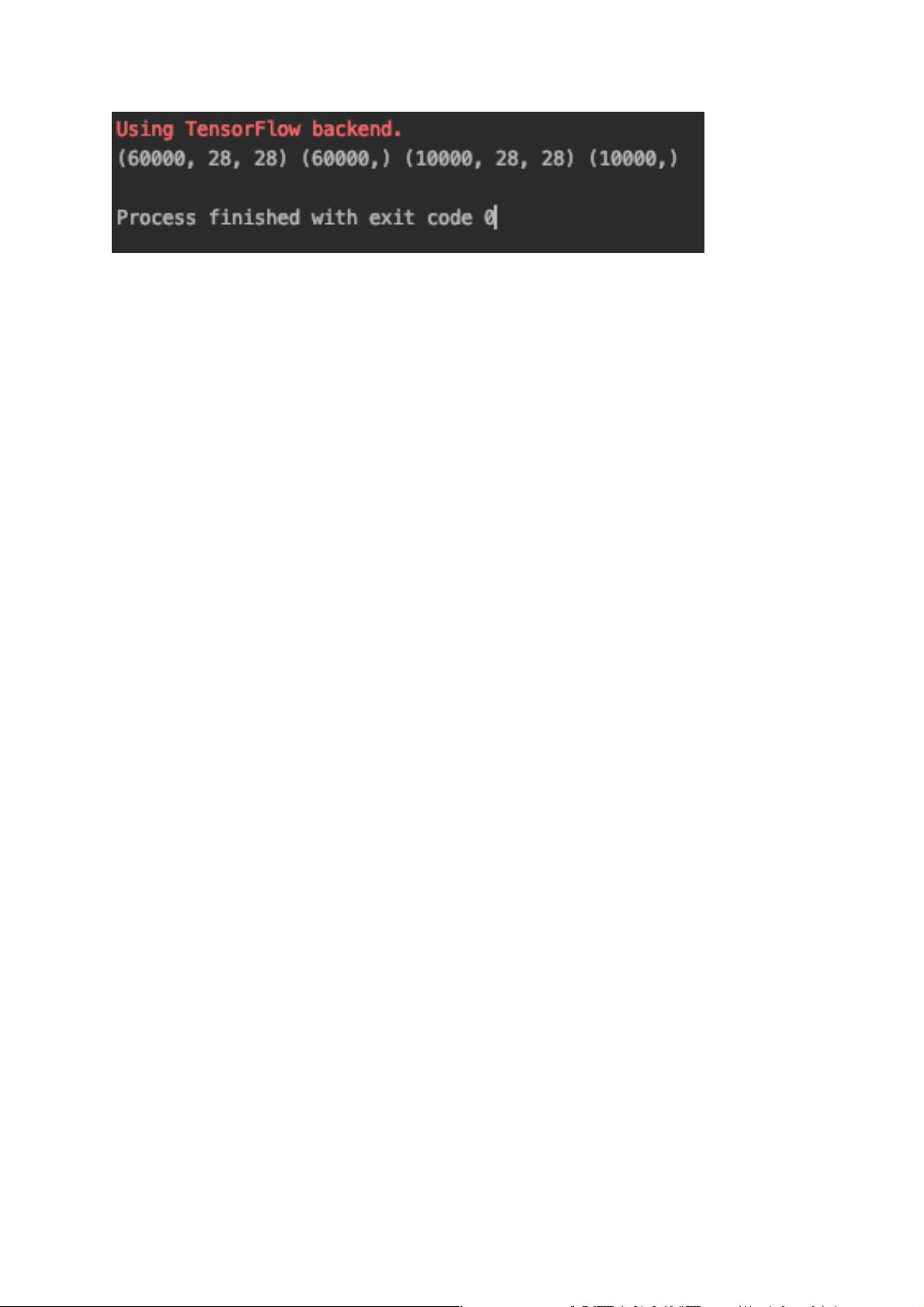
3.2 重塑训练集和测试集的形状
X_train 和 X_test 如上所示分别是 60000×28×28 和 10000×28×28 的形状的张
量,请通过 numpy 模块的 reshape 方法编程实现将其形状重塑为 60000×784,10000
×784,并使用 numpy 模块的 astype 方法将 X_train 和 X_test 的元素数据类型改为
float32。
然后请学员通过 print 方法结合 X_train/X_test 的 shape 和 dtype 属性编程实现
查看形状和数据类型是否正确。
提示 1:numpy 模块的 reshape 方法形式如下:
a.reshape(shape) : 不改变 numpy 数组 a 的元素,返回一个 shape 形状的数
组,原数组不变
例:a = np.arange(20)
