深入理解Hadoop集群与网络架构
需积分: 9 58 浏览量
更新于2024-07-26
收藏 2.74MB PDF 举报
"深入理解Hadoop集群及其网络架构"
在大数据处理领域,Hadoop是一个至关重要的开源框架,它被广泛用于存储和处理海量数据。本文是关于Hadoop集群及其网络结构系列的第一部分,主要基于学术研究和与运行实际生产集群客户的讨论。如果你正在数据中心运行生产级的Hadoop集群,那么这篇文章将提供一些基本的理解,同时也欢迎你在评论区分享宝贵的经验。后续的文章将更深入地探讨服务器和网络架构选项。
在Hadoop部署中,机器角色主要分为三类:客户端机器、主节点和从节点。这三种角色协同工作,确保Hadoop能够高效地执行其核心功能——存储大量数据(Hadoop分布式文件系统,HDFS)和并行计算这些数据(MapReduce)。
1. 客户端机器(Client Machines):
客户端是用户交互的接口,它们提交作业到Hadoop集群,并接收处理结果。客户端可以是任何需要访问Hadoop服务的程序或工具,例如数据分析师使用的数据分析应用,或者是数据导入/导出工具。
2. 主节点(Master Nodes):
主节点负责管理和协调整个Hadoop集群的运行。主节点分为两种关键角色:NameNode和JobTracker。
- NameNode(名称节点):
是HDFS的核心组件,负责管理文件系统的命名空间和文件块的映射信息。它维护元数据,包括文件和目录的创建、删除、重命名等操作,以及文件块与数据节点的对应关系。NameNode的高可用性通常通过使用备份NameNode(Secondary NameNode)来实现,以定期保存和恢复元数据的检查点。
- JobTracker(任务追踪器):
在MapReduce框架中,JobTracker负责调度作业的执行,分配任务给TaskTracker,监控任务进度,并处理失败的任务。YARN(Yet Another Resource Negotiator)引入后,JobTracker的功能被拆分为ResourceManager(资源管理)和ApplicationMaster(应用管理),分别处理集群资源的全局管理和应用程序的局部调度。
3. 从节点(Slave Nodes):
从节点主要包括DataNodes和TaskTrackers,它们是Hadoop集群的执行层。
- DataNodes(数据节点):
数据节点是HDFS的物理存储单位,它们负责存储数据块,并根据NameNode的指令进行数据的读写操作。DataNodes会周期性地向NameNode发送心跳信息以报告状态,并在NameNode需要时提供块信息。
- TaskTrackers(任务追踪器):
在MapReduce阶段,TaskTrackers接收JobTracker分配的任务,将任务分解为map任务和reduce任务,并在本地DataNode上执行。每个TaskTracker可以同时运行多个map或reduce任务。在YARN中,TaskTracker被Container取代,每个Container可以运行一个任务实例。
了解了这些基础概念之后,我们可以进一步探讨Hadoop集群的网络架构,包括如何优化网络拓扑以支持高效的通信,以及如何利用硬件和软件技术提高集群性能。例如,网络带宽、延迟、网络拓扑设计(如胖树、平面网络或Flattened Butterfly)和RDMA(远程直接内存访问)技术在Hadoop集群中的应用。此外,Hadoop的高可用性和容错机制,如HDFS的副本策略和故障切换,也是确保集群稳定运行的关键方面。
Hadoop集群的成功运行依赖于合理的设计和配置,包括正确选择和部署主节点、从节点以及优化网络架构。理解这些基础知识,有助于我们更好地管理和优化Hadoop集群,以满足不断增长的数据处理需求。
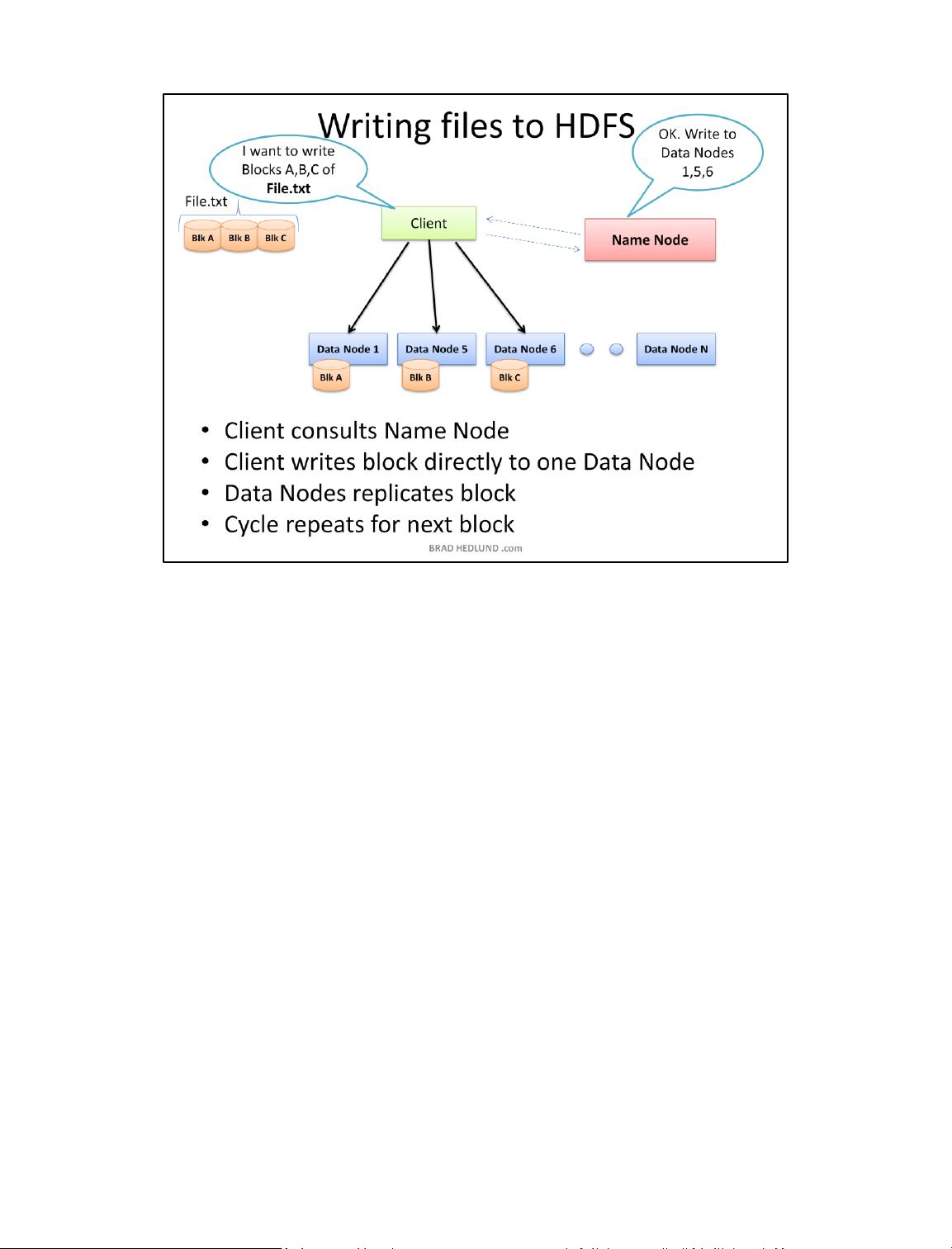
Your Hadoop cluster is useless until it has data, so we'll begin by loading our huge File.txt
into the cluster for processing. The goal here is fast parallel processing of lots of data. To
