Keras优化器详解:从基本到Adam的全面解读
需积分: 48 59 浏览量
更新于2024-09-07
2
收藏 866KB DOCX 举报
Keras优化器详解是一份深入讲解深度学习框架Keras中用于调整模型权重以最小化损失函数的优化算法的详尽指南。优化器是深度学习中至关重要的组件,因为它们负责引导模型沿着梯度方向调整参数,以找到最小化损失的路径。
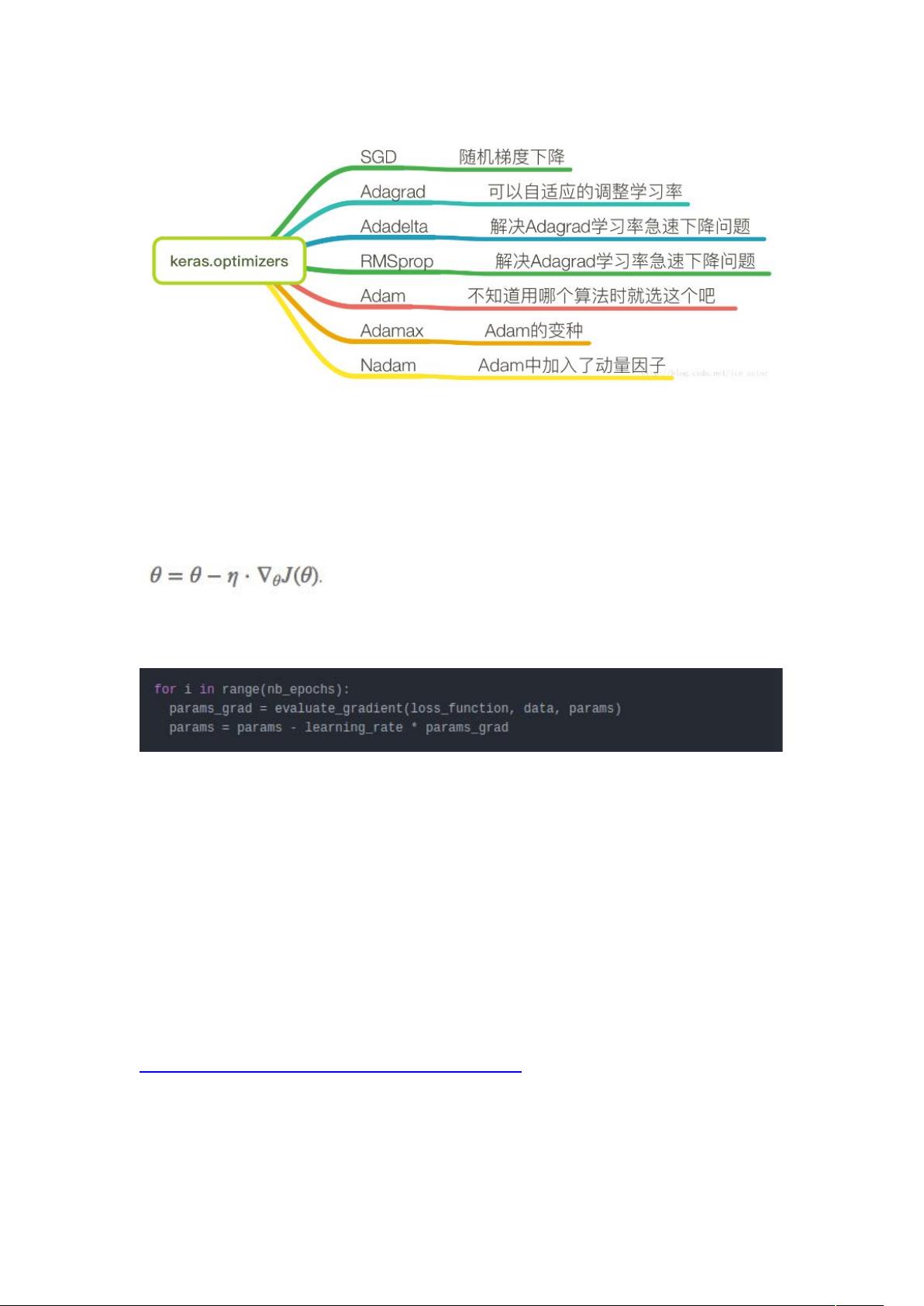
首先,优化方法主要分为基于梯度的优化策略:
1. **梯度下降**:基础的优化算法,试图通过迭代更新参数以减小损失函数。有三种主要变体:
- **批量梯度下降 (Batch Gradient Descent, BGD)**:每次更新使用整个训练集的数据计算梯度,适合数据集较小且计算资源充足的情况。
- **随机梯度下降 (Stochastic Gradient Descent, SGD)**:每次更新仅用一个样本,速度较快但可能跳过局部最小值。
- **小批量梯度下降 (Mini-batch Gradient Descent, MBGD)**:结合了前两者,使用一部分样本进行更新,平衡了效率和稳定性。
2. **动量 (Momentum)**:引入动量概念,利用历史梯度的平均值来加速学习过程,减少震荡,有助于跳出局部最优。
3. **Adagrad**:自适应学习率算法,根据每个参数的历史梯度变化动态调整学习率,适用于稀疏数据。
4. **Adadelta**:Adagrad的改进版,除了自适应学习率,还考虑了梯度平方的一阶累积,进一步适应不同参数的变化。
5. **RMSprop**:均方根传播,结合了动量和Adagrad的优点,对长期的梯度变化进行指数加权平均。
6. **Adam**:一种结合了动量和RMSprop的优化器,具有良好的收敛性和稳定性能,是深度学习中常用的默认优化器。
**优化器选择**:针对不同的任务和模型特性,选择合适的优化器至关重要。例如,对于非凸优化问题,如深度神经网络,Adam因其自适应性通常表现良好。而对于某些特定场景,如稀疏数据,Adagrad可能更有效。
**损失函数**:衡量模型预测值与真实值之间的差异,如均方误差、交叉熵等,目标是使损失函数达到最小,反映模型性能。
**近似最小化**:在多峰或多局部最小值的问题中,优化算法可能不能保证找到全局最优解,但接近最优的解也能带来显著的性能提升。
**神经网络中的挑战**:随机梯度下降对初始值敏感,合适的初始化策略和梯度噪声处理是关键。数值梯度和解析梯度的对比可以帮助校准和提高精度。
理解Keras优化器的种类、工作原理和选择策略对于深度学习模型的训练效果有着决定性的影响。通过掌握这些优化技术,能够有效地调整模型参数,提高模型的性能和学习效率。
1. 批量梯度下降 Batch gradient descent(BGD)
