利用未标记数据提取特权信息提升分类器性能
需积分: 5 5 浏览量
更新于2024-07-10
收藏 5.48MB PDF 举报
"提取特权信息以增强分类器学习"
在机器学习领域,数据的质量和数量对模型的准确性至关重要。然而,实际情况中,训练数据往往受限于量的不足或质量的低下。特权信息(Privileged Information, PI)作为一种额外的、有助于提升分类器性能的信息,如属性、标签或特性,通常被用来改善学习过程。例如,手动标注的属性可以提供更丰富的上下文信息,帮助模型更好地理解数据。但是,手动标注的过程既耗时又费力,而且受限于个人知识,可能会导致特权信息不够全面。
针对这些问题,本文提出了一种从未标记数据中自动探索特权信息来增强分类器学习的方法,旨在减少对人工标注数据的依赖并获取更为丰富的信息。具体来说,研究者将每个选取的特权信息视为一个子类别,并为每个子类别独立学习一个分类器。这些子类别的分类器随后会集成在一起,形成一个更为强大的类别分类器。这种方法的核心思想是利用未标记数据中的潜在结构和模式,以无监督或弱监督的方式挖掘出有价值的特权信息。
在论文中,作者Yazhou Yao、Fumin Shen、Jian Zhang等人探讨了如何有效地从未经标注的语料库中提取这些信息。他们可能采用了某种形式的半监督学习或者自监督学习策略,通过分析数据内在的分布和关系,推断出代表性的特征。这种特性使得模型能够在没有大量人工标注的情况下,依然能够学习到数据的深层次特征,从而提高整体的分类性能。
此外,文章可能还涉及了如何评估和验证这种方法的有效性,可能包括在各种基准数据集上的实验,比较有无特权信息情况下分类器的性能差异,以及与现有方法的对比。这通常涉及到精确率、召回率、F1分数等指标的计算,以量化模型的分类效果。
这篇研究论文提出了一个创新的解决方案,以自动化的方式从海量未标记数据中挖掘特权信息,减轻了对人工标注的依赖,增强了分类器的学习能力,对于提升机器学习模型在有限或低质量训练数据条件下的表现具有重要的理论和实际意义。
438 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 28, NO. 1, JANUARY 2019
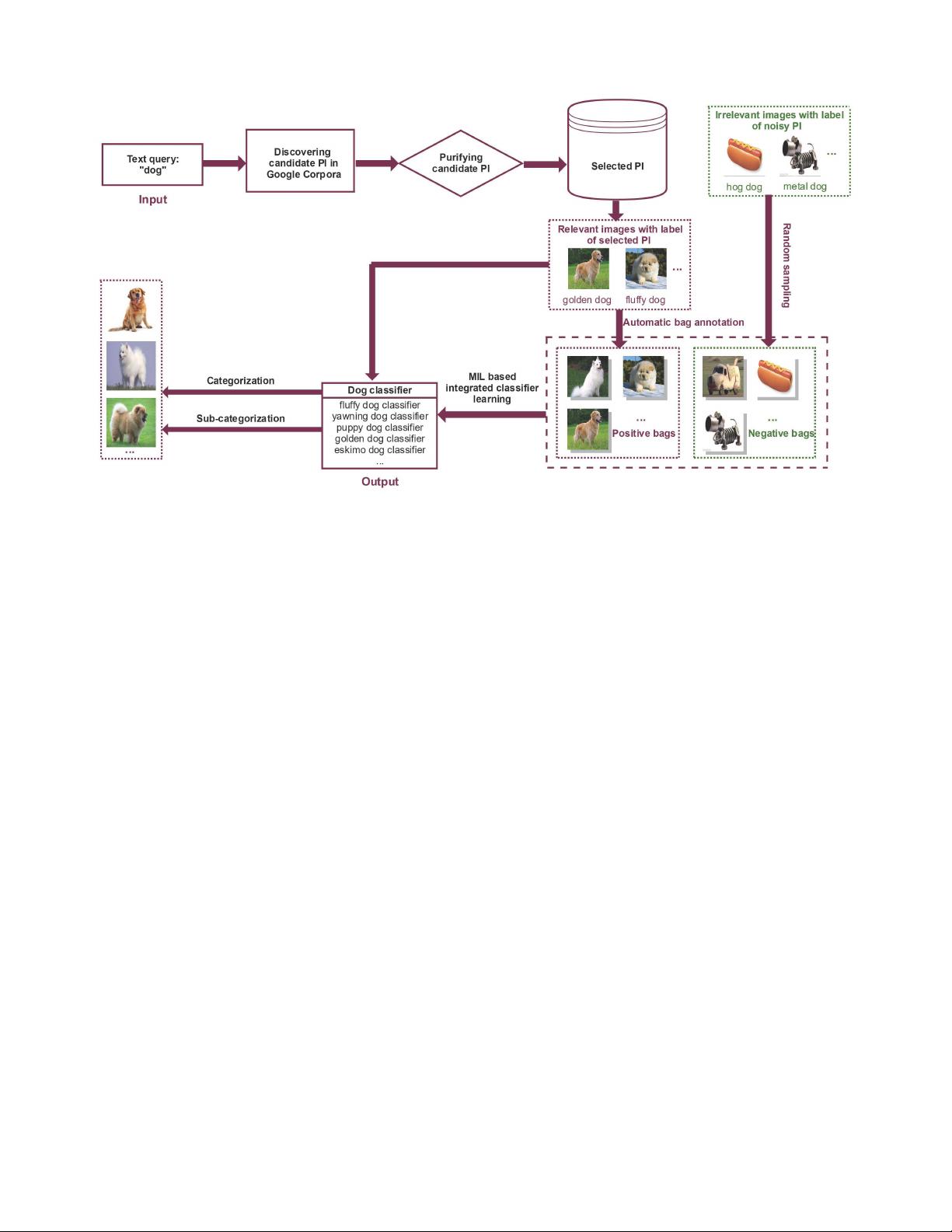
Fig. 2. System overview. Our proposed approach mainly consists of three major steps. Namely, discovering PI, purifying PI, and learning integrated classifier.
proposed in [12]. However, both of [7] and [12] only use the
visual features. In our work, we associate the “bags” with
textual privileged information and propose a new MIL model
to select images and learn the optimal classifiers.
Our work is primarily inspired by the following work.
A visual concept learning system was recently proposed
in [15] and achieved impressive accuracy for object detec-
tion. It discovers an exhaustive vocabulary explaining all the
appearance variations from Google Books Corpora, and trains
full-fledged detection models for it. The differences between
us lie in two aspects. First, we adopt different approaches to
filter out the noisy privileged information. Second, we lever-
aged different strategies to purify the collected web images.
Compared to method [15] which takes an iterative mecha-
nism in the process of noisy images pruning, our method
formulates noisy images removing as an instance-level multi-
instance learning problem. In this way, images from different
distributions can be kept while noise is filtered out.
III. F
RAMEWORK AND METHODS
We seek to automate the process of learning robust classi-
fiers directly from the web data without human intervention.
As shown in Fig 2, our proposed approach mainly consists
