半监督学习:利用未标记数据提升性能
需积分: 0 25 浏览量
更新于2024-08-04
收藏 1.2MB DOCX 举报
"本文主要探讨了机器学习中的半监督学习,它是监督学习和无监督学习之间的桥梁。在介绍半监督学习之前,文章回顾了机器学习的基础理论,包括泛化误差、经验误差、PAC可学习性以及无限假设空间的VC维和稳定性。此外,还提到了主动学习作为利用未标记数据的一种策略,它通过迭代和有选择地请求标记来提高模型性能。"
在机器学习领域,【半监督学习】是一种重要的学习范式,尤其在现实世界数据集往往标记信息有限的情况下。传统的监督学习依赖于大量带有标记的训练样本,而无监督学习则完全依赖未标记数据进行模式发现,如聚类。然而,半监督学习则试图结合这两种方法的优点,有效地利用有限的标记数据和丰富的未标记数据。
在【描述】中提到的【PAC可学习性】理论,是理解机器学习算法能力的一个基础概念。它指出,如果一个假设空间在概率上能够以足够高的准确度学习到目标概念,那么这个假设空间就是PAC可学习的。对于有限假设空间,分为可分和不可分两种情况。在可分情况下,只要有足够的样本,就能找到一个与训练集一致且近似目标概念的假设。而在不可分情况下,算法可以学习到假设空间中泛化误差最小的假设。
【标签】中的【无限假设空间】则涉及到VC维和增长函数,这两个概念用于衡量假设空间的复杂度。如果一个学习算法遵循经验风险最小化原则,并且假设空间的VC维有限,那么该算法是PAC可学习的。此外,【稳定性】是另一个关键因素,它考察了模型对输入变化的敏感性,与损失函数和可学习性理论紧密相关。
然后,文章引出了【主动学习】的概念,这是一种减少标记数据需求的策略。主动学习通过初步训练模型,预测未标记样本的不确定性或分类置信度,然后选择最具价值的样本请求标记。这种迭代过程可以在较少的人工干预下优化模型性能,但仍属于监督学习范畴。
最后,文章指出无标记样本虽然没有直接的类别信息,但它们的分布信息对学习器的训练至关重要。因此,半监督学习的目标就是设计不依赖外部咨询的算法,自动利用这些未标记数据,以提升模型对总体分布的建模能力。这种方法在数据标注成本高昂或难以获取的场景中具有极大的应用价值。
