深度学习生成模型:变分自编码器与对抗网络
需积分: 0 56 浏览量
更新于2024-06-30
收藏 866KB PDF 举报
"深度生成模型是概率统计和机器学习领域的重要模型,用于模拟和生成数据。通过学习已有的观测样本,生成模型构建一个参数化模型pθ(x)来近似未知的数据分布pr(x),进而能够生成与真实数据类似的新的样本。在实际应用中,生成模型广泛应用于图像、文本、声音等多种数据类型的建模。
生成模型的挑战主要在于处理高维数据的复杂依赖关系。例如,在图像生成中,由于自然图像中像素之间的复杂关联,直接建模所有像素的概率分布pr(x)是非常困难的。深度生成模型利用深度神经网络的强大表示能力来解决这一问题。它们通常采用一个简单的分布p(z),如标准正态分布,作为输入,通过一个神经网络映射到数据空间,使得生成的样本g(z)接近于原始数据分布pr(x)。
本章特别关注两种深度生成模型:变分自动编码器(VAE)和对抗生成网络(GAN)。变分自动编码器结合了贝叶斯推断和深度学习,通过学习潜在空间中的编码和解码过程来近似数据分布。而对抗生成网络则通过一个生成器和一个判别器的博弈过程,不断提升生成样本的质量,以欺骗判别器,从而使生成器能够更准确地模拟真实数据分布。
生成模型的主要任务包括密度估计和样本生成。密度估计是通过对给定数据集D进行无监督学习,来估计数据来自的概率密度函数pθ(x)。这在理解数据分布和异常检测等问题中具有重要意义。在机器学习中,密度估计是无监督学习的一个关键分支。
13.1.1 密度估计部分,介绍了如何在给定数据集D的情况下,估计数据点x(i)可能来自的概率分布pθ(x)。这通常涉及到从有限的观测数据中推断出整个数据分布的特性,是生成模型的基础之一。
总结来说,深度生成模型是理解和模拟复杂数据分布的强大工具,通过深度学习技术,它们能够处理高维数据的挑战,实现对图像、文本等复杂数据的建模和生成。无论是变分自动编码器还是对抗生成网络,都在不断推动着生成模型在艺术创作、数据增强、模式识别等多个领域的应用边界。"
260 2018 年 6 月 13 日 第 13 章 深度生成模型
