ChatGPT能力解析:从起源到进化
需积分: 2 103 浏览量
更新于2024-06-25
收藏 806KB PDF 举报
"ChatGPT各项能力的起源.pdf"
本文深入探讨了ChatGPT,OpenAI的最新预训练模型,以及其各项能力的起源。ChatGPT因其出色的表现,如智能对话、代码编写和超越预期的自然语言处理能力,引起了广泛关注。文章旨在揭示ChatGPT的强大之处,以及它是如何从GPT-3.5模型系列一步步发展而来的。
首先,GPT-3在2020年首次展示了三项关键能力:语言生成、上下文学习和世界知识。语言生成是指模型能够根据提示词生成连贯的文本。上下文学习则是指模型能通过几个示例学习任务,然后应用到新的情境中。这与传统的语言建模任务有所不同,上下文学习成为了GPT-3的核心。此外,GPT-3还展现出对事实性知识和常识的理解,这得益于其在海量语料库上的预训练。
大规模预训练是这些能力的基础。GPT-3在包含3000亿单词的语料库上进行训练,这个过程让模型能够学习到丰富的语言模式和世界知识。预训练的目标是让模型掌握语言的内在结构和模式,以便在各种任务中表现出通用性和适应性。
GPT-3.5作为ChatGPT的前身,进一步优化了这些能力。OpenAI可能采用了更先进的训练策略,如更精细的微调、更复杂的注意力机制或改进的损失函数,以增强模型在特定任务中的性能。ChatGPT的出现标志着这一系列模型的又一次重大飞跃,它不仅在语言理解上更上一层楼,还能进行有意义的对话和执行实际任务,比如编写代码。
文章强调了大型语言模型的透明度和开源的重要性,呼吁国内学术界和技术界重视这一领域的发展。国际上,主流学术机构和业界研究院已经积极接纳并研究大模型,而国内与国际前沿之间的差距似乎在扩大,如果不及时追赶,可能会导致技术代际断裂。
ChatGPT的能力源自于GPT系列模型的不断迭代和大规模预训练,它在语言生成、上下文学习和世界知识方面展现出了前所未有的水平。为了缩小与国际先进水平的差距,国内研究者需要关注这一领域的进展,并积极参与到相关技术的研究和开发中。
