Pandas基础教程:从列表、字典到Excel操作
需积分: 9 96 浏览量
更新于2024-08-05
收藏 1.33MB PDF 举报
"pandas基本知识"
在Python的数据分析领域,pandas库是一个不可或缺的工具,它提供了高效的数据结构,如Series和DataFrame,以及用于处理和操作数据的强大功能。这篇文档主要介绍了pandas的基本概念和对象创建方法。
**基本概念**
1. **Series对象**:Series是pandas的一个一维数据结构,类似于一列数据,它可以包含任何数据类型(整数、字符串、浮点数、Python对象等)。每个Series都有一个索引,用于标识数据的位置。如果不指定索引,系统会自动创建一个默认的整数索引,从0开始递增。
2. **DataFrame对象**:DataFrame是pandas的核心数据结构,它是一个二维表格型数据结构,可以理解为多个Series的集合,每一列都是一个Series。DataFrame有行索引(index)和列索引(columns),可以存储不同类型的数据,并且具有丰富的操作方法。
**函数参数**
pandas库中的大多数函数都包含必选参数和可选参数。可选参数通常有默认值,这意味着如果不提供,函数将使用预设的默认值。这些函数通常会返回一个新的对象,而不是直接修改原始对象,这是pandas库的一个重要设计原则,以确保数据操作的可预测性和安全性。
**对象创建**
1. **列表转换**:你可以使用列表来创建Series和DataFrame。对于Series,列表中的每个元素对应一行数据,可以使用`index`参数自定义行索引;对于DataFrame,二维列表的每一行对应一个数据行,`columns`参数用于定义列名。
- 示例:
```python
s1 = pd.Series([166, 167, 168])
s2 = pd.Series([166, 167, 168], index=['小张', '小王', '小李'])
df1 = pd.DataFrame([[166, 56], [167, 57], [168, 58]])
df2 = pd.DataFrame([[166, 56], [167, 57], [168, 58]], index=['s1', 's2', 's3'], columns=['身高', '体重'])
```