梯度更新策略:采用整个训练集的数据来计算 4对参数的梯度
缺点:一次更新中就要对整个数据集计算梯度,计算速度非常慢,遇到大规模数据集会非
常棘手,而且不能投入新数据实时更新模型。
我们会事先定义一个迭代次数 &,首先计算梯度向量 &:,然后沿着 梯度的
方向更新参数 &,#:决定了我们每一步迈多大上文提到的 步长
9。() 对于凸函数可以收敛到全局极小值,对 于非凸函数
可以收敛到局部极小值。
2. 随机梯度下降 Stochasc gradient descent(SGD)
)&*++#+;;<3:&+#+#+ $'
梯度更新规则:和 的一次用所有数据计算梯度相比,每次更新时对每个样本进行
梯度更新,对于很大的数据集来说,可能会有相似的样本,这样 在计算梯度时会出现
冗余,而 一次只进行一次更新,就没有冗余,而且比较快,并且可以新增样本。
剩余11页未读,继续阅读
2020-09-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

NODIECANFLY
- 粉丝: 22
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- wadegao.github.io:韦德高的个人主页
- pcsetup:从零开始设置我的个人计算机的脚本
- A2G-2020.0.1-py3-none-any.whl.zip
- 升降台程序11.rar
- MDN-note
- Kyhelper:考研助手,利用了Bmob移动后端云服务平台和腾讯旗下的微社区,感谢imooc网和校园小菜的技术指导。 给考研学子们提供一个方便的工具,可以让他们收起鼠标和键盘,逃离喧闹狼藉的宿舍,在自习室里用手机就能查看大部分最重要的考研相关信息。在考研备考过程中要时常打开电脑上网到处浏览与考研相关的信息,生怕错过什么重要通知,那么,如果能有这么一款手机应用,它能够给考研学生带来一定的帮助,成为学子贴身的考研小助手,从而使他们更好地高效率的投入到自己的复习当中。 比如说,看书累了
- michaelkulbacki.github.io:我的个人网站上展示了我的计算机科学项目和摄影作品
- gmod-Custom_FOV:Garry Mod的插件,可以更改fov值
- wfh.vote
- minesweeper-cljs:使用leiningen和figwheel在ClojureScript中实现扫雷游戏的实现
- 2013-2019年重庆理工大学825管理学考研真题
- gulp-font2css:使用 Gulp 将字体文件编码为 CSS @font-face 规则
- 3.14159.in:pi数字的彩色渲染
- AABBTree-0.0a0-py2.py3-none-any.whl.zip
- DataMiningLabTasks
- 机器学习文档(transformer, BERT, BP, SVD)