#原数组不变
In [1]: a.reshape([4,5])
Out[1]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
提示 2: numpy 模块的数组对象的 astype 方法形式如下:
astype(dtype,order ='K',cast ='unsafe',subok = True,copy =
True)
参数 dytpe 表示需要转化的数据类型,其他参数都有缺省值,这里用不到,可以
不用管。
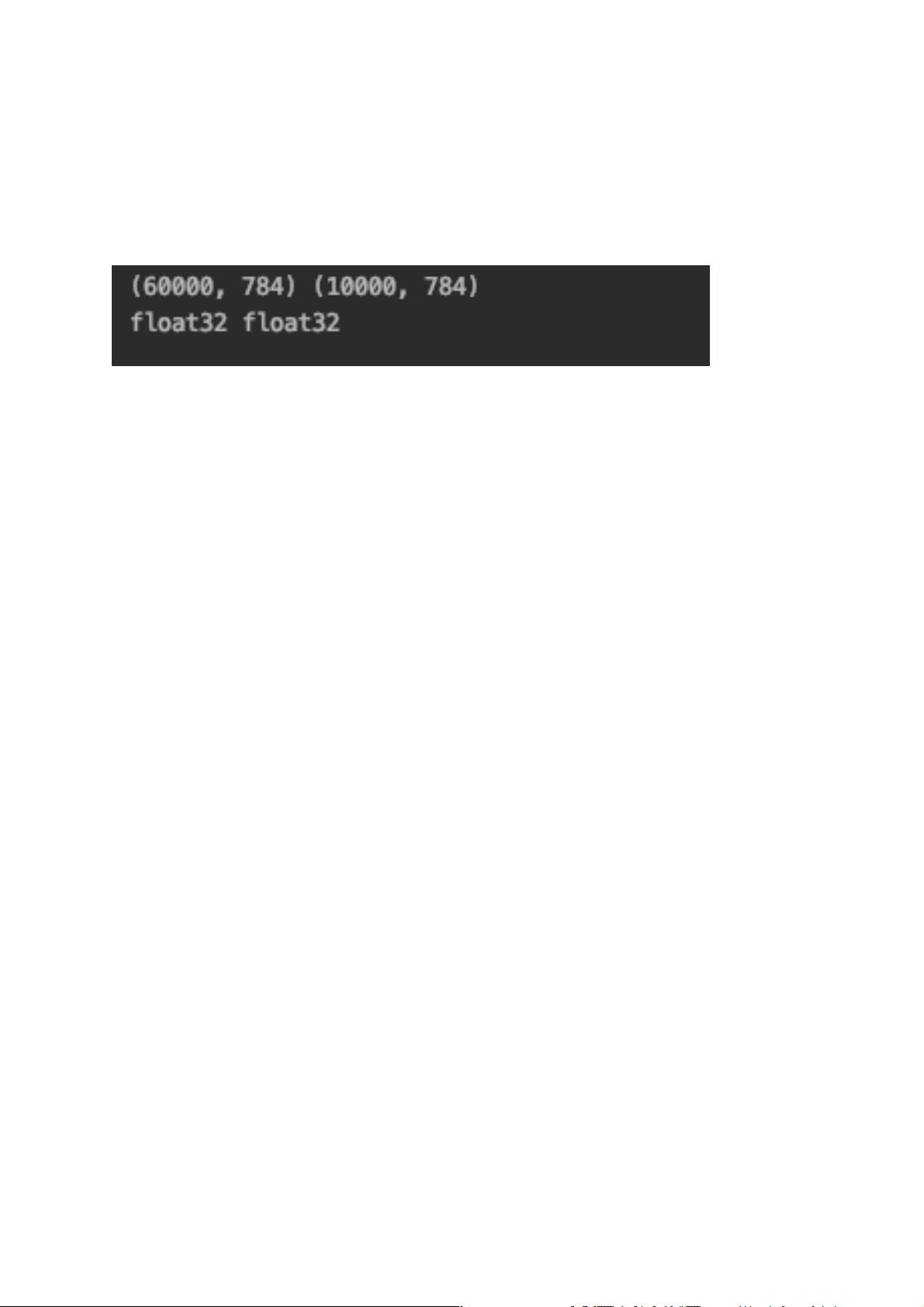
代码执行结果:
(60000,784)


剩余91页未读,继续阅读
2022-08-08 上传
2022-08-08 上传
2009-06-24 上传
2019-01-18 上传

莉雯Liwen
- 粉丝: 30
- 资源: 305
 我的内容管理
展开
我的内容管理
展开







