Hadoop集群搭建与配置实战指南
需积分: 9 125 浏览量
更新于2024-07-27
收藏 1.26MB PDF 举报
"Hadoop 学习指南 - Hadoop 集群(第5期) - Hadoop 安装配置"
本文档是关于Hadoop的学习指南,重点讲述了Hadoop集群的安装配置。Hadoop是一个由Apache软件基金会开发的开源分布式计算平台,其核心组件包括Hadoop分布式文件系统(HDFS)和MapReduce,这两个组件共同构成了Hadoop分布式系统的基础架构。
1、Hadoop简介
Hadoop设计的目标是处理和存储大量数据,提供系统底层细节透明的分布式解决方案。HDFS是一个分布式文件系统,模仿了Google的Bigtable设计,能够以高容错性的方式存储大量数据。而MapReduce则是Google MapReduce的开源实现,用于大规模数据集的并行计算。
1.1 Hadoop集群的角色
在Hadoop集群中,有Master节点和Slave节点两种角色。NameNode作为Master节点,负责维护文件系统的命名空间,管理元数据,并处理客户端的文件操作请求。DataNode是Slave节点,它们在集群中负责存储实际的数据块,并向NameNode报告存储状态。
1.2 MapReduce框架
MapReduce框架由JobTracker和TaskTracker组成。JobTracker运行在Master节点上,它接收并调度作业,监控TaskTracker执行任务,以及处理任务失败的情况。TaskTracker在每个Slave节点上运行,执行由JobTracker分配的任务。
1.3 HDFS与MapReduce的关系
HDFS为MapReduce提供了文件操作和数据存储的支持。在MapReduce任务执行过程中,数据首先被分割并存储在HDFS的不同DataNode上,Map阶段的任务在数据所在的节点上本地执行,以减少数据传输。Reduce阶段则根据需要进行数据聚合和处理。
1.4 集群环境说明
这个特定的Hadoop集群包含1个Master节点和3个Slave节点,所有节点通过局域网连接,可以互相通信。每个节点都有对应的IP地址,这样的配置允许数据在节点间高效地传输和处理。
Hadoop通过HDFS和MapReduce的结合,提供了强大的分布式存储和计算能力,适合处理大数据分析任务。了解和掌握Hadoop的安装配置、集群管理和任务调度,对于理解和运用Hadoop进行大数据处理至关重要。在实际操作中,还需要考虑网络配置、安全性、容错机制以及性能优化等方面,以确保Hadoop集群的稳定运行和高效利用。

创建时间:2012/2/26 修改时间:2012/3/17 修改次数:1
