Windows环境下搭建与运行Storm + Kafka 实例
需积分: 10 20 浏览量
更新于2024-09-07
收藏 880KB DOC 举报
"在WIDS环境下配置并运行Storm与Kafka,包括Zookeeper启动、Kafka服务器启动、创建Topic、启动Producer和Consumer的过程"
在大数据处理领域,Apache Storm和Apache Kafka是两个重要的组件。Storm是一个分布式实时计算系统,用于处理无界数据流,而Kafka是一种高吞吐量的分布式发布订阅消息系统,常被用作实时数据管道。在WIDS(可能是某种特定的IT工作或学习环境)中,结合这两个工具可以构建实时的数据处理流水线。
首先,为了运行Kafka,我们需要启动Zookeeper。Zookeeper是Apache的一个开源项目,提供分布式服务协调,它是Kafka的基础组件,负责元数据的存储和管理。在Zookeeper的bin目录下,通过执行`zkServer.cmd`启动Zookeeper服务。如果遇到问题,如端口2181已被占用,可能需要检查配置或解决端口冲突。此外,确保环境变量CLASSPATH正确设置也是关键,否则可能会导致启动失败。
接下来,启动Kafka服务器。在Kafka的bin目录下,使用`kafka-server-start.bat`命令并指定配置文件`server.properties`来启动服务。如果遇到无法加载主类的错误,同样需要检查并设置CLASSPATH。
创建Kafka Topic是部署数据处理流水线的关键步骤。使用`kafka-topics.bat`命令,指定Zookeeper地址、复制因子、分区数以及Topic名称。例如,创建名为`test.topic`的Topic。在创建过程中,如果出现类加载错误,依然需要检查CLASSPATH。
随后,启动Producer和Consumer。Producer用于发送消息到Kafka的Topic,Consumer则用于接收并处理这些消息。使用`kafka-console-producer.bat`启动Producer,指定期望的Broker列表和Topic。同样,使用`kafka-console-consumer.bat`启动Consumer,指定Zookeeper地址和Topic。
当Producer和Consumer都运行时,可以在Producer窗口输入消息,这些消息会立即在Consumer窗口中显示,证明Kafka的发布订阅机制正常工作。这样,我们就构建了一个简单的Kafka单机环境,可以在其中进行实时数据处理和传输的实验。
总结来说,配置Storm + Kafka环境涉及的主要知识点有:
1. Zookeeper的启动和角色:作为分布式协调服务,负责Kafka集群的元数据管理。
2. Kafka服务器的启动:依赖于Zookeeper,需要正确配置CLASSPATH。
3. 创建Kafka Topic:定义数据流的容器,设置复制因子和分区数影响其性能和可靠性。
4. Kafka Producer和Consumer的使用:Producer发送消息,Consumer接收并处理消息,实现数据的流动。
5. Windows环境下命令行操作:使用批处理脚本启动服务,处理环境变量配置。
这些步骤和概念对于理解和操作实时大数据处理系统至关重要,特别是在WIDS这样的环境中,有助于学习和实践大数据实时处理的原理和实践。
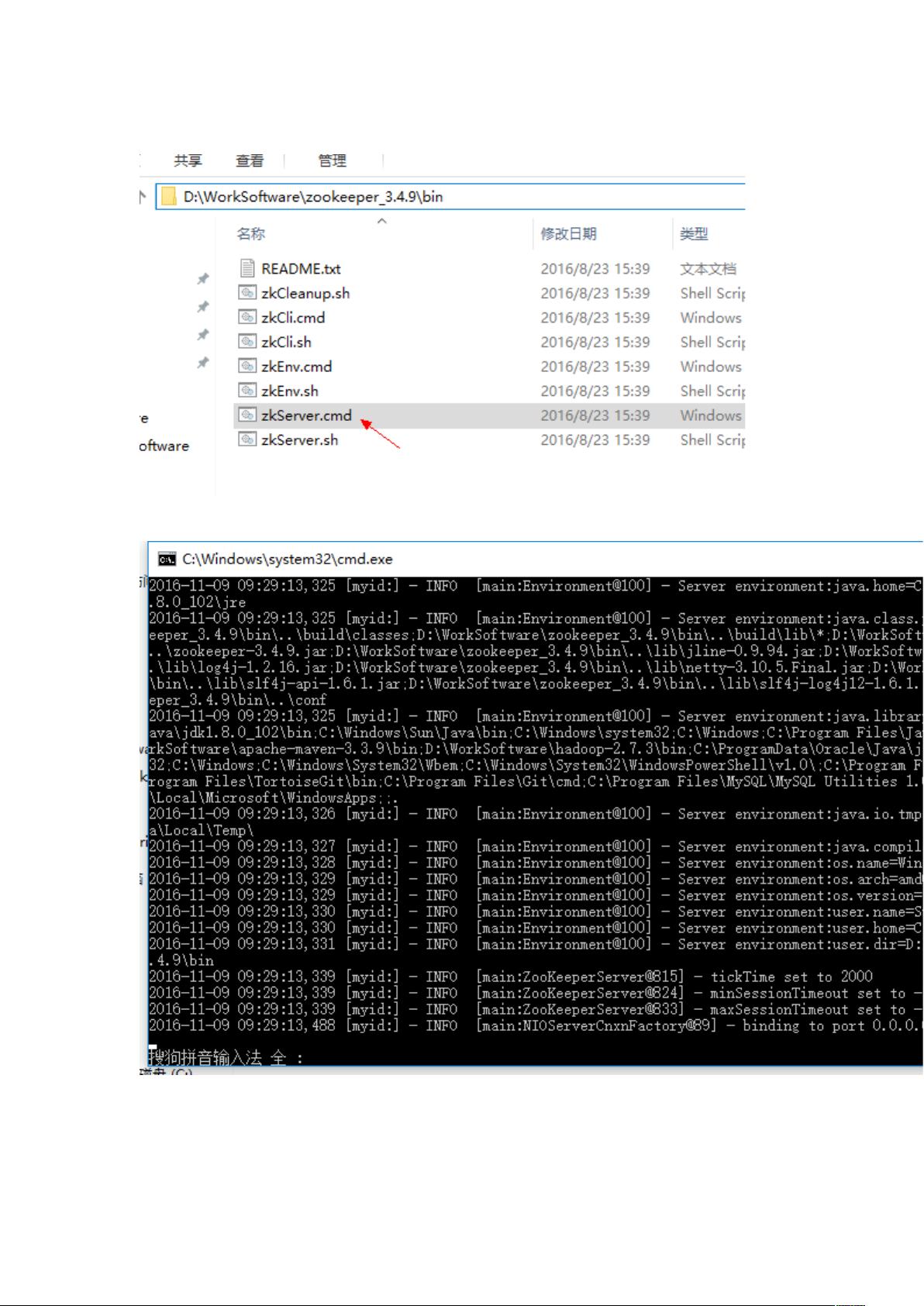
启动 Zookeeper,进入bin目录,执行zkServer.cmd
启动 Zookeeper
默认绑定端口 2181
下载后可阅读完整内容,剩余8页未读,立即下载
2018-07-12 上传
111 浏览量
2016-07-26 上传
2021-02-25 上传
2015-05-19 上传
2020-07-02 上传









