百度林仕鼎谈大数据系统架构:支持云计算与快速迭代
需积分: 10 19 浏览量
更新于2024-07-25
收藏 1.72MB PDF 举报
"第五届中国云计算大会聚焦于大数据的系统架构支持,由百度的林仕鼎分享了互联网服务的技术特点以及大数据在其中的作用。"
在第五届中国云计算大会上,百度的林仕鼎探讨了大数据的系统架构对互联网服务的重要支持。他指出,互联网服务具有几个显著的技术特点:超大规模、快速迭代和大数据规模。这些特点对系统的架构提出了严峻挑战。
首先,超大规模体现在数据总量上,可能达到100至1000PB,每天的数据处理量在千亿到万亿级别。这包括网页数量(百亿到千亿)、索引更新(十亿到百亿/天)以及日志生成(100TB到1PB/天)。如此庞大的数据量要求高效的存储和处理能力。
其次,快速迭代是互联网产品创新的关键。例如,搜索引擎的迭代过程中,会通过A/B测试比较算法A和B的效果,通过反馈来验证算法的优劣。这种迭代过程不仅限于搜索引擎,也广泛应用于各种互联网产品的开发,如从想法、原型到系统的快速开发、测试和部署运维。
百度自身的数据规模也反映了这些特点,包括离线和在线数据处理。离线分析与在线实验相结合,通过数据智能来驱动产品的优化。在线学习、A/B测试、特征训练和数据挖掘构成了这一过程的基础。
云计算技术体系在支持大数据处理中扮演了重要角色,包括数据智能、软件基础架构和大数据相关的数据中心、网络和服务器。在数据中心计算方面,主要的技术领域有超大规模系统、存储和计算,以及实时处理。
大数据架构需要应对不同访问模式,如结构化、非结构化和半结构化数据的访问。为了平衡大容量、高并发和低延迟的需求,需要建立统一的存储体系。此外,统一的访问与传输、分布式存储(如块存储、对象存储和文件存储)以及分布式计算也是关键组成部分。
在数据访问层,涉及内存、闪存和硬盘的多层次存储方案,以及分布式计算的描述能力、数据流优化、控制流管理等。执行层包含了MapReduce模型,以及SQL-like的表示层,支持Join、Select、Top等操作。
实时存储与计算是另一个重点,涵盖了分布式数据结构、kNN查询、向量计算引擎、流式数据处理引擎、复杂事件处理引擎、PubSub引擎、机器学习算法平台、OLAP引擎、超大规模数据仓库、图查询平台和实时检索平台等。这些技术共同构建了一个强大的实时数据处理和分析环境。
大数据的系统架构支持是云计算和互联网服务发展的核心,它推动了IT产业生产力的变革,使得硬件、软件和人结合,特别是随着数据的增加,加速了系统的迭代和进化。
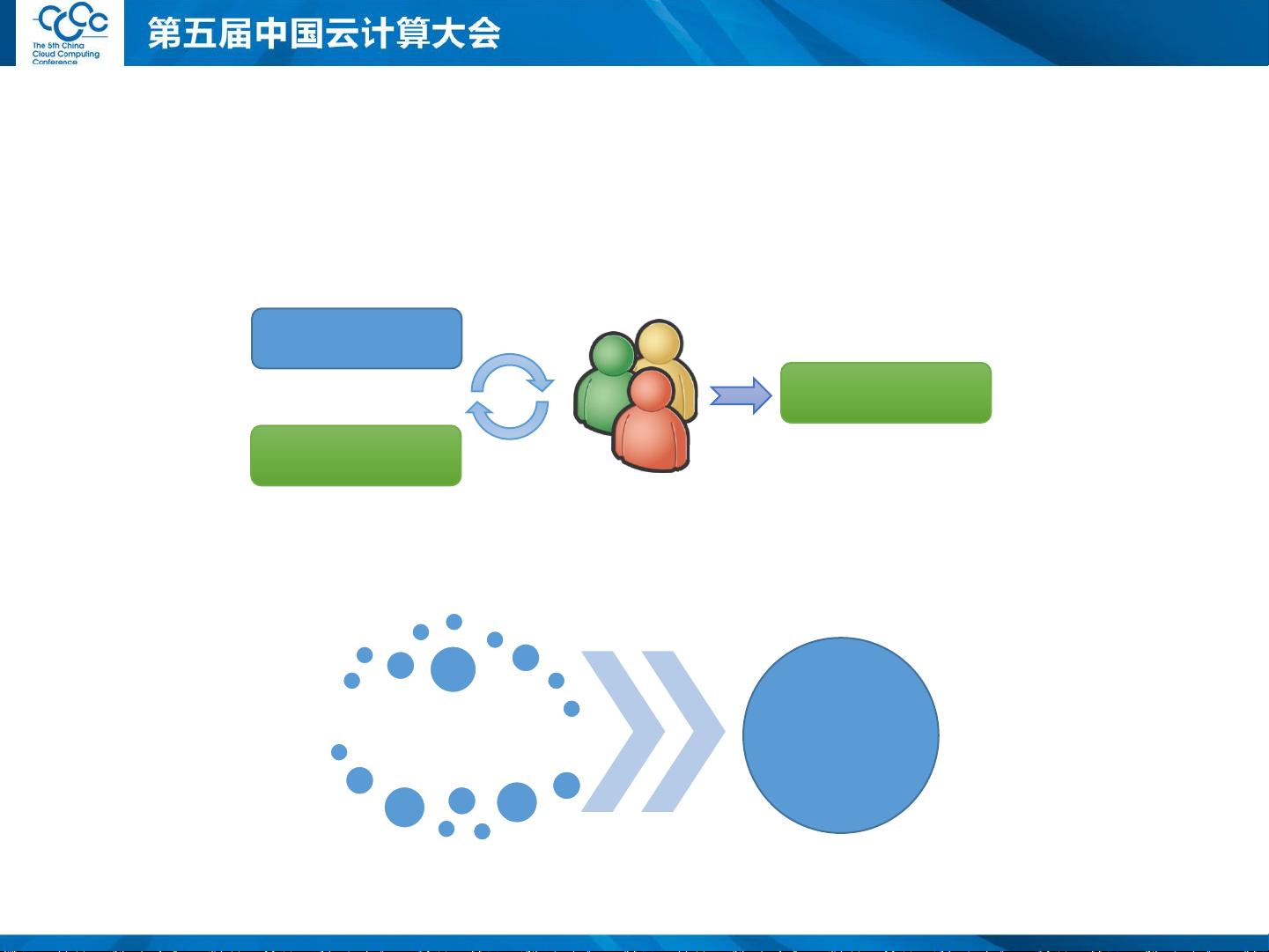
离线
在线
离线分析与在线实验相结合
通过反馈来验证算法优劣
算法A
算法B
算法B
快速迭代是互联网产品的
主要创新手段
剩余18页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-06-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
912 浏览量
2012-10-14 上传

cuigx1991
- 粉丝: 15
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
