Apache Flink核心技术与应用解析
需积分: 9 73 浏览量
更新于2024-07-08
收藏 42.68MB DOCX 举报
"Flink是一个分布式大数据处理引擎,专注于实时流处理,同时也支持批处理。它提供了高吞吐、低延迟的计算能力,并具备有状态计算、强一致性语义、EventTime处理等功能。Flink起源于欧洲的研究项目StratoSphere,后来成为Apache的顶级项目。其在流计算领域因一致性语义和接近Google Dataflow的数据流模型而备受关注,被阿里巴巴采用发展为Blink框架。Flink应用广泛,包括日志分析、实时监控、复杂事件处理等场景。"
Apache Flink是一个关键的开源大数据处理工具,它结合了批处理和流处理的能力,能够处理无限数据流和有限数据流。Flink的核心设计是它的流处理引擎,允许对数据进行低延迟、高吞吐的处理。这与传统的批处理引擎不同,后者通常处理离线的、静态的数据集。Flink的Stream API基于DataFlow模型,支持事件驱动和乱序事件处理,通过引入EventTime和WaterMark的概念,能够有效地处理时间窗口和数据乱序问题,确保数据处理的准确性。
Flink的另一个显著特性是它提供了有状态计算。这意味着在处理数据流时,Flink可以记住之前处理过的数据状态,这对于实现复杂的业务逻辑和维护数据的一致性至关重要。此外,Flink保证了一致性语义,如exactly-once语义,即使在系统故障或数据重复的情况下,也能保证结果的正确性。
Flink的API设计友好,支持Java和Scala,使得开发人员可以方便地构建流处理应用。由于这些特性,Flink在多个领域得到了广泛应用,包括但不限于实时数据分析、在线机器学习、复杂事件处理、日志分析、实时报表生成等。从大型互联网公司到金融机构,许多组织都选择Flink作为他们的实时数据处理平台。
Flink的发展历程也展示了其在大数据领域的影响力。最初源自柏林工业大学的StratoSphere项目,经过几年的发展和贡献,最终成为Apache的顶级项目。随着流计算的崛起,Flink因其独特的优势脱颖而出,尤其是在阿里巴巴推动的Blink项目中,Flink的技术潜力得到了进一步挖掘和优化,使其在实时计算领域占据了重要的地位。
Flink是一个强大且灵活的实时数据处理框架,它的设计理念和实现方式为大数据处理带来了新的可能性,尤其在实时性和一致性方面,为开发者提供了高效可靠的解决方案。随着大数据应用的不断扩展,Flink的重要性只会继续增长。
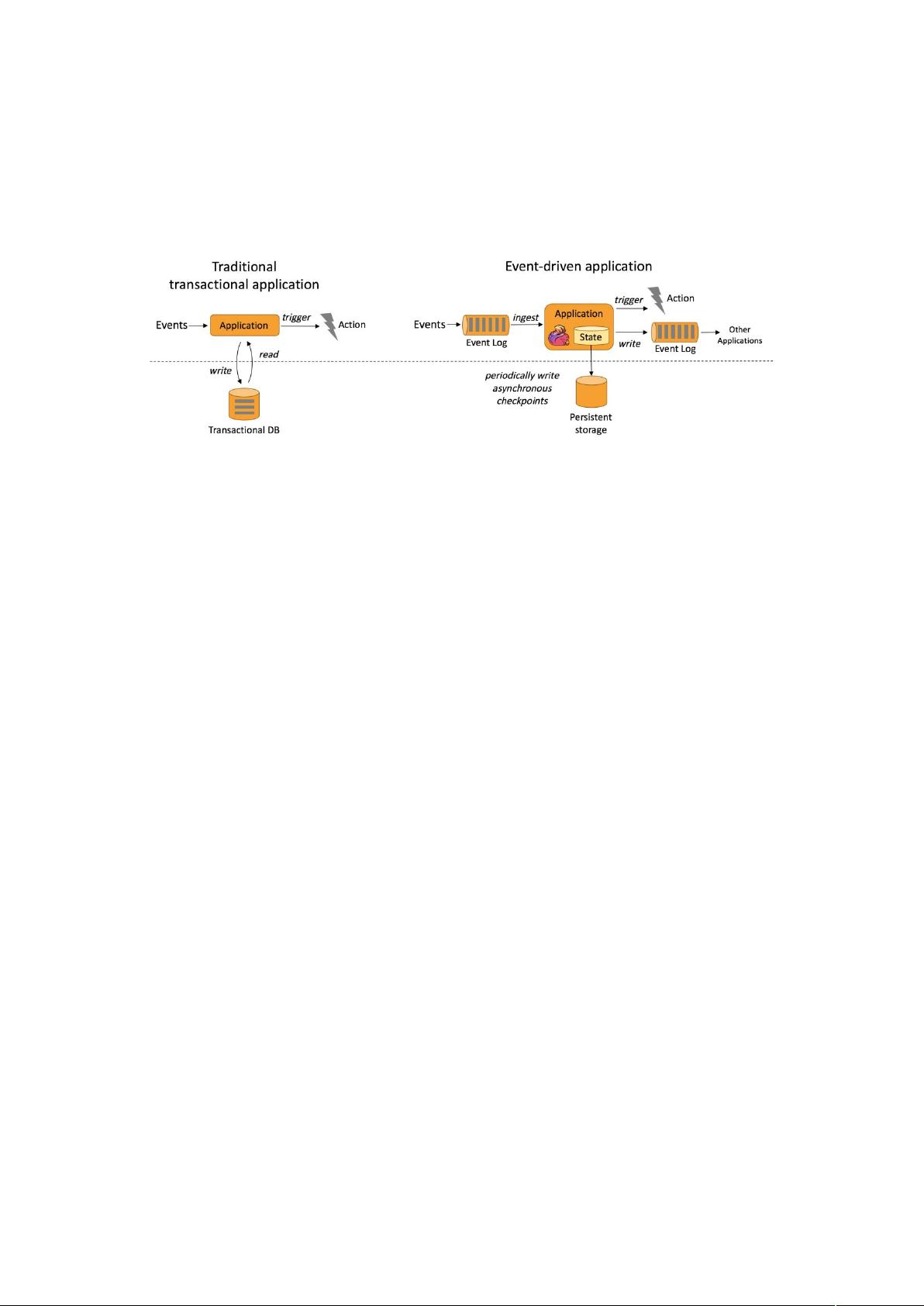
