深度学习模型压缩:模型裁剪技术与加速策略
74 浏览量
更新于2024-08-27
收藏 738KB PDF 举报
"模型加速概述与模型裁剪算法技术解析"
深度学习模型在自动驾驶领域的应用,尤其是在感知任务中,面临着准确性与实时性的双重挑战。为了达到这两个目标,同时降低对计算资源的需求,模型加速和压缩成为了关键。模型的复杂度主要由计算量、访存量和参数量三方面构成。计算量以FLOPs衡量,尤其在卷积神经网络中,卷积层占据了大部分计算。通过调整特征图尺寸、卷积核大小和通道数,可以有效减少计算量。
访存量则是另一个影响模型性能的重要因素,它涉及到内存带宽,模型在前向传播时的读写操作需要快速完成。优化访存量有助于提高执行效率。参数量则直接影响模型的存储需求和训练时间,减少参数量可以降低内存占用和训练时间,但可能影响模型的表达能力。
模型裁剪算法作为模型加速的一种策略,旨在移除模型中的冗余部分,同时保持或提升模型的性能。这种技术通常涉及权重的量化、剪枝和结构优化。权重量化将浮点数权重转换为低精度整数,以减少计算和存储需求。剪枝则是删除对模型性能影响较小的权重或连接,以此来压缩模型。结构优化可能包括移动平均法、动态调整网络宽度或深度,甚至自适应地构建网络结构。
模型裁剪算法的具体实现方式有多种,如基于重要性度量的剪枝,通过评估权重的重要性来决定哪些可以被安全移除。L1范数常被用来衡量权重的重要性,权重绝对值较小的连接被视为可剪枝。此外,还有基于稀疏性诱导的方法,如正则化技术L1或L2,鼓励模型学习稀疏的权重分布。
另一种方法是基于模型性能的迭代剪枝,先训练一个完整的模型,然后在保持性能稳定的情况下逐渐减小模型的规模。这种策略需要在剪枝和微调之间进行多次迭代,以找到最佳的模型结构。此外,还有结构感知的剪枝方法,考虑了模型结构对性能的影响,如保留关键的卷积核或层,以保持模型的关键特性。
在实际应用中,模型裁剪算法通常与知识蒸馏、量化和低秩分解等其他模型压缩技术结合使用,以实现更高效的模型。知识蒸馏通过将大模型(教师模型)的知识转移到小模型(学生模型)中,使小模型能够模仿大模型的输出,从而保持高性能。量化和低秩分解则进一步减少模型的计算和存储需求。
模型加速和裁剪算法是深度学习在自动驾驶等实时应用中不可或缺的技术。它们不仅提高了模型执行的速度,降低了资源消耗,还使得模型能在资源有限的设备上运行,从而推动了自动驾驶技术的发展。未来的研究将继续探索更高效、更智能的模型压缩和加速策略,以应对不断提升的计算需求和复杂的自动驾驶场景。
模型加速概述与模型裁剪算法技术解析模型加速概述与模型裁剪算法技术解析
简介
将深度学习模型应用于自动驾驶的感知任务上,模型预测结果的准确性和实时性是两个重要指标。一方面,为了确保准确可靠
的感知结果,我们会希望选择多个准确性尽可能高的模型并行执行,从而在完成多种感知任务的同时,提供一定的冗余度,但
这不可避免的意味着更高的计算量和资源消耗。另一方面,为了确保车辆在各种突发情况下都能及时响应,我们会要求感知模
块的执行速度必须与自动驾驶场景的车速相匹配,这就对深度学习模型的实时性提出了很高的要求。另外,在保证高准确性和
高实时性的前提下,我们还希望降低模型对计算平台的算力、内存带宽、功耗等方面的要求,从而提高自动驾驶系统整体的效