##14.1 生成式方法
生成式方法(generative methods)是基于生成式模型的方法,即先对联合分
布 P(x,c)建模,从而进一步求解 P(c | x),此类方法假定样本数据服从一
个潜在的分布,因此需要充分可靠的先验知识。例如:前面已经接触到的贝叶
斯分类器与高斯混合聚类,都属于生成式模型。现假定总体是一个高斯混合分
布,即由多个高斯分布组合形成,从而一个子高斯分布就代表一个类簇(类
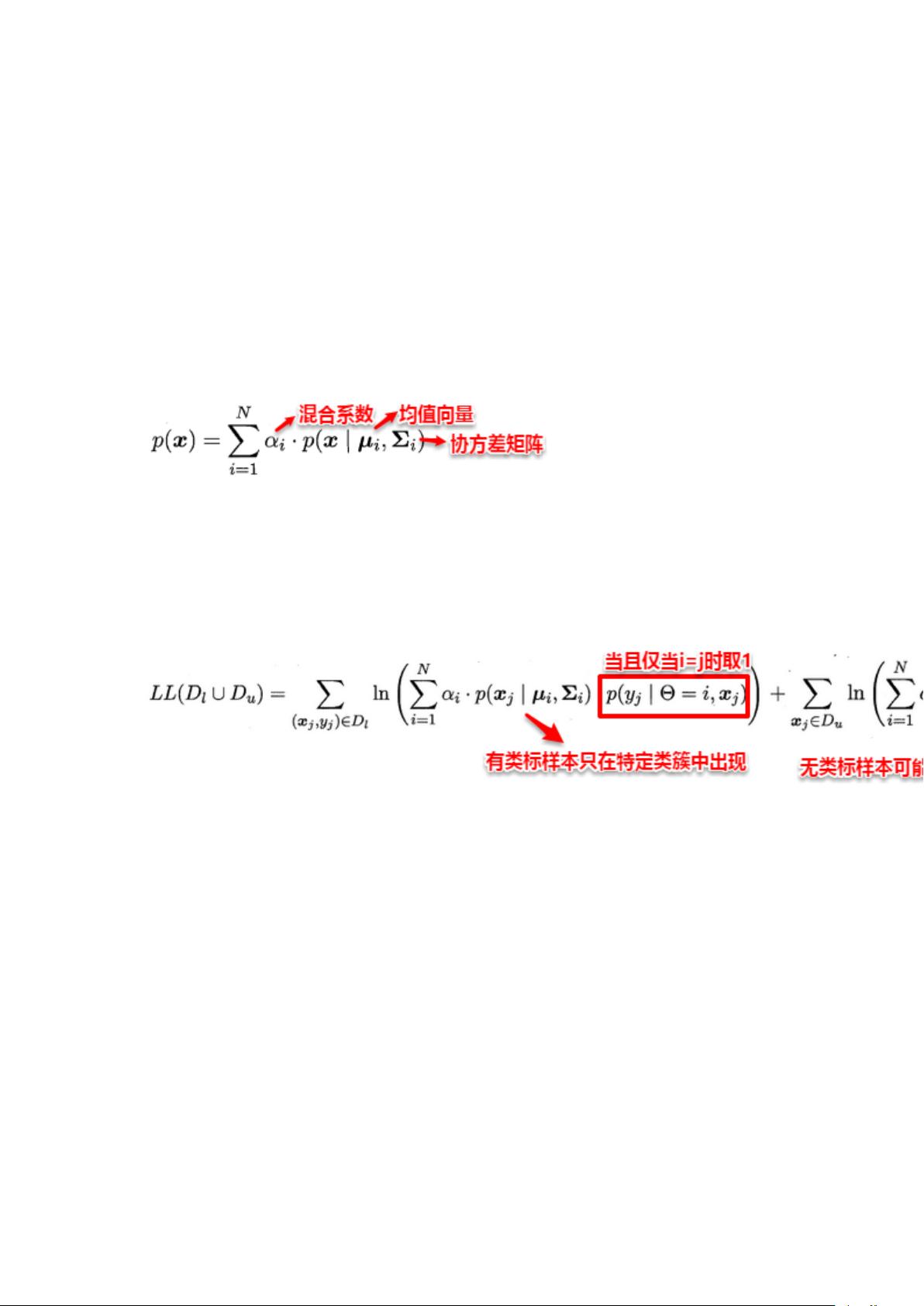
别)。高斯混合分布的概率密度函数如下所示:
不失一般性,假设类簇与真实的类别按照顺序一一对应,即第 i 个类簇对应第 i
个高斯混合成分。与高斯混合聚类类似地,这里的主要任务也是估计出各个高
斯混合成分的参数以及混合系数,不同的是:对于有标记样本,不再是可能属
于每一个类簇,而是只能属于真实类标对应的特定类簇。
直观上来看,基于半监督的高斯混合模型有机地整合了贝叶斯分类器与高斯混
合聚类的核心思想,有效地利用了未标记样本数据隐含的分布信息,从而使得
参数的估计更加准确。同样地,这里也要召唤出之前的 EM 大法进行求解,首
先对各个高斯混合成分的参数及混合系数进行随机初始化,计算出各个 PM
(即 γji,第 i 个样本属于 j 类,有标记样本则直接属于特定类),再最大化似
然函数(即 LL(D)分别对 α、u 和∑求偏导 ),对参数进行迭代更新。
剩余10页未读,继续阅读
2011-01-16 上传
2020-04-09 上传
2022-08-08 上传
2024-05-26 上传
2021-09-10 上传
2015-03-15 上传
183 浏览量
154 浏览量
2016-07-23 上传

挽挽深铃
- 粉丝: 18
- 资源: 274
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