的实现依赖于定期向远程持久化存储写入 checkpoint。下图 1-7 描述了传统
应用和事件驱动型应用架构的区别。
图 1-7 事件驱动型应用
(2)事件驱动型应用的优势?
事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞
吐和更低的延迟。而由于定期向远程持久化存储的 checkpoint 工作可以异步、
增量式完成,因此对于正常事件处理的影响甚微。事件驱动型应用的优势不仅
限于本地数据访问。传统分层架构下,通常多个应用会共享同一个数据库,因
而任何对数据库自身的更改(例如:由应用更新或服务扩容导致数据布局发生
改变)都需要谨慎协调。反观事件驱动型应用,由于只需考虑自身数据,因此
在更改数据表示或服务扩容时所需的协调工作将大大减少。


剩余63页未读,继续阅读
2020-08-19 上传
2020-05-07 上传
2022-08-16 上传
2021-04-20 上传
2020-05-20 上传
2023-06-02 上传
2019-12-26 上传
2021-09-20 上传
2020-09-13 上传

AYXYSYS
- 粉丝: 10
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- 行业分类-设备装置-可移动存储媒体、移动信息终端及其文件管理方法.zip
- Introduction_To_User_Auth
- crowify:一个Monome Norns库,可轻松将Crow支持添加到现有脚本中
- apostrophe-sandbox
- Od.Base-开源
- Temporary_add_to_version_control:将现有R项目与GitHub链接
- 行业分类-设备装置-可调整的组播多媒体业务数据的传输方法及装置.zip
- OCR_App:将图像文本转换为可编辑文本,然后添加为pdf。 也是搜索的选择
- VirtualBox 6.1.14 增强包
- VMware Workstation入门使用
- Project-Assignment:COSC 360 Web论坛项目
- redislock:Redis中的Simple Lock实现。此项目使用jedis的jedis的Java客户端
- sgsourcecodes
- chatServer:使用websockets的chatServer
- 行业分类-设备装置-可移动住宿服务平台.zip
- my_soothe_jetpcack_compose
