TensorFlowOnSpark:分布式深度学习与Spark的结合
版权申诉
"TensorFlowOnSpark是一个由Yahoo开源的软件包,它将TensorFlow与Apache Spark集成,使得在Hadoop和Spark集群上实现可扩展的深度学习成为可能。该框架允许利用TensorFlow的深度学习功能和GPU加速计算,并解决了跨集群的数据传输问题。TensorFlowOnSpark的主要特点是能够轻松迁移现有的TensorFlow程序,同时支持同步/异步训练、模型/数据并行、inferencing以及TensorBoard。此外,它还允许Spark分发或由TensorFlow拉取HDFS和其他资源上的数据,便于整合现有的数据处理流程和机器学习算法。
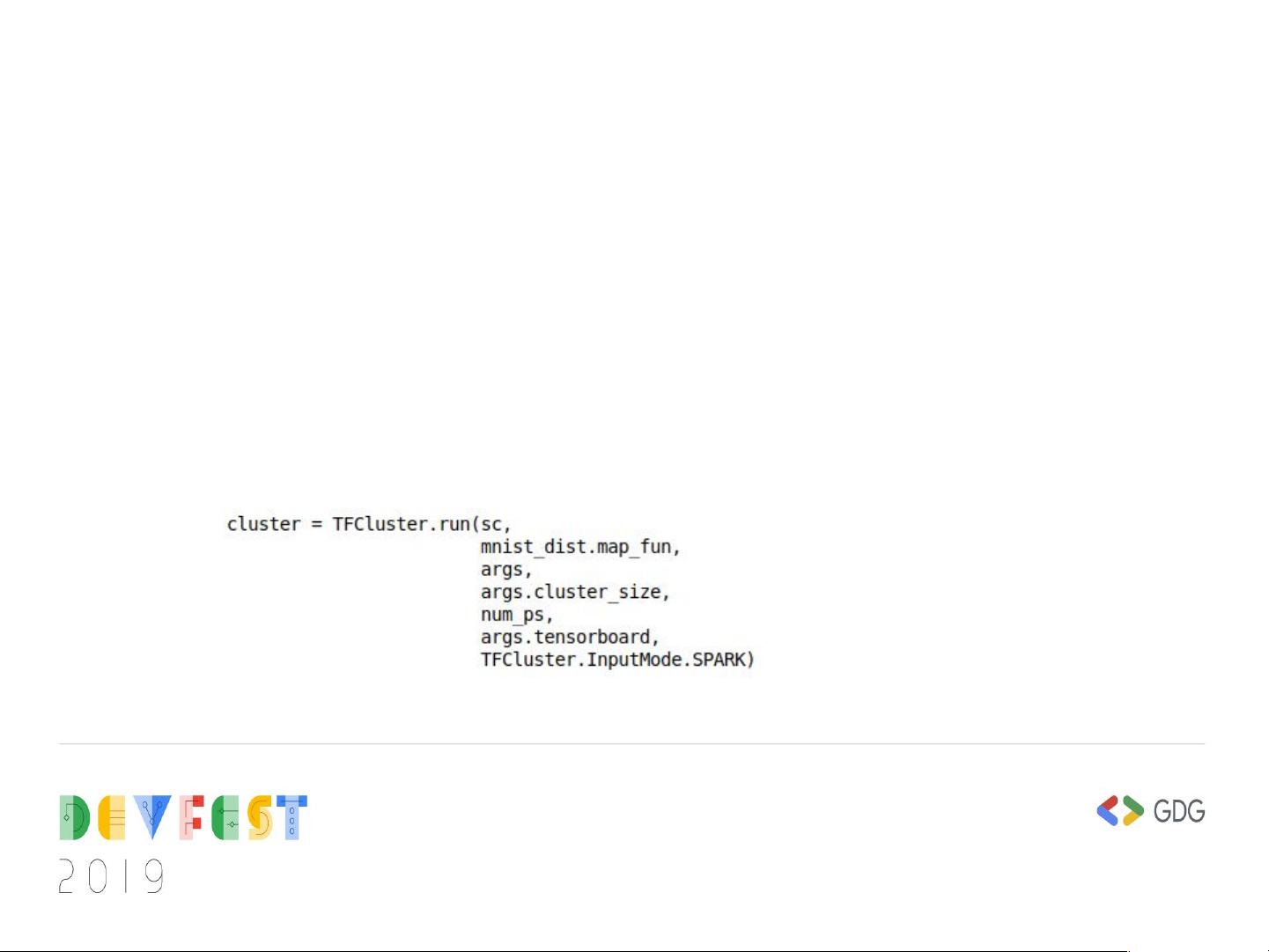
在架构上,TensorFlowOnSpark的核心API包括TFCluster.run,用于初始化TensorFlow集群,分配Worker节点和Parameter Server(PS)节点,构建TensorFlowCluster,并为每个TensorFlow进程分配GPU。TFCluster.train和TFCluster.inference是两个关键操作,前者用于在Spark输入模式下启动训练模型,后者用于定义模型推理的RDD并返回结果。
在使用TensorFlowOnSpark时,用户需要根据不同的输入模式选择合适的API。例如,InputMode.SPARK意味着数据将通过Spark RDD进入,而InputMode.TENSORFLOW则表示数据已经存在于TensorFlow环境中。用户需要在main方法中实现Spark输入模式下的数据处理逻辑,包括对RDD的处理和训练过程。
一个典型的Demo示例通常包括以下几个步骤:
1. 启动集群:创建并初始化TFCluster。
2. 喂入训练数据:使用Spark的RDD来提供训练数据。
