




构建实时日志分析系统:Flume-Kafka-Storm集成教程
需积分: 12 3 浏览量
更新于2024-09-09
收藏 677KB PDF 举报
"本资源详细介绍了如何利用flume+kafka+storm搭建实时日志分析系统,涉及大数据处理的关键组件和安装配置步骤。"
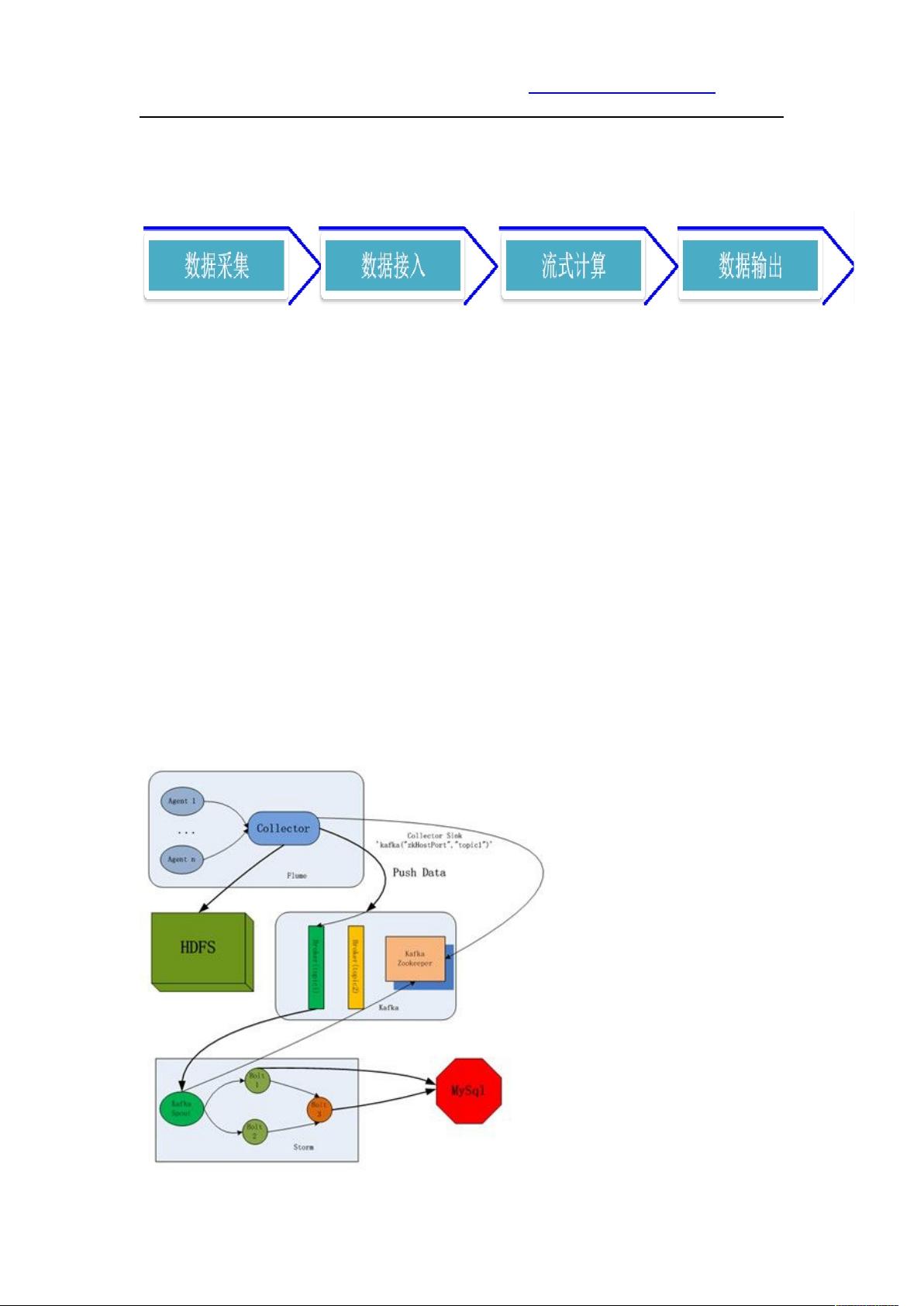
在大数据处理领域,构建实时日志分析系统是一个重要的任务,该系统通常由四个关键部分组成:数据采集、数据接入、流式计算和数据输出。在本文中,我们探讨了使用Apache Flume、Kafka和Storm这三种开源工具来搭建这样一个系统。
1. 数据采集:Flume作为数据采集工具,它是一个分布式、可靠且高可用的日志收集系统,可以从各种数据源(如控制台、文件、syslog等)收集数据,并将其发送到指定的目标。在本案例中,选择了使用exec方式来采集日志。
2. 数据接入:Kafka作为一个消息中间件,起到缓冲作用,以确保数据采集的速度与处理速度之间的平衡。Kafka支持高吞吐量的发布订阅模式,使得数据能够在多个消费者之间高效地分发。
3. 流式计算:Apache Storm负责对采集到的数据进行实时分析,它是一个用于实时处理的分布式计算系统,可以保证每个事件的处理时间,并且能够处理无边界数据流。
4. 数据输出:分析后的结果需要持久化存储,这里选择MySQL作为数据输出的目标,可以将结果存储在数据库中以便后续的查询和分析。
在具体实施过程中,首先需要在CentOS 6.4操作系统上进行环境准备。然后,安装Flume 1.4.0,解压后将其放置在指定目录,如`/usr/local`。启动Flume时,需要指定配置文件路径和日志级别。例如,启动命令如下:
```
$ bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console
```
Kafka和Storm的安装配置也类似,需要下载相应版本,配置环境变量,并根据项目需求设置各自的配置文件。在Kafka中,需要配置生产者和消费者的设置;在Storm中,需要定义拓扑结构和处理逻辑。
通过Flume+kafka+storm的组合,可以构建出一套强大的实时日志分析系统,适用于大规模分布式环境下的日志监控和实时数据分析。这个系统不仅能够高效地处理大量日志数据,还具有良好的扩展性和容错性,是大数据领域中常见的实时处理解决方案。
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
143 浏览量
203 浏览量
216 浏览量
709 浏览量
554 浏览量
174 浏览量

dch215810
- 粉丝: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Delphi 7.0函数速查:数据类型转换与操作详解
- Oracle基础操作常见问题解答1000例
- EJB3.0入门经典:从基础到实战详解
- 理解与编写Makefile:从基础到高级技巧
- Head First C#中文版第四章翻译完成:深入解析数据类型
- C++实现的BP神经网络算法教程:示例与权值更新
- 浙大概率与数理统计3版课后习题答案PDF版
- QTP入门教程:中文实战指南
- AspectJ编程指南:从入门到实践
- ZZPDM设计院工程数据管理系统与SUN日照分析软件
- Spring开发指南(中文版):开源PDF详解
- Java开发宝典:Eclipse基础入门与环境设置
- 全面解析:集成电路封装类型发展历程与QFP特性
- Java网络编程基础教程
- WF4.0深度解析:新一代工作流技术与应用
- Ruby语言入门教程v1.0:快速掌握编程基础





