此变分密度函数一般写为 q(z|x, ϕ)。推断网络的输入为 x,输出为变分分
布 q(z|x , ϕ)。
2. 用神经网络来产生概率分布 p(x|z, θ),称为生成网络。生成网络的输入为
z,输出为概率分布 p(x|z, θ)。
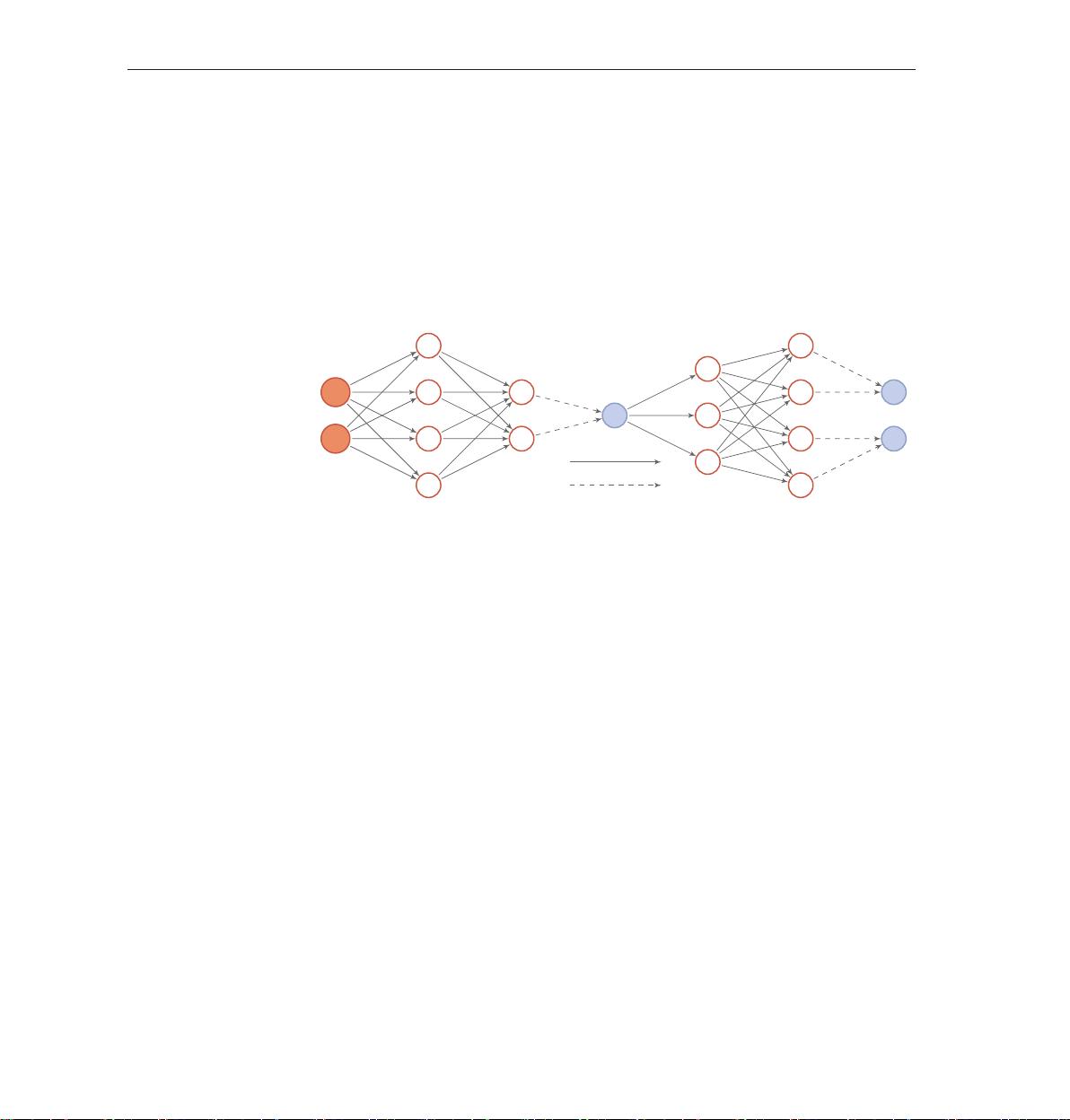
将推断网络和生成网络合并就得到了变分自编码器的整个网络结构,如
图13.3所示,其中实线表示网络计算操作,虚线表示采样操作。
x
1
x
2
z
ˆx
1
ˆx
2
推 断 网 络 f
I
(x, ϕ)
q(z|x, ϕ)
生 成 网 络 f
G
(z, θ)
p(x|z, θ)
网络计算
采样
图 13.3 变分自编码器的网络结构
变分自编码器的名称来自于其整个网络结构和自编码器比较类似。推断网
自编码器参见第9.4节。
络看作是“编码器”,将可观测变量映射为隐变量。生成网络可以看作是“解码
器”,将隐变量映射为可观测变量。但变分自编码器背后的原理和自编码器完全
不同。变分自编码器中的编码器和解码器的输出为分布(或分布的参数),而不
是确定的编码。
13.2.2 推断网络
为了简单起见,假设 q(z|x , ϕ) 是服从对角化协方差的高斯分布,
q(z|x, ϕ) = N(z|µ
I
, σ
2
I
I), (13.6)
其中 µ
I
和 σ
2
I
是高斯分布的均值和方差,可以通过推断网络 f
I
(x, ϕ) 来预测。
µ
I
σ
I
= f
I
(x, ϕ), (13.7)
邱锡鹏:《神经网络与深度学习》 https://nndl.github.io/
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-05-09 上传
2023-07-21 上传
2021-09-16 上传
2022-08-03 上传
2022-08-04 上传
2022-08-03 上传

曹多鱼
- 粉丝: 29
- 资源: 314
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
