Tango:基于共享日志的分布式数据结构
86 浏览量
更新于2024-07-14
收藏 1.24MB PDF 举报
"Tango - Distributed Data Structures over a Shared Log"
Tango是一个分布式数据结构系统,旨在提供一种新的数据中心抽象来存储和计算大规模数据集。该系统通过在共享日志上提供复制的、内存中的数据结构,例如映射或树,来简化分布式系统的构建。
Tango的主要特点是提供了一个抽象的、复制的、内存中的数据结构,备份到共享日志中。这使得开发者可以轻松地构建和使用分布式数据结构,而不需要担心复杂的分布式协议。同时,Tango还提供了线性化、持久性和高可用性等特性,从而使得分布式系统更加可靠和高效。
Tango的关键技术是共享日志,通过简单的追加和读取操作来实现数据的复制和一致性。这种方法可以简化分布式系统的设计和实现,提高系统的可靠性和可扩展性。
Tango还提供了快速的事务处理机制,允许应用程序跨不同的对象进行事务处理。这使得分布式系统可以更好地支持大规模数据集的处理和分析。
Tango的设计目标是提供一种简单、可靠和高效的分布式数据结构系统,能够支持大规模数据集的存储和计算。该系统的出现将简化分布式系统的构建和使用,对于大规模数据集的处理和分析具有重要意义。
Tango的技术特点包括:
* 共享日志:Tango使用共享日志来实现数据的复制和一致性,简化分布式系统的设计和实现。
* 复制的、内存中的数据结构:Tango提供了复制的、内存中的数据结构,例如映射或树,来简化分布式系统的构建和使用。
* 线性化、持久性和高可用性:Tango提供了线性化、持久性和高可用性等特性,从而使得分布式系统更加可靠和高效。
* 快速的事务处理:Tango提供了快速的事务处理机制,允许应用程序跨不同的对象进行事务处理。
Tango是一个功能强大且灵活的分布式数据结构系统,能够简化分布式系统的构建和使用,对于大规模数据集的处理和分析具有重要意义。
0
100
200
300
400
500
600
700
800
-5 0 5 10 15 20 25 30 35 40
Ks of Requests/Sec
# of Clients
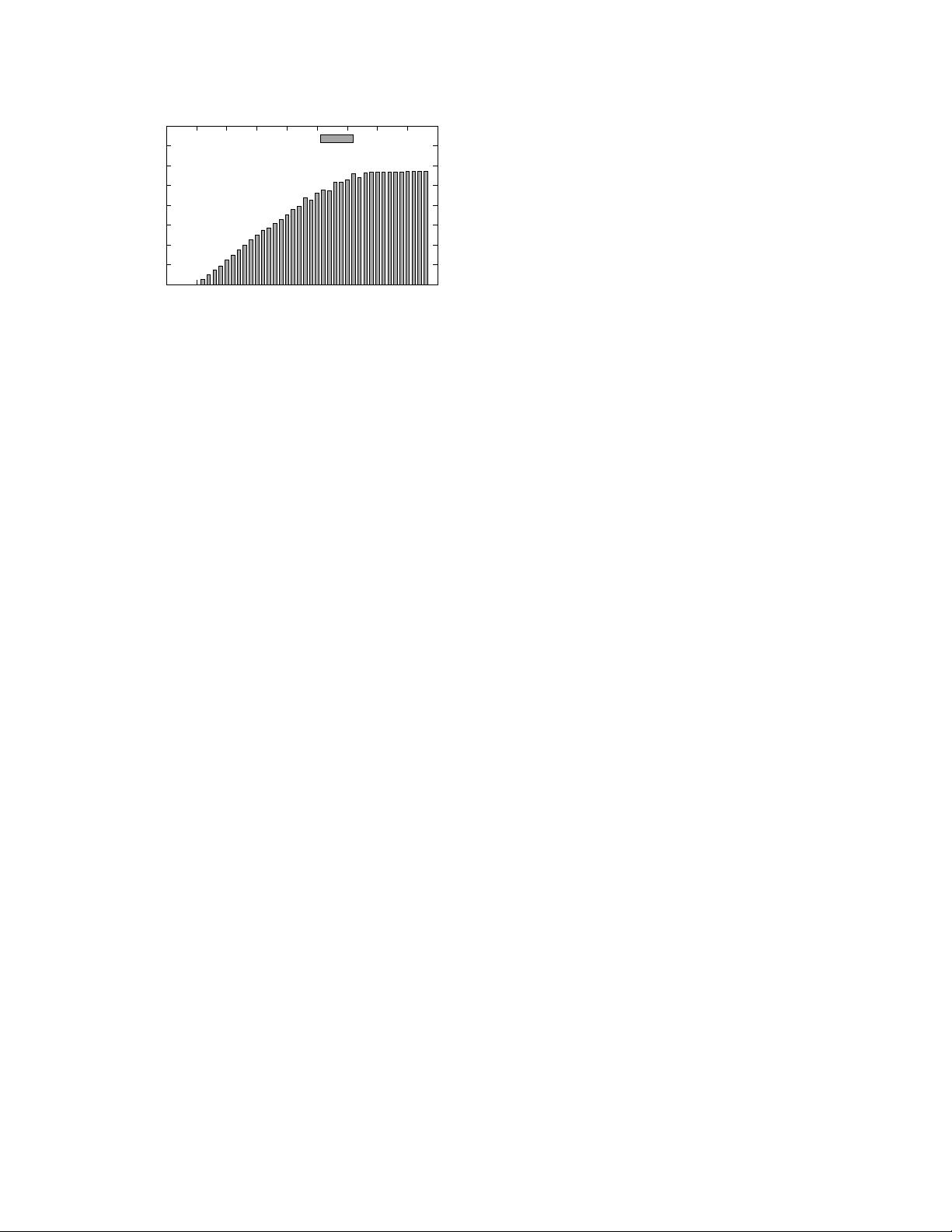
Sequencer Throughput
Figure 2: A centralized sequencer can scale to more
than half a million operations/sec.
