Apache Flink:流处理巨头的实战与探索
"Flink实践案例"
Apache Flink作为大数据处理领域的热门引擎,近年来获得了显著的增长。根据Qubole的报告,Flink在2018年的采用量比2017年增长了125%,这反映出其在设计上的优越性。Flink的崛起主要得益于它在流计算方面的突破,它解决了批处理引擎如Apache Spark在流计算上的局限。Spark Streaming通过快速批处理模仿流计算,但存在性能和功能限制,而Flink则提供了更好的状态管理和基于分布式一致性快照的检查点容错机制,从而在流处理领域展现出强大的能力。
Flink不仅限于流处理,还能够模拟批处理,并支持交互式查询和机器学习等多种数据处理场景,这使它与Spark形成了直接竞争。在实际应用中,像美团、唯品会、滴滴和360等国内互联网巨头都已经采用了Flink进行各种业务场景的处理。Flink的强大功能和不断改进的易用性,例如阿里巴巴贡献的Flink SQL,使其在业界得到了广泛的应用和认可。
Flink的快速发展和广泛应用代表了大数据计算技术的三代变迁,从最初的MapReduce,到Spark,再到现在的Flink,每个阶段都推动了技术的进步和应用的创新。Flink社区的活跃度和各大公司的支持为其持续发展奠定了基础。对于开发者来说,参与到Flink社区中,不仅可以见证技术的演进,还能抓住大数据技术变革的历史机遇。
在实际案例中,Flink展现了其在实时处理、故障恢复、高吞吐低延迟等方面的优势。例如,美团可能使用Flink进行实时订单分析,提供即时的业务洞察;唯品会可能利用Flink处理大量电商交易数据,优化库存管理和营销策略;滴滴可能会使用Flink监控和分析交通流量,提升出行服务效率;360可能运用Flink进行网络安全分析,提供更高效的威胁检测。
Flink作为一个全面的数据处理平台,其强大的流处理能力和扩展性吸引了众多企业采用,而其不断完善的生态和社区支持将进一步巩固其在大数据领域的地位。随着Flink的不断发展,我们可以期待更多创新的应用场景和解决方案出现,进一步推动大数据技术的革新。

