纳米级日志系统 NanoLog:速度提升百倍的高效 logging 实现
需积分: 10 163 浏览量
更新于2024-07-09
收藏 617KB PDF 举报
NanoLog是一个专为现代IT环境设计的革命性日志系统,它在2018年USENIX Annual Technical Conference(USENIX ATC'18)上被提出。该论文由Stephen Yang、SeoJin Park和John Ousterhout三位来自斯坦福大学的研究者共同撰写。 NanoLog的主要创新在于其惊人的性能提升,与传统日志系统如Log4j2、spdlog、Boostlog以及Windows的Event Tracing相比,它的处理速度提升了大约一个至两个数量级,达到每秒8000万条简单消息的惊人吞吐量。
在微基准测试中,NanoLog展示了极低的延迟,单个日志调用的开销平均仅为8纳秒。这意味着在日常应用中,即使是频繁的日志记录操作,也几乎感觉不到明显的影响。这得益于NanoLog对工作流程的优化,它将大部分日志处理任务移出运行时的热点路径,实现了轻量级和高效的并发处理。
这种设计理念使得NanoLog在保持类似printf接口易用性的前提下,实现了高性能和低延迟的完美平衡。它的设计理念对于实时性要求极高的系统,如云计算、大数据处理或高并发服务,具有显著的优势。此外,由于论文被公开访问,用户可以直接通过USENIX官网获取并尝试使用这个技术。
NanoLog不仅是一项技术突破,也是日志管理领域的革新,它重新定义了我们对实时、高效日志记录的理解,并可能对未来的软件开发和性能优化带来深远影响。开发者们可以关注这一研究,以期在提高系统性能的同时,保持良好的可维护性和代码简洁性。
NanoLog
Preprocessor
C++
User
Sources
User C++
Object Files
Metadata
NanoLog
Combiner
Compile
Generated
Library Code
Link
Compile
User Sources with
Injected Code
Compact
Log
Decompressor
Human
Readable Log
Compile-Time
Runtime
Post
Execution
User Application
NanoLog
Compaction
Thread
User Thread Staging Buffer
User Thread Staging Buffer
User Thread Staging Buffer
NanoLog
Library
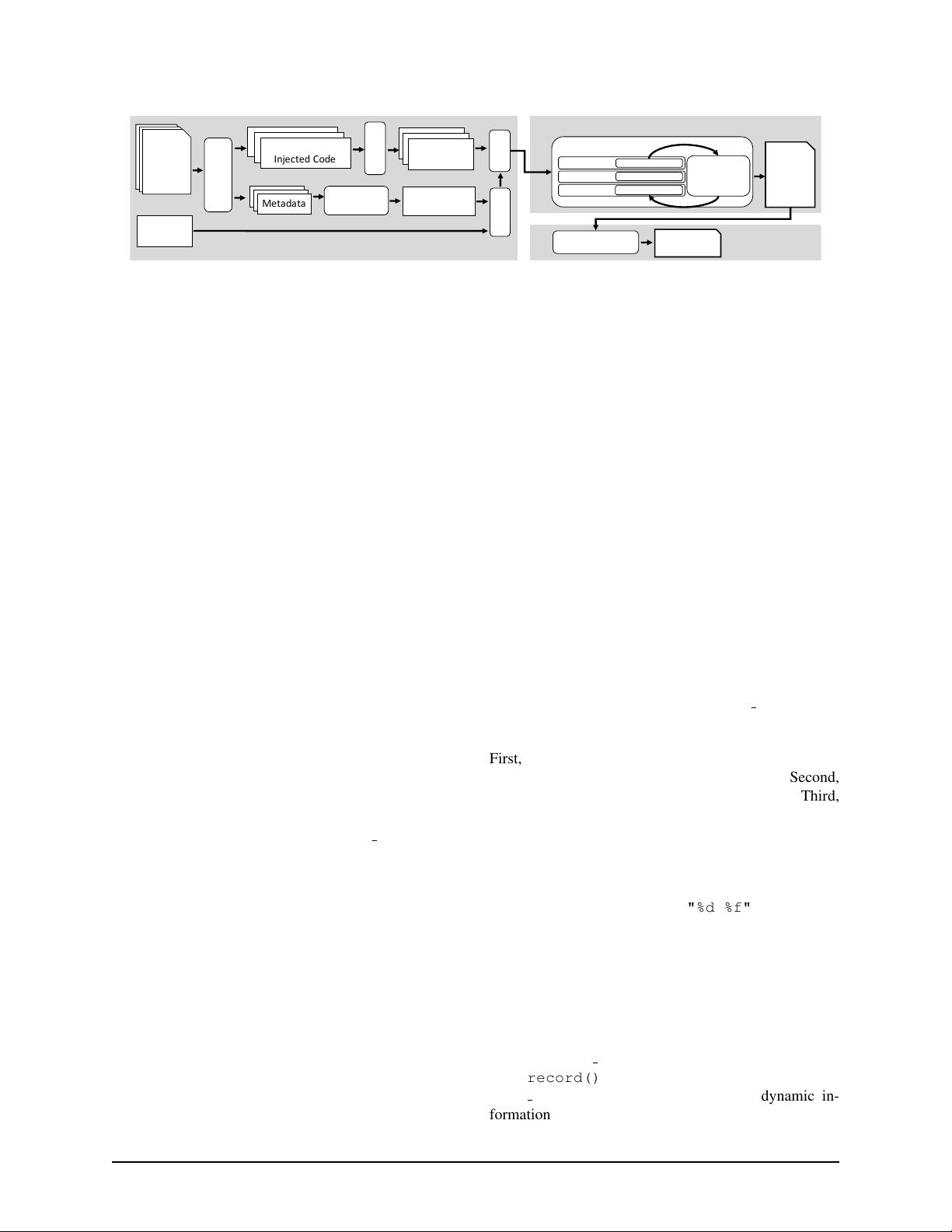
Figure 2: Overview of the NanoLog system. At compile time, the user sources are passed through the NanoLog preprocessor,
which injects optimized logging code into the application and generates a metadata file for each source file. The modified
user code is then compiled to produce C++ object files. The metadata files are aggregated by the NanoLog combiner to build
a portion of the NanoLog Library. The NanoLog library is then compiled and linked with the user object files to create an
application executable and a decompressor application. At runtime, the user application threads interact with the NanoLog
staging buffers and background compaction thread to produce a compact log. At post execution, the compact log is passed into
the decompressor to generate a final, human-readable log file.
3 Overview
NanoLog’s low latency comes from performing work
at compile-time to extract static components from log
messages and deferring formating to an off-line process.
As a result, the NanoLog system decomposes into three
components as shown in Figure 2:
Preprocessor/Combiner: extracts and catalogs static
components from log messages at compile-time, re-
places original logging statements with optimized
code, generates a unique compaction function for
each log message, and generates a function to out-
put the dictionary of static information.
Runtime Library: provides the infrastructure to buffer
log messages from multiple logging threads and
outputs the log in a compact, binary format using
the generated compaction and dictionary functions.
Decompressor: recombines the compact, binary log file
with the static information in the dictionary to either
inflate the logs to a human-readable format or run
analytics over the log contents.
Users of NanoLog interact with the system in the fol-
lowing fashion. First, they embed NANO
LOG() func-
