2018年北上广深空气质量数据爬取与可视化分析
"这篇资源是关于使用Python网络爬虫技术获取和分析2018年北上广深四个城市空气质量数据的实践项目。作者通过爬取天气后报网站的数据,包括空气质量等级、AQI指数、PM2.5指数等,然后运用Python的数据分析和可视化库对数据进行处理和展示,旨在对比这四个城市的空气质量差异,为人们提供参考信息。文中提到了多个Python爬虫框架的比较,并概述了项目的基本设计结构。"
在本文中,作者首先介绍了项目的设计目的,即关注全国范围内日益重要的空气质量问题,特别是针对北京、上海、广州、深圳这四个大城市。为了获取相关数据,作者选择使用网络爬虫技术,从天气后报网站抓取2018年全年的空气质量数据。这些数据主要包括空气质量等级、AQI指数、当天的AQI排名以及PM2.5指数。
接着,作者简要讨论了几种常用的Python爬虫框架,包括Scrapy、Crawley、Portia、newspaper、python-goose、BeautifulSoup、mechanize、selenium和cola。每种框架都有其特点和适用场景。例如,Scrapy适合简单的URL模式,而Crawley支持多种数据库和数据格式;Portia提供了可视化爬取功能,newspaper和python-goose则专注于新闻和文章内容的提取;BeautifulSoup虽然不能处理JavaScript,但适合基础网页抓取;mechanize能加载JavaScript但文档不全;selenium则通过模拟浏览器行为来处理更复杂的网页交互;cola则是一个分布式爬虫框架,但其设计上存在一些问题。
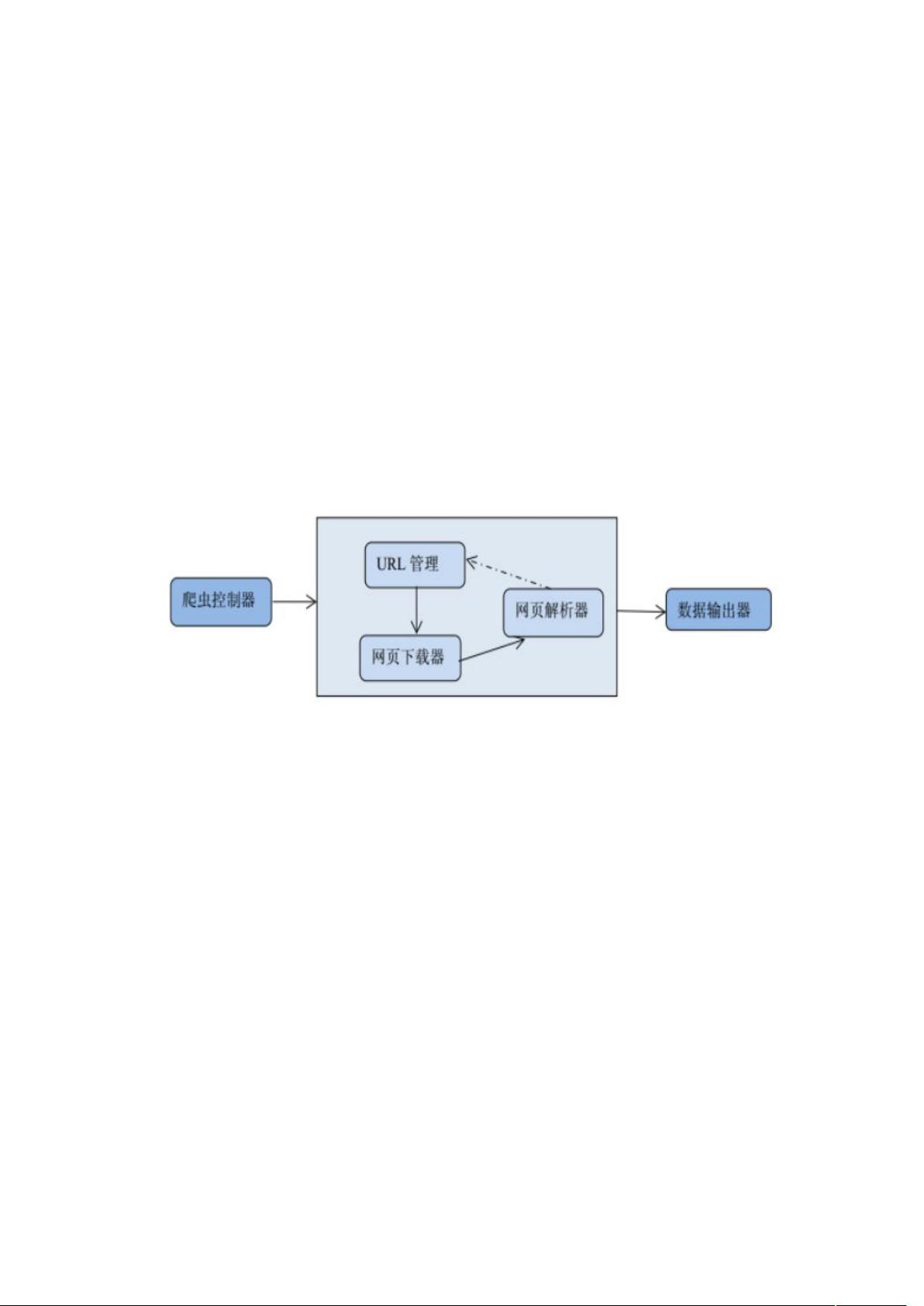
在项目的网络爬虫程序设计部分,作者提到了三个主要模块:爬虫调度端、爬虫模块和数据处理模块。爬虫调度端负责启动和停止爬虫,监控其运行状态;爬虫模块负责实际的网页抓取任务;数据处理模块则对抓取到的数据进行清洗、整理,以便后续的分析和可视化。
最后,通过对数据的分析和可视化,作者能够清晰地呈现四个城市的空气质量差异,从而为公众提供关于这四个城市空气状况的直观信息,帮助那些考虑在这四个城市工作或生活的人做出决策。
这个项目展示了如何结合Python的网络爬虫技术和数据可视化工具,实现对特定主题(空气质量)的大规模数据收集、分析和可视化,体现了Python在数据科学领域的强大应用能力。