2、SSH无密码验证配置
Hadoop 运行过程中需要管理远端 Hadoop 守护进程,在 Hadoop 启动以后,NameNode
是通过 SSH(Secure Shell)来启动和停止各个 DataNode 上的各种守护进程的。这就必须在
点之间执行指令的时候是不需要输入密码的形式,故我们需要配置 SSH 运用无密码公钥
登录并启动 DataName 进程,同样原理,
ataNode 上也能使用 SSH 无密码登录到 NameNode。
节
认证的形式,这样 NameNode 使用 SSH 无密码
D
2.1 安装和启动SSH协议
在“Hadoop 集群(第 1 期)”安装 CentOS6.0 时,我们选择了一些基本安装包,所以我
们需要两个服务:ssh 和 rsync 已经安装了。可以通过下面命令查看结果显示如下:
rpm –qa | grep openssh
rpm –qa | grep rsync
假设没有安装 ssh 和 rsync,可以通过下面命令进行安装。
yum install ssh 安装 SSH 协议
yum install rsync (rsync 是一个远程数据同步工具,可通过 LAN/WAN 快速同步多台主机间
的文件)
service sshd restart 启动服务
确保所有的服务器都安装,上面命令执行完毕,各台机器之间可以通过密码验证相互登。
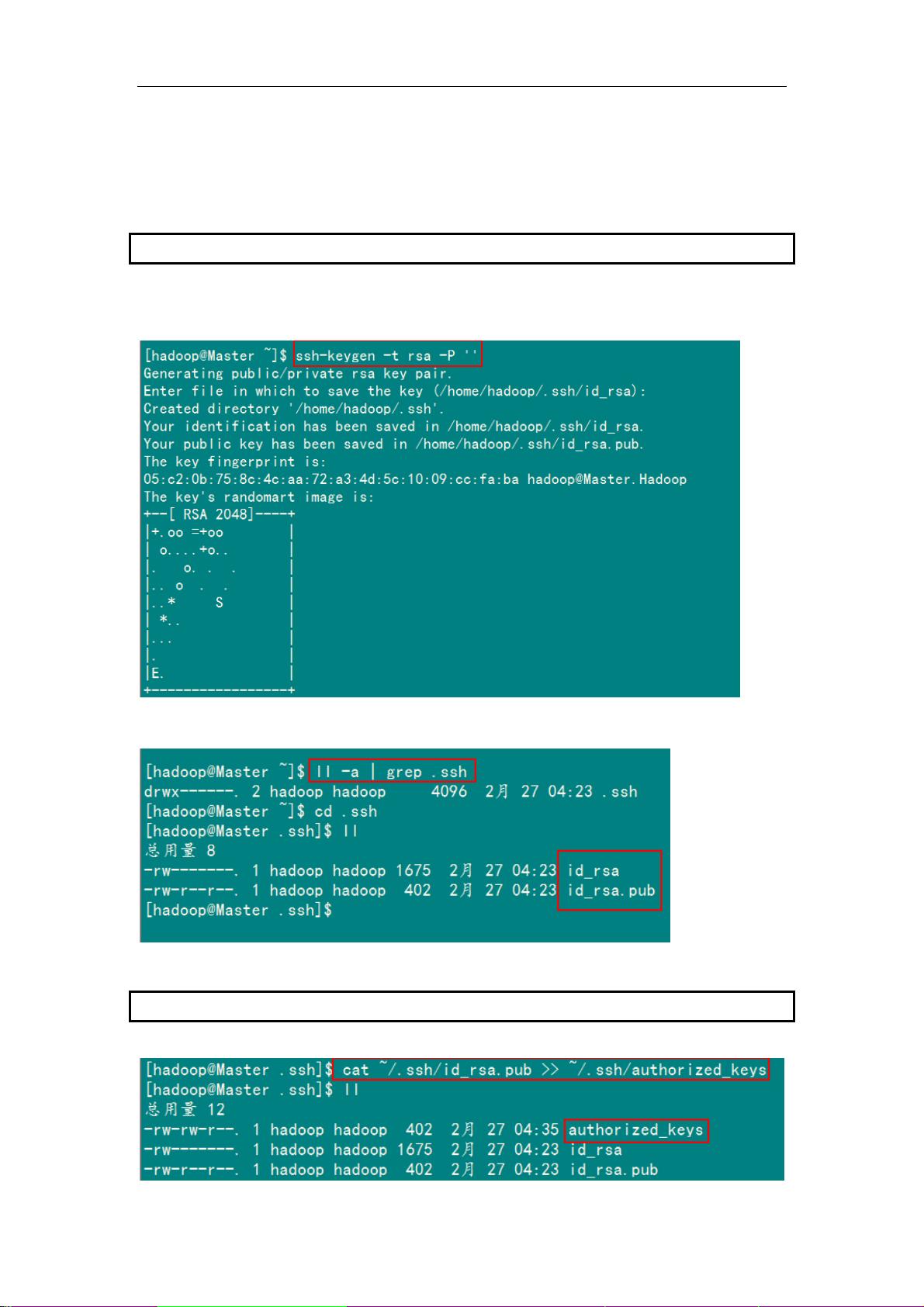
.2 配置Master无密码登录所有Salve
r(Nam
eNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器
时,需要在 Master 上生成一个密钥对,包括一个公钥和一
私钥,而后将公钥复制到所有的 Slave 上。当 Master 通过 SSH 连接 Salve 时,Salve 就会
数之后再用私钥解密,并将解密数回传给 Slave,Slave 确认解密数无误之后就允许 Master
2
1)SSH 无密码原理
Maste
Salve(DataNode | Tasktracker)上
个
生成一个随机数并用 Master 的公钥对随机数进行加密,并发送给 Master。Master 收到加密
河北工业大学——软件工程与理论实验室 编辑:虾皮
7
剩余43页未读,继续阅读
2019-08-02 上传
2018-06-07 上传
2018-04-18 上传
2023-11-07 上传
2024-02-03 上传
2023-05-29 上传
2023-05-09 上传
2023-11-05 上传
2023-08-01 上传