3. 训练模型:调用TFCluster.train开始模型训练。
4. 关闭集群:训练完成后,使用TFCluster.shutdown关闭集群。
TensorFlowOnSpark的这种设计使得用户能够在大规模分布式环境下无缝地进行深度学习任务,同时保持与单机TensorFlow的兼容性,极大地提升了深度学习在大数据环境中的应用潜力。"
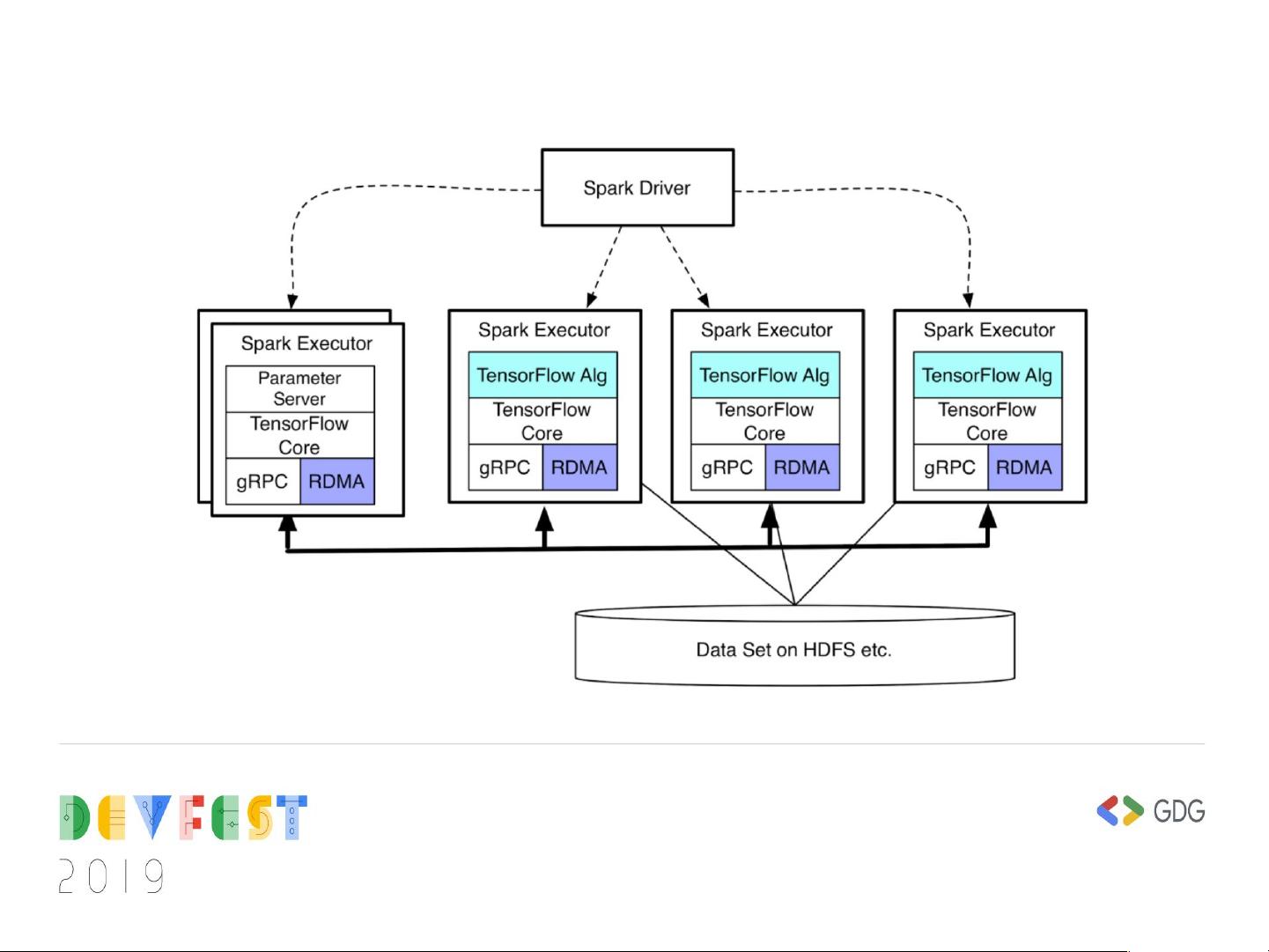
Runtime 架构
剩余35页未读,继续阅读
211 浏览量
204 浏览量
293 浏览量
293 浏览量
176 浏览量
2021-03-27 上传
2021-04-21 上传
204 浏览量
211 浏览量

herosunly
- 粉丝: 7w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 文档签名状态缓存系统的设计与实践
- Java 8最新版64位JDK 8u251下载指南
- 扩展GAMAKiDS研究:autoz_lens_model分析LinKS候选人
- AnyDesk 4.1.2:远程控制与文件传输新体验
- ActiveMQ中订阅模式持久化消息处理详解
- Obaforex网站开发指南:搭建和部署Next.js应用
- 87美元采购Magento数码电商模版详细评测
- MFC GDI+自绘环形百分比控件及牵引线实现
- 海康威视监控视频专用h264绿色播放器
- Postman桌面版发布:独立快捷的API测试工具
- 新手原创简单钢琴绘图代码分享
- SSH框架整合:Hibernate3、Spring2.5.6与Struts2
- meystingray.github.io:探索个人网站的构建与JavaScript应用
- 图片缩放示例:imageViewdemo动态演示
- Android SearchView布局实现与动画技巧
- 一站式观看:德奥影视大全在线影视播放软件
