理解与实现策略梯度:REINFORCE算法解析
需积分: 5 157 浏览量
更新于2024-08-04
收藏 2.12MB PDF 举报
"这篇资源主要介绍了强化学习中的策略梯度算法,特别是REINFORCE方法,以及如何通过神经网络实现策略的表示和优化。"
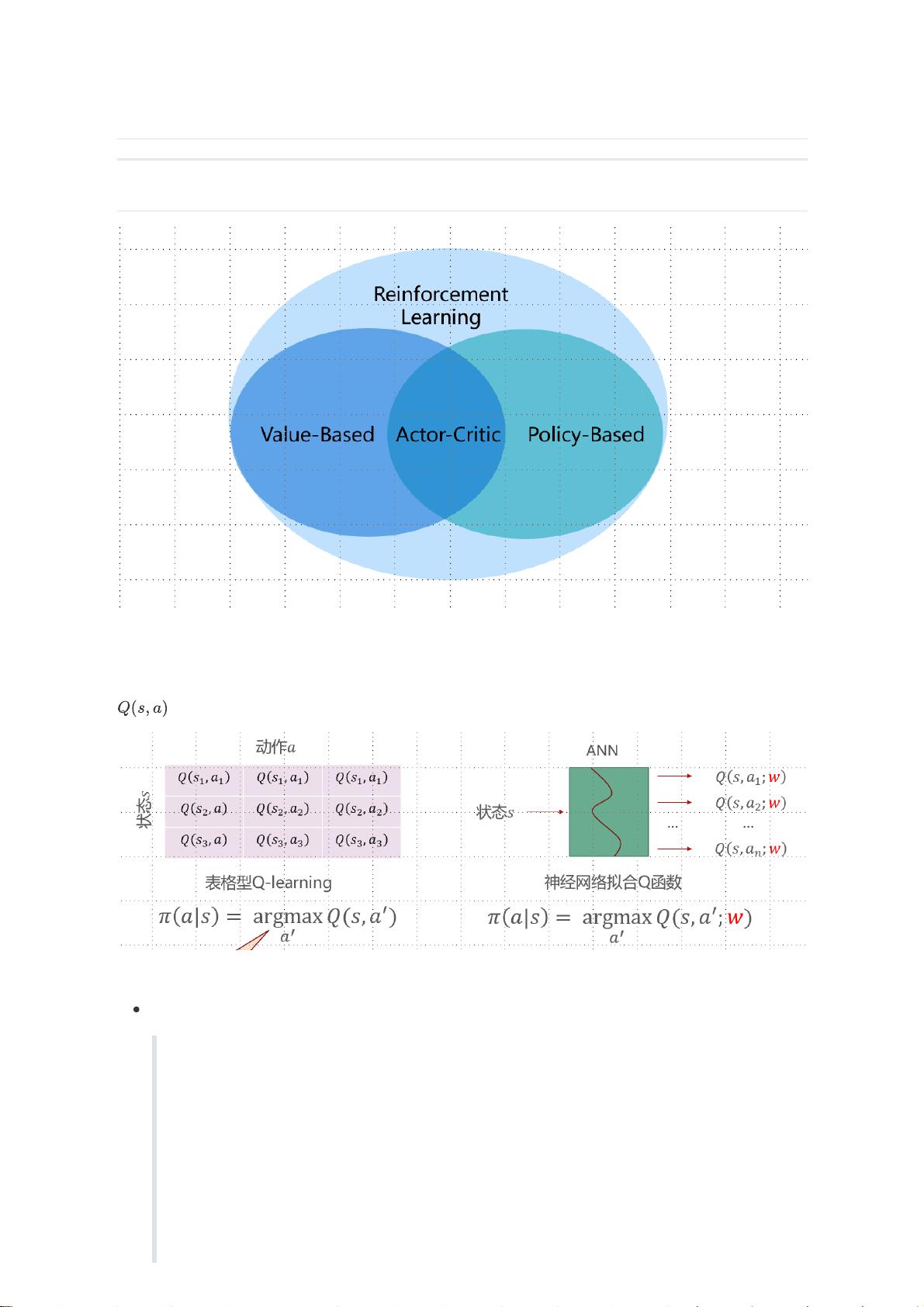
在强化学习中,REINFORCE算法是一种策略梯度方法,它直接优化策略函数,适用于解决那些基于价值函数方法难以处理的问题,如需要随机策略或连续动作空间的场景。传统的基于价值的方法,如Q-learning,DQN等,虽然能够找到最优策略,但它们往往不能产生非确定性的策略,这在某些游戏中可能是不利的,例如"石头-剪刀-布",因为对手可能会学习到这些模式并做出反应。此外,对于连续动作空间的问题,如无人机控制,直接优化策略更符合实际需求。
策略梯度算法中,策略π是一个从状态到动作的概率分布的映射。对于离散动作空间,策略通常采用softmax函数将神经网络的输出转化为概率。而在连续动作空间,策略则输出一个具体的数值,比如Cart-Pole问题中,网络输出力的大小和方向。为了确保动作的合法性,可以使用如tanh函数限制输出,并在训练时引入噪声,通过采样动作的高斯分布来增加探索性。
在REINFORCE算法中,策略π的参数θ被逐步更新以最大化累积奖励。基本思想是计算每个时间步的策略梯度,这个梯度是期望回报与动作概率的乘积。公式表示为:
梯度 = E[ G_t * ∇_θ log π(a_t|s_t;θ) ]
其中,G_t是时间步t到T的累计回报,π(a_t|s_t;θ)是状态s_t下采取动作a_t的概率,∇_θ是关于θ的梯度。这个梯度指向了使得回报增加的方向,从而更新策略参数。
在实现代码中,可能会包含以下步骤:
1. 初始化策略网络的参数θ。
2. 在环境中交互,收集经历的轨迹(包括状态s,动作a,奖励r)。
3. 计算每个轨迹的累计回报G。
4. 对于每个时间步,计算梯度并更新网络参数,可能使用优化器如Adam进行梯度下降。
5. 可能会包含策略平滑(如指数移动平均)和奖励缩放等技术来稳定训练过程。
在实践中,策略梯度算法可能会遇到梯度消失或爆炸的问题,以及训练初期的不稳定。为了改善这些问题,可以采用各种技术,如Actor-Critic方法,使用价值函数来稳定策略更新,或者应用gae(Generalized Advantage Estimation)来改进回报的估计。
REINFORCE提供了一种直接优化策略的框架,适用于解决具有连续动作或需要随机性策略的问题。通过神经网络和策略梯度,我们可以学习到适应复杂环境的策略,并通过实际的代码实现来训练智能体。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-03-21 上传
2022-10-17 上传
2022-06-29 上传
2018-08-27 上传
2019-03-09 上传
137 浏览量

二向箔不会思考
- 粉丝: 5975
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