2.2 The CORFU Shared Log
The CORFU interface is simple, consisting of four ba-
sic calls. Clients can append entries to the shared log,
obtaining an offset in return. They can check the current
tail of the log. They can read the entry at a particular off-
set. The system provides linearizable semantics: a read
or a check is guaranteed to see any completed append
operations. Finally, clients can trim a particular offset in
the log, indicating that it can be garbage collected.
Internally, CORFU organizes a cluster of storage
nodes into multiple, disjoint replica sets; for example,
a 12-node cluster might consist of 4 replica sets of size
3. Each individual storage node exposes a 64-bit write-
once address space, mirrored across the replica set. Ad-
ditionally, the cluster contains a dedicated sequencer
node, which is essentially a networked counter storing
the current tail of the shared log.
To append to the shared log, a client first contacts the
sequencer and obtains the next free offset in the global
address space of the shared log. It then maps this offset
to a local offset on one of the replica sets using a simple
deterministic mapping over the membership of the clus-
ter. For example, offset 0 might be mapped to A : 0 (i.e.,
page 0 on set A, which in turn consists of storage nodes
A
0
, A
1
, and A
2
), offset 1 to B : 0, and so on until the func-
tion wraps back to A : 1. The client then completes the
append by directly issuing writes to the storage nodes
in the replica set using a client-driven variant of Chain
Replication [45].
Reads to an offset follow a similar process, minus
the offset acquisition from the sequencer. Checking
the tail of the log comes in two variants: a fast check
(sub-millisecond) that contacts the sequencer, and a slow
check (10s of milliseconds) that queries the storage
nodes for their local tails and inverts the mapping func-
tion to obtain the global tail.
The CORFU design has some important properties:
The sequencer is not a single point of failure. The
sequencer stores a small amount of soft state: a single
64-bit integer representing the tail of the log. When the
sequencer goes down, any client can easily recover this
state using the slow check operation. In addition, the se-
quencer is merely an optimization to find the tail of the
log and not required for correctness; the Chain Replica-
tion variant used to write to the storage nodes guarantees
that a single client will ‘win’ if multiple clients attempt
to write to the same offset. As a result, the system can
tolerate the existence of multiple sequencers, and can
run without a sequencer (at much reduced throughput)
by having clients probe for the location of the tail. A
different failure mode involves clients crashing after ob-
taining offsets but before writing to the storage nodes,
creating ‘holes’ in the log; to handle this case, CORFU
provides applications with a fast, sub-millisecond fill
primitive as described in [10] .
The sequencer is not a bottleneck for small clusters.
In prior work on CORFU [10], we reported a user-space
sequencer that ran at 200K appends/sec. To test the lim-
its of the design, we subsequently built a faster CORFU
sequencer using the new Registered I/O interfaces [9]
in Windows Server 2012. Figure 2 shows the perfor-
mance of the new sequencer: as we add clients to the
system, sequencer throughput increases until it plateaus
at around 570K requests/sec. We obtain this perfor-
mance without any batching (beyond TCP/IP’s default
Nagling); with a batch size of 4, for example, the se-
quencer can run at over 2M requests/sec, but this will
obviously affect the end-to-end latency of appends to
the shared log. Our finding that a centralized server
can be made to run at very high RPC rates matches re-
cent observations by others; the Percolator system [38],
for example, runs a centralized timestamp oracle with
similar functionality at over 2M requests/sec with batch-
ing; Vasudevan et al. [46] report achieving 1.6M sub-
millisecond 4-byte reads/sec on a single server with
batching; Masstree [33] is a key-value server that pro-
vides 6M queries/sec with batching.
Garbage collection is a red herring. System designers
tend to view log-structured designs with suspicion, con-
ditioned by decades of experience with garbage collec-
tion over hard drives. However, flash storage has sparked
a recent resurgence in log-structured designs, due to the
ability of the medium to provide contention-free random
reads (and its need for sequential writes); every SSD on
the market today traces its lineage to the original LFS
design [39], implementing a log-structured storage sys-
tem that can provide thousands of IOPS despite con-
current GC activity. In this context, a single CORFU
storage node is an SSD with a custom interface (i.e.,
a write-once, 64-bit address space instead of a conven-
tional LBA, where space is freed by explicit trims rather
剩余15页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-10-14 上传
2019-01-09 上传
2021-02-16 上传
2022-01-30 上传
2022-02-12 上传
2021-03-14 上传

weixin_38623272
- 粉丝: 5
- 资源: 853
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全新PHP网址缩短防封短网址生成系统
- Almayce Video Handler-开源
- NotaFiscalNet:.NET电子发票生成
- 武汉医保读卡DLL动态库.rar
- Ziplyne Player prod-crx插件
- RestWithSpringBootMath
- ZoomTest.rar_FlashMX/Flex源码_FlashMX_
- Weinview触摸屏-OMRON_CJ1CS1PLC连接说明书
- quantcs-impl:量化类约束的实现
- Luiz_Henrique_Souza_JAMStackAlura
- paixu.rar_汇编语言_Asm_
- Learn-wp-cli:命令行,WP-CLI和自定义WP-CLI命令入门
- Ledavio Image Importer-crx插件
- The-ABM-in-Archaeology-Bibliography:有关考古中基于代理的模型(ABM)的文献的完整列表。 由Iza Romanowska和Lennart Linde维护和创建
- HubCollections.3okat1n89t.gaJP44e
- flexx:用纯Python编写桌面和Web应用程序