能。为了应对上述挑战,我们需要从各种角度对深度学习模型进行压缩和加速。实际上,模型压缩和加速是一个相当庞大且活
跃的研究领域,包含众多的研究方向。本文接下来会简要介绍目前模型压缩和加速领域的主要技术方向,并聚焦于模型裁剪算
法这一方向进行详细探讨。在讨论具体的算法之前,首先让我们简要回顾一下深度学习模型的理论复杂度评价指标,以及影响
模型实际运行性能的各种因素。
1.复杂度分析
深度学习模型的复杂度主要体现在计算量、访存量和参数量上。
计算量:即模型完成一次前向传播所需的浮点乘加操作数,其单位通常写作 FLOPs (FLoating-point OPerations)。对卷积神经
网络而言,卷积操作通常是整个网络中计算量最为密集的部分,例如 VGG16 [1] 网络 99% 的计算量都来自于其卷积层。假设
卷积层的输出特征图空间尺寸为 H × W,输入通道数为 Cin,卷积核个数(输出通道数)为 Cout,每个卷积核空间尺寸为 KH
× KW,那么该卷积层的理论计算量为 H × W × KH × KW × Cin × Cout FLOPs。可以看到,卷积层的计算量由输出特征图的
大小、卷积核的大小以及输入和输出通道数所共同决定。对输入特征图进行下采样,或者使用更小、更少的卷积核都可以明显
降低卷积层的计算量。
访存量:即模型完成一次前向传播过程中发生的内存交换总量,单位是 Byte。访存量的重要性经常会被人们忽视,实际上,
模型在逐层进行前向传播的过程中,需要频繁的读写每层的输入特征图、权重矩阵和输出特征图,而读写速度取决于计算平台
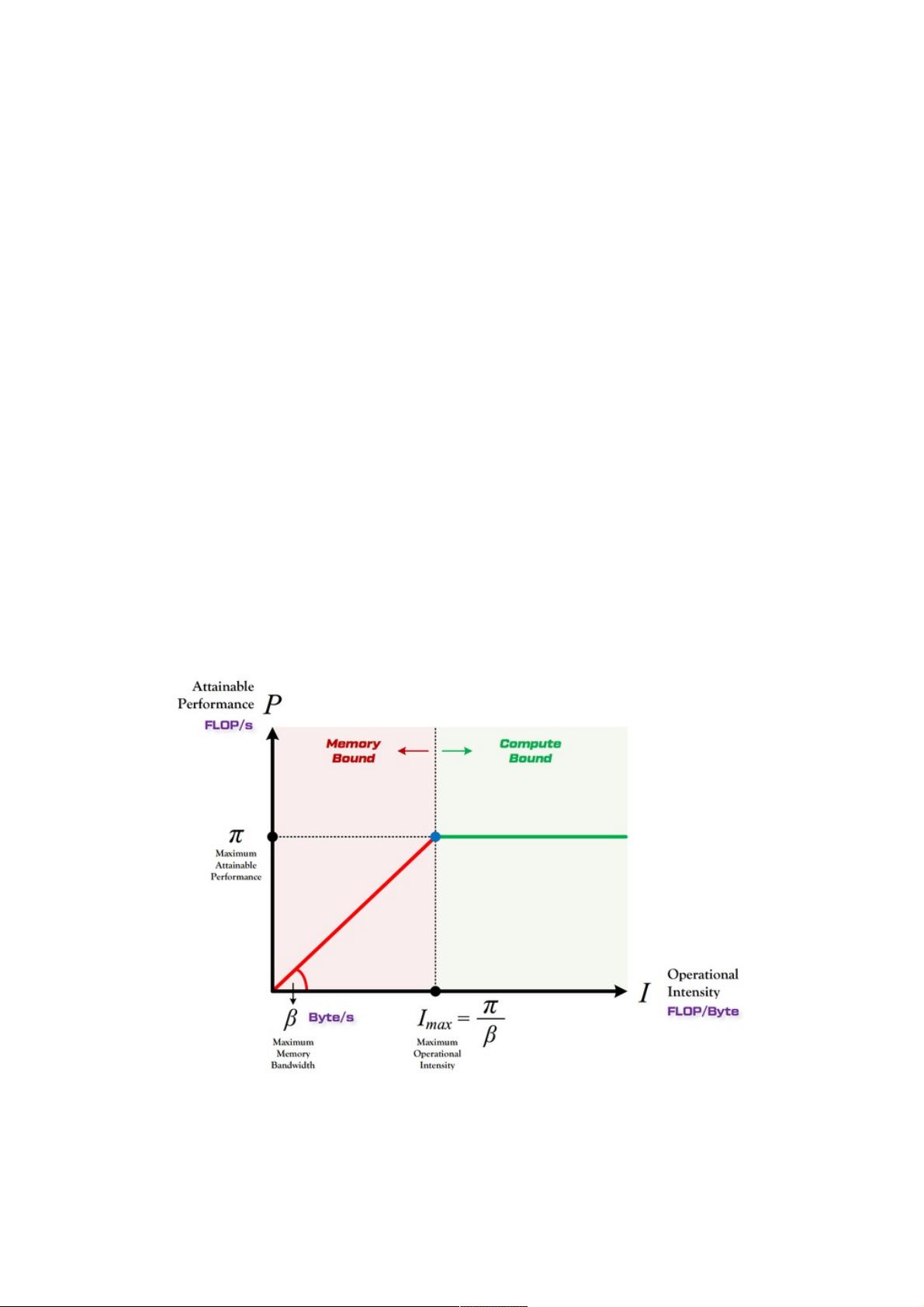
的内存带宽。如果我们在尝试加速模型的时候,只关注减少模型计算量,而没有等比例减小其访存量,那么依据 Roofline [2]
理论,这将导致模型在实际运行过程中,发生单位内存交换所对应的计算量下降,模型会滑向越来越严重的内存受限状态(即
下图中的红色区域),从而无法充分的利用计算平台的算力,因此最后观察到的实际加速比与理论计算量的减小并不成正比。
图1:Roofline Model(图中左侧红色区域为带宽受限,右侧绿色区域为算力受限)
参数量:即模型所含权重参数的总量,单位是 Byte,表现为模型文件的存储体积大小。全连接层通常是整个网络参数量最为
密集的部分,例如 VGG16 网络中超过 80% 的参数都来自于最后三个全连接层。资源严重受限的移动端小型设备会对模型文
件的大小较为敏感。
并行度:如果以 GPU 作为计算平台,那么由于 GPU 本身所具有的高吞吐特性,模型的并行度会成为影响模型实际运行效率
的一个重要方面。模型的并行度越高,意味着模型越能够充分利用 GPU 的算力,执行效率越高。影响并行度的因素有很多,
下载后可阅读完整内容,剩余6页未读,立即下载
2024-07-25 上传
2020-12-27 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38516956
- 粉丝: 6
- 资源: 973
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