accomplish that I need as many machines as possible working on this data all at once. To
that end, the Client is going to break the data file into smaller "Blocks", and place those
blocks on different machines throughout the cluster. The more blocks I have, the more
machines that will be able to work on this data in parallel. At the same time, these
machines may be prone to failure, so I want to insure that every block of data is on multiple
machines at once to avoid data loss. So each block will be replicated in the cluster as its
loaded. The standard setting for Hadoop is to have (3) copies of each block in the
cluster. This can be configured with the dfs.replication parameter in the file hdfs-site.xml.
The Client breaks File.txt into (3) Blocks. For each block, the Client consults the Name
Node (usually TCP 9000) and receives a list of (3) Data Nodes that should have a copy of
this block. The Client then writes the block directly to the Data Node (usually TCP
50010). The receiving Data Node replicates the block to other Data Nodes, and the cycle
repeats for the remaining blocks. The Name Node is not in the data path. The Name Node
only provides the map of where data is and where data should go in the cluster (file system
metadata).
5

剩余25页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-09-20 上传
2022-09-23 上传
2022-09-14 上传
2024-08-25 上传
2022-09-20 上传

ilnaij8
- 粉丝: 0
- 资源: 46
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ori and the Will of the Wisps Wallpapers Tab-crx插件
- 欧拉法:求出函数,然后用导数欧拉法画出来-matlab开发
- fpga_full_adder:FPGA实现全加器
- ecommerce:Projeto电子商务后端
- deploy_highlyavailable_website
- goclasses-theme:UTFPR-SH可以在WordPress上使用WordPress的方式进行转换
- A5Orchestrator-1.0.4-py3-none-any.whl.zip
- iz-gone:存档IZ *一个数据
- 找不到架构x86_64的符号
- Floats
- zen_garden
- kadai任务列表
- 模拟退火算法python实现
- Mosh-React-App:使用 CodeSandbox 创建
- python-pytest-azure-demo
- 菜单视图与UIPageviewController相结合