(7)mechanize:优点:可以加载 JS。缺点:文档严重缺失。不过通
过官方的 example 以及人肉尝试的方法,还是勉强能用的。
(8)selenium:这是一个调用浏览器的 driver,通过这个库你可以直
接调用浏览器完成某些操作,比如输入验证码。
(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦
合度较高。
四、网络爬虫程序总体设计
在本爬虫程序中共有三个模块:
1. 爬虫调度端:启动爬虫,停止爬虫,监视爬虫的运行情况
2. 爬虫模块:包含三个小模块,URL 管理器,网页下载器,网页解
析器。
(1)URL 管理器:对需要爬取的 URL 和已经爬取过的 URL 进行管理,
可以从 URL 管理器中取出一个带爬取的 URL,传递给网页下载器。
(2)网页下载器:网页下载器将 URL 指定的网页下载下来,存储成
一个字符串,传递给网页解析器。
剩余11页未读,继续阅读
4999 浏览量
3620 浏览量
2023-04-16 上传
496 浏览量
1971 浏览量
2931 浏览量
点击了解资源详情
203 浏览量

XieTeTe
- 粉丝: 15
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 维修中心产品报价清单excel模版下载
- lsvine:`tree -L 2`具有较少的空白屏幕空间
- project_app:这是非常重要的项目
- Newton's method done right:牛顿法求解非线性方程组,包括非平方和不一致方程组-matlab开发
- 现代客厅模型效果图
- 美丽的心型:用Python表达爱意
- command-line-linter
- simpleMapExercise
- SpotifyStalker
- 日记账格式excel模版下载
- dfs:DFS 阵容优化器应用程序的 Github 存储库
- WebProjectWithDjango
- DEF-CON-Links:DEF CON 28安全模式的简易链接和指南
- r7rs-clos:适用于R7RS的微型CLOS包装器
- 小型电影院3D模型
- vscode_ros2