of three major steps. Namely, discovering privileged informa-
tion, purifying privileged information, and learning integrated
classifier. In the next, we will give the details of each step.
For ease of presentation, we denote each instance as x
i
with
its label y
i
and each bag G
m
with the label Y
m
. A matrix/vector
is denoted by an uppercase/lowercase letter in boldface. The
transpose of a vector or matrix is represented by
.More-
over, we denote the indicator function as λ(a=b), in which
λ(a=b)=0ifa= b, and λ(a=b)=1, otherwise.
A. Discovering Privileged Information
Inspired by recent works [15], [21], we can use Google
Books Corpora [27] to discover an exhaustive vocabulary
explaining all the appearance variations for the given category.
Compared to manually labeled WordNet [44] and Concept-
Net [49], it is not only much richer but also more general and
exhaustive.
Following [27] (see section 4.3), we specifically treat the
dependency gram data with parts-of-speech (POS) as the
privileged information. For example, given a category (e.g.,
“horse”) and its corresponding POS tag (e.g., ‘jumping,
VERB’), we find all its occurrences annotated with POS
tag within the dependency gram data. Of all the n-gram
dependencies retrieved for the given category, we choose
those whose modifiers are NOUN, VERB, ADJECTIVE, and
ADVERB as the discovered privileged information.
B. Purifying Privileged Information
Not all the discovered privileged information is useful, and
some noise may also be included. In the second PI purifying
step, the so-called “noise” here is the text PI from untagged
corpora (e.g., the bold privileged information in Table I). Using
noisy privileged information to enhance classifier learning will
hurt both of the accuracy and robustness. To this end, we need
to separate useful privileged information from noise before
learning classifiers.
Our basic idea is to filter out the noisy privileged informa-
tion from the perspective of relevance. Specifically, we denote
the semantic distance of all discovered privileged information
by a graph in which the given category (e.g., “dog”) is center
y. Other discovered privileged information has a score S
xy
corresponds to the Normalized Google Distance (NGD) [2]
剩余14页未读,继续阅读
2020-12-31 上传
119 浏览量
2023-12-20 上传
2023-06-11 上传
2023-02-19 上传
2023-06-13 上传
2023-05-13 上传
2023-06-11 上传

weixin_38502929
- 粉丝: 7
- 资源: 959
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
