Transformer模型解析:Attention就是一切
需积分: 50 39 浏览量
更新于2024-07-16
收藏 1.47MB PDF 举报
"本文档主要介绍了‘Attention Is All You Need’这一论文的核心概念,特别是Transformer模型中的Attention机制及其在神经机器翻译中的应用。"
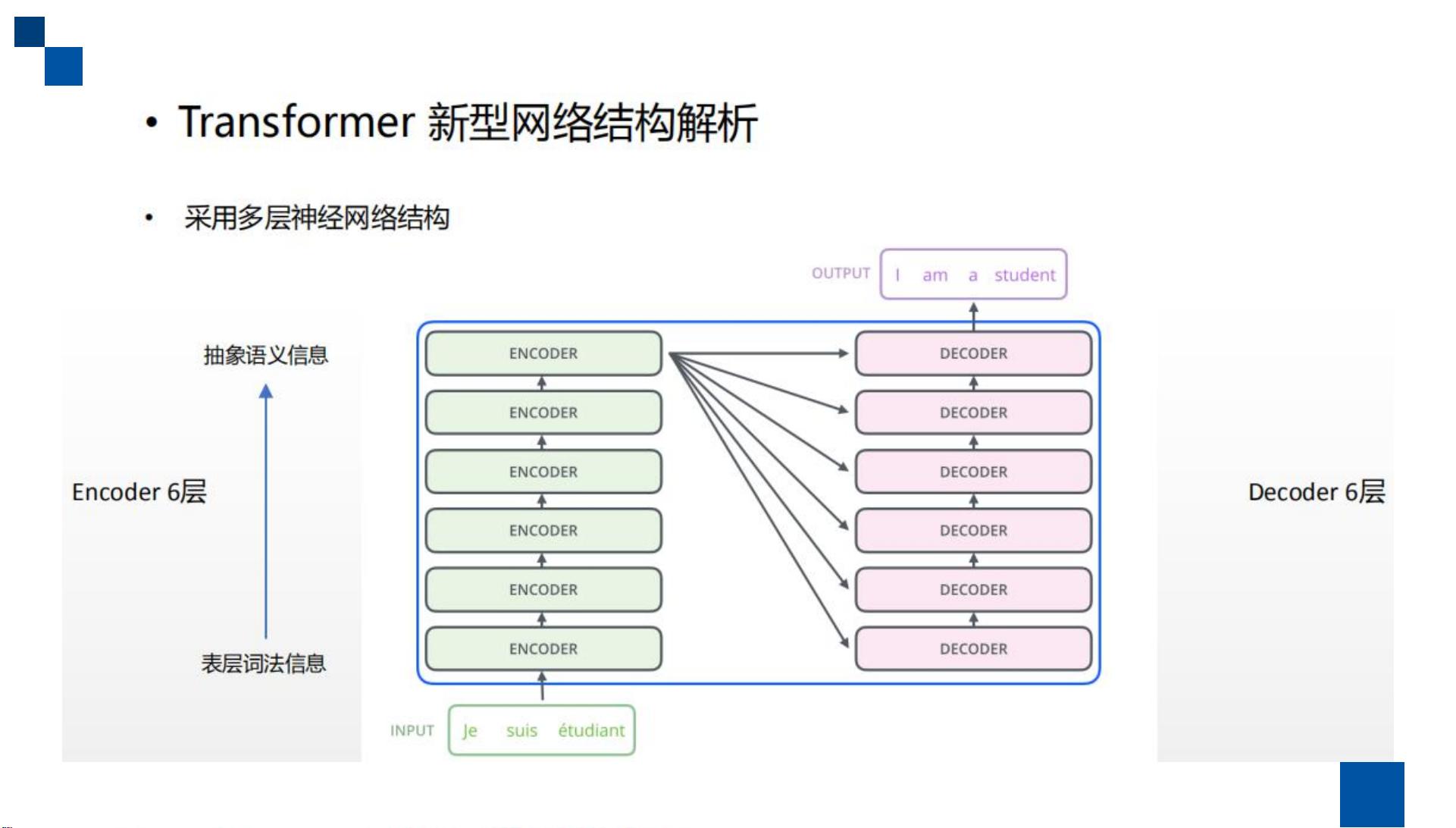
在深度学习领域,Attention模型已经成为解决序列到序列任务的关键技术,尤其在神经机器翻译(Neural Machine Translation, NMT)中表现突出。"Attention Is All You Need"这篇论文由Google AI团队提出,它颠覆了传统的序列模型结构,主张仅依赖Attention机制就能完成复杂的序列建模任务,从而构建了Transformer模型。
Attention机制的基本思想是,对于一个序列任务,模型不再强制按照固定顺序处理所有元素,而是根据当前上下文动态地分配权重来关注序列中的关键部分。这种机制允许模型更灵活地捕获不同位置的信息,特别是在处理长距离依赖时更为有效。
在Attention的计算过程中,分为三个阶段:首先,计算Query(查询)和Key(键)之间的相似度,生成权重系数;其次,通过对这些权重系数进行归一化处理,确保它们构成一个概率分布;最后,按照这个分布对Value(值)进行加权求和,得到最终的输出。这样,每个位置的输出都综合了整个序列的信息,但重点考虑了与之相关性较高的部分。
Transformer模型进一步发展了Attention机制,引入了Multi-Head Attention的概念。在Multi-Head Attention中,Query、Key和Value通过多个不同的参数矩阵映射到多个低维子空间,然后在每个子空间中独立执行Attention操作。这样做可以捕捉到不同方面的依赖关系,并且各个子空间的Attention结果会被拼接起来,形成一个更丰富的表示。这样不仅增强了模型的表达能力,也提高了计算效率,避免了传统递归或卷积结构可能带来的延迟问题。
Attention机制为深度学习模型提供了更强的上下文理解能力,使得模型能够更有效地处理序列数据。Transformer模型的成功证明了Attention机制在处理序列任务中的强大潜力,它已被广泛应用到机器翻译、语音识别、图像标注等多个领域,并且对后续的深度学习研究产生了深远影响。Transformer模型的提出,不仅简化了模型架构,而且提升了模型的性能,为序列建模提供了一种全新的视角。
6
剩余29页未读,继续阅读
2022-04-21 上传
2024-01-11 上传
2021-08-09 上传
2023-11-16 上传
2018-11-18 上传
2019-02-26 上传
2023-08-07 上传

机器不学习_
- 粉丝: 27
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- kissy-xtemplate:用于 KISSY 的独立 XTemplate 编译器
- Yuki
- LockWebPageDriver-master,抖音跳舞代码源码c语言,c语言
- 国际长途酒店机票预订网站模板
- saliengame_idler:2018年Steam Summer'Salien'Minigame的Javascript惰轮
- micronaut-hibernate-validator:与用于Micronaut的Hibernate Validator集成
- winecode
- 随机信号发生器实验室1
- thafas,文字冒险游戏c语言源码,c语言
- 基于JAVA图书馆预约占座系统计算机毕业设计源码+数据库+lw文档+系统+部署
- rg-mobile:RG手机
- Twitter_react
- LojaXXI
- zgxh,保龄球计分的c语言源码,c语言
- amanjain252002.github.io
- Interpolation:切比雪夫插值法。-matlab开发