11
不仅仅是流计算:Apache Flink
®
实践
本文来自于余海林在 2018 年 8 月 11 日 Flink China 社区线下 Meetup·北京站的分享。余海林
目前在滴滴出行负责实时流计算相关工作,研发主要是集中在 Apache Flink 上。之前任职于阿
里巴巴,主要负责 TCP/IP 协议栈以及手淘的无线网络优化。
本文主要内容主要包括以下几个方面:
1、 Apache Flink 在滴滴的背景
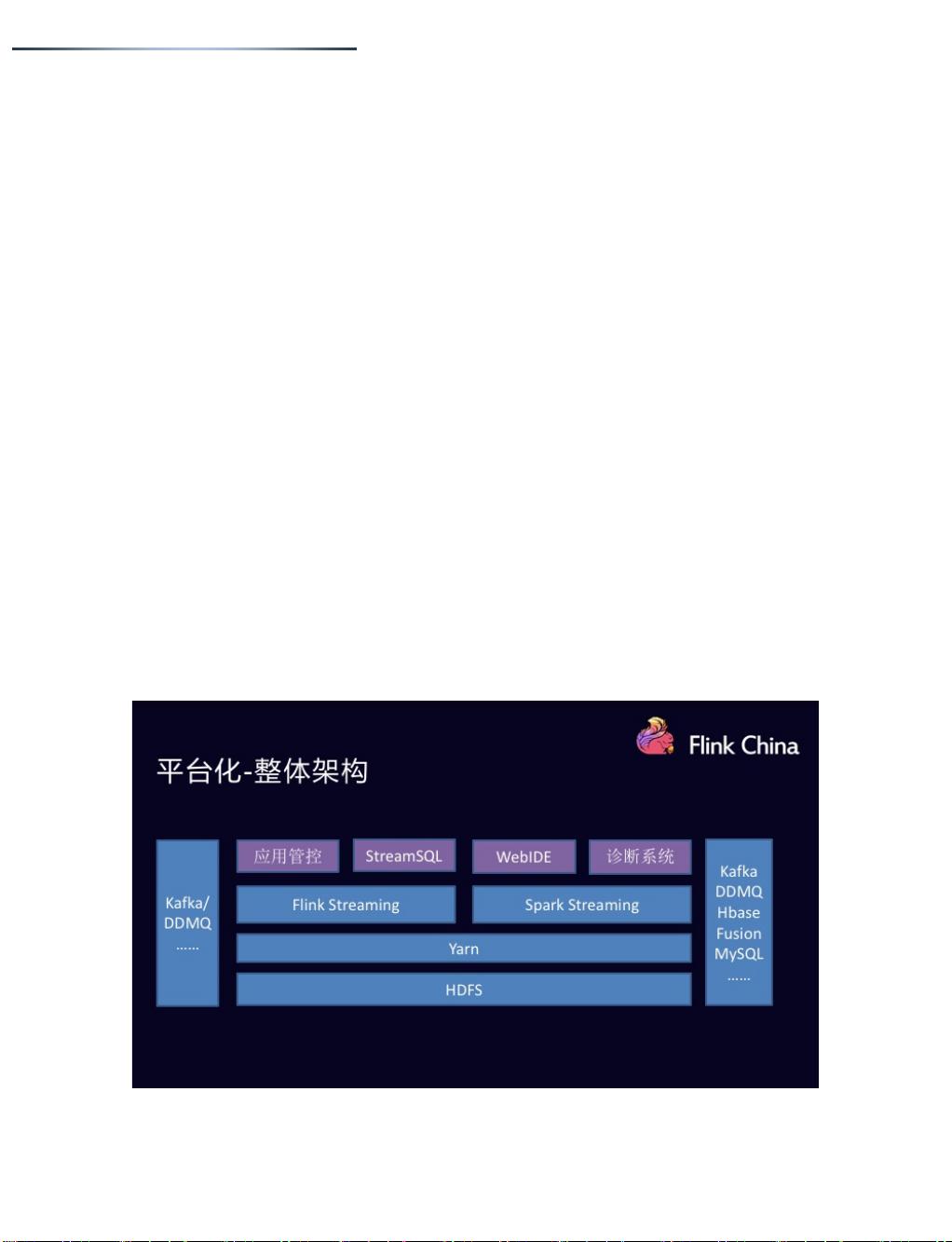
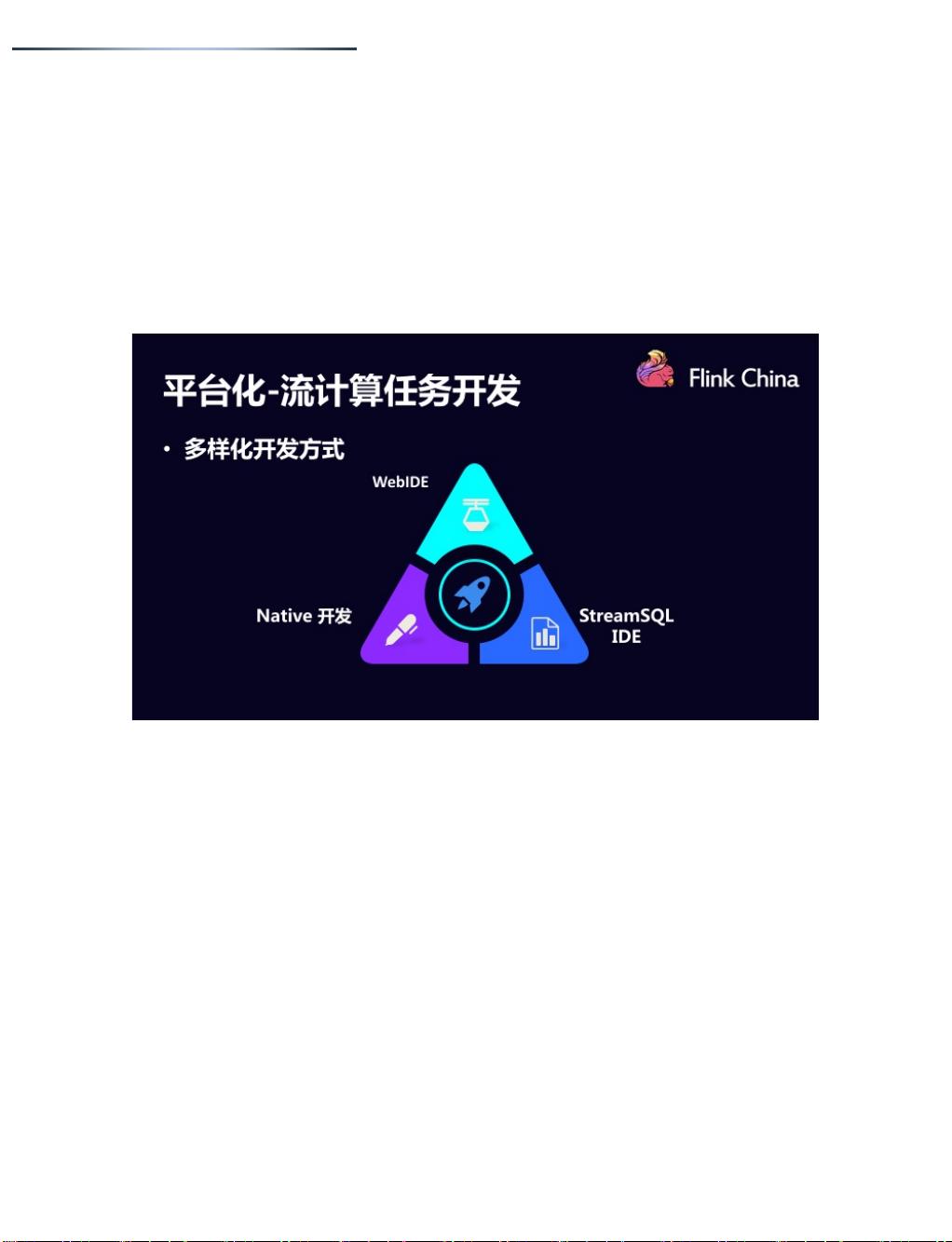
2、 Apache Flink 在滴滴的平台化
3、 Apache Flink 在滴滴的生产实践
4、 StreamSQL
5、 展望规划
Apache Flink 在滴滴
在滴滴,所有的数据基本上可以分为四个大块:
1、 轨迹数据:轨迹数据和订单数据往往是业务方特别关心的。同时因为每一个用户在打车以
后,都必须要实时的看到自己的轨迹,所以这些数据有强烈的实时需求。
2、 交易数据:滴滴的交易数据,
Apache Flink 在滴滴出行
的应用与实践
作者 余海林
整理 赵明远


剩余161页未读,继续阅读
2019-11-19 上传
2021-05-14 上传
2023-12-12 上传
2024-11-02 上传
2023-09-26 上传
2023-06-02 上传
2023-05-18 上传
2024-11-02 上传

阿华田512
- 粉丝: 1w+
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