tion calls in their C++ applications where they’d like
log messages. The function has a signature similar to
printf [17, 33] and supports all the features of printf
with the exception of the “%n” specifier, which requires
dynamic computation. Next, users integrate into their
GNUmakefiles [40] a macro provided by NanoLog that
serves as a drop-in replacement for a compiler invoca-
tion, such as g++. This macro will invoke the NanoLog
preprocessor and combiner on the user’s behalf and gen-
erate two executables: the user application linked against
the NanoLog library, and a decompressor executable to
inflate/run analytics over the compact log files. As the
application runs, a compacted log is generated. Finally,
the NanoLog decompressor can be invoked to read the
compacted log and produce a human-readable log.
4 Detailed Design
We implemented the NanoLog system for C++ appli-
cations and this section describes the design in detail.
4.1 Preprocessor
The NanoLog preprocessor interposes in the compila-
tion process of the user application (Figure 2). It pro-
cesses the user source files and generates a metadata
file and a modified source file for each user source file.
The modified source files are then compiled into object
files. Before the final link step for the application, the
NanoLog combiner reads all the metadata files and gen-
erates an additional C++ source file that is compiled into
the NanoLog Runtime Library. This library is then linked
into the modified user application.
In order to improve the performance of logging, the
NanoLog preprocessor analyzes the NANO LOG() state-
ments in the source code and replaces them with faster
code. The replacement code provides three benefits.
First, it reduces I/O bandwidth by logging only infor-
mation that cannot be known until runtime. Second,
NanoLog logs information in a compacted form. Third,
the replacement code executes much more quickly than
the original code. For example, it need not combine the
dynamic data with the format string, or convert binary
values to strings; data is logged in a binary format. The
preprocessor also extracts type and order information
from the format string (e.g., a "%d %f" format string
indicates that the log function should encode an integer
followed by a float). This allows the preprocessor to gen-
erate more efficient code that accepts and processes ex-
actly the arguments provided to the log message. Type
safety is ensured by leveraging the GNU format at-
tribute compiler extension [10].
The NanoLog preprocessor generates two functions
for each NANO
LOG() statement. The first func-
tion, record(), is invoked in lieu of the original
NANO LOG() statement. It records the dynamic in-
formation associated with the log message into an in-
USENIX Association 2018 USENIX Annual Technical Conference 337
详细设计
预处理
1.生成元数据
2.修改源文件
3.编译源文件
4.读取元数据,
生成额外的源文
件,它将被编译
为运行时库
5.这个库将连接
到用户应用中
不能使用动态
字符串
提取类型
和order
剩余15页未读,继续阅读

rtoax
- 粉丝: 2762
- 资源: 218
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