一个足够好的开源的近似模型了(根据 OPT 论文和斯坦福大学的 HELM 评
估)。
虽然初代的 GPT-3 可能表面上看起来很弱,但后来的实验证明,初代 GPT-
3 有着非常强的潜力。这些潜力后来被代码训练、指令微调 (instruction
tuning) 和 基 于 人 类 反 馈 的 强 化 学 习 (reinforcement learning with
human feedback, RLHF) 解锁,最终体展示出极为强大的突现能力。
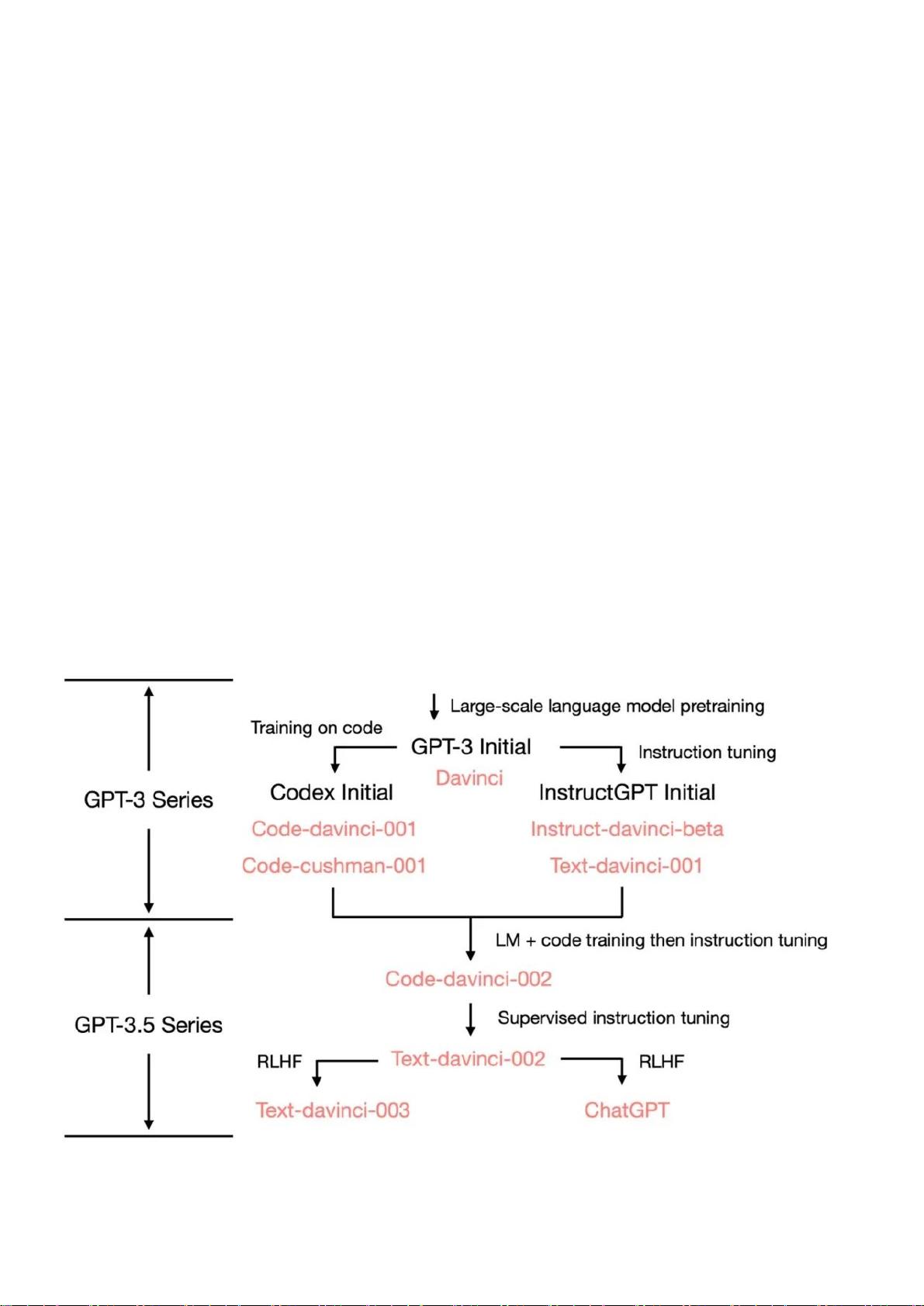
二、从2020版GPT-3到2022版ChatGPT
从最初的 GPT-3 开始,为了展示 OpenAI 是如何发展到ChatGPT的,我们
看一下 GPT-3.5 的进化树:
剩余19页未读,继续阅读
876 浏览量
点击了解资源详情
427 浏览量
2023-05-26 上传
114 浏览量
185 浏览量
143 浏览量
765 浏览量
465 浏览量

程序猿徐师兄
- 粉丝: 647
- 资源: 2287
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++指针详解,经典介绍,比较全面
- A*B 大数相乘 算法 很具有研究性。无错误!
- 动态规划经典题目及解答
- MyEclipse 6 Java 开发中文教程.
- C语言-编程修养(推荐)
- 飞思卡尔中文资料(Freescale)-MC9S08AC16数据手册
- 0V7620中文资料
- ucos exercise
- freescale codewarrir中文资料
- STL_Alexander_Lee_Meng
- STL_tutorial_reference
- 5种JSP页面显示为乱码的解决方法
- I2C 协议标准中文版
- Cisco IOS Programing Guide.pdf
- 人脸识别技术综述所采用的基本方法
- UML+for+Java+Programmers中文版.pdf