2. **字典转换**:利用字典可以创建Series和DataFrame。对于Series,字典的键成为索引,值成为数据;对于DataFrame,字典的键成为列名,键对应的值(列表或元组)成为列数据。
- 示例:
```python
s3 = pd.Series({'s1': 166, 's2': 167, 's3': 168})
df3 = pd.DataFrame({"身高": [166, 167, 168], "体重": [56, 57, 58]}, index=['s1', 's2', 's3'])
```
3. **从文件加载数据**:pandas提供了`read_excel()`和`read_csv()`函数从Excel和CSV文件中读取数据到DataFrame。例如:
```python
df4 = pd.read_excel("nba.xlsx")
df4 = pd.read_csv("nba.csv")
```
同样,可以使用`to_excel()`和`to_csv()`函数将DataFrame保存到Excel或CSV文件。
这些基础知识构成了pandas学习的基础,掌握它们能帮助你有效地处理和分析各种数据集。在实际应用中,还会涉及到数据清洗、数据筛选、聚合、合并、重塑等多种操作,这些都是pandas库的强大之处。
pandas 基本知识
【基本概念】
1、Series 对象用来保存单列数据,DataFrame 对象用来保存多列数据,可以认为是多个 Series 对象的
组合,每一列都是一个 Series 对象。
2、索引又叫标签、标题,是每一行和每一列的标记,通过列索引 columns 和行索引 index 可以用来查
看和修改数据的值,索引值本身也可以修改。
3、每个函数都有自己的必选参数和可选参数(不写为默认值),绝大多数函数默认对列数据进行处理,
会生成一个新对象来保存结果,不直接修改原对象的值。
说明:本文中,
可选参数用斜体字表示
。
默认库已导入:import pandas as pd
一、对象的创建
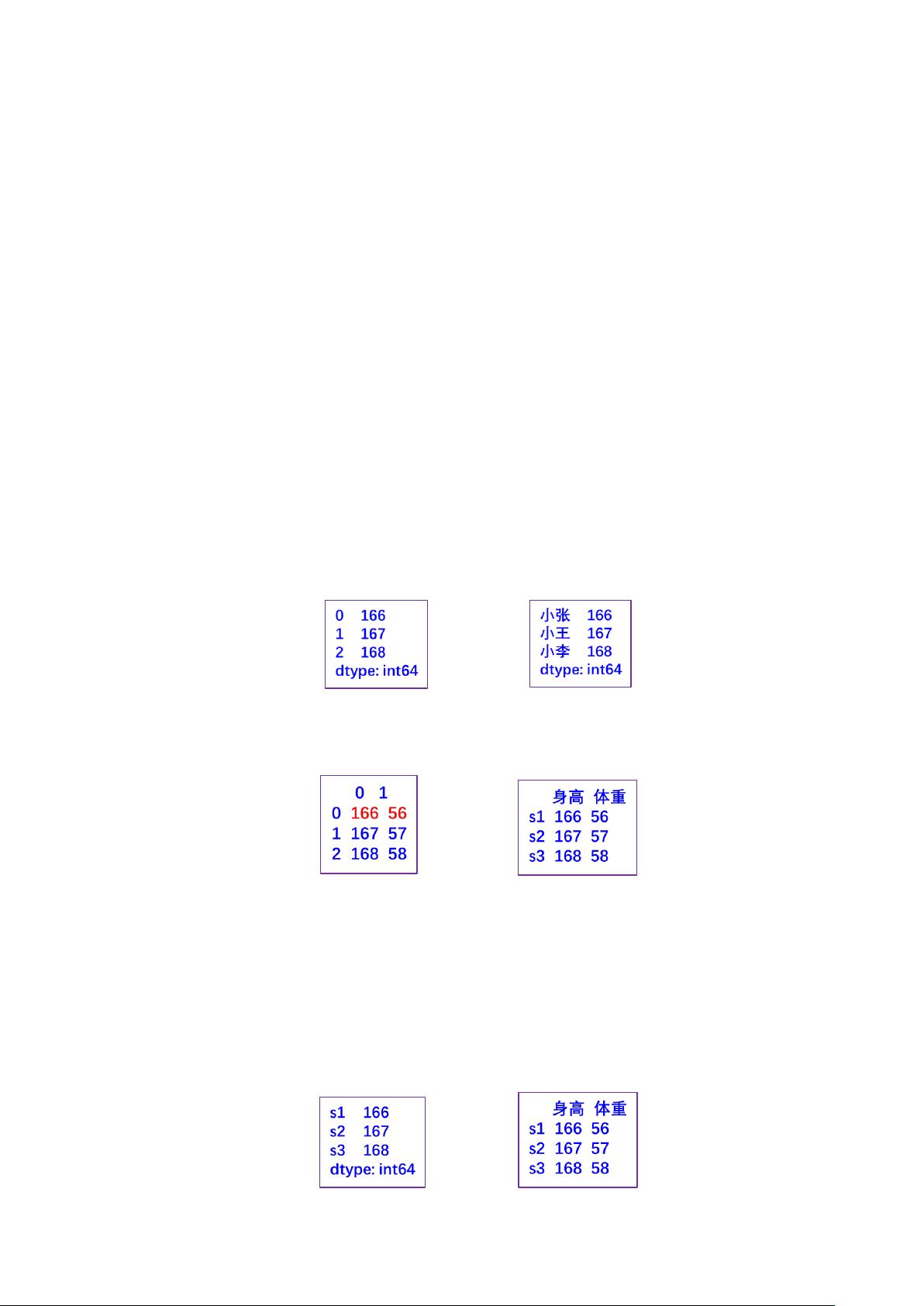
1、把列表转换为对象(一维列表创建 Series 对象,二维列表创建 DataFrame 对象)
要点:
1、列表中的一个元素对应着图中的一行数据,用 index 属性和 columns 参数可以指定行列索引。
2、Series 对象只有行索引,没有列索引,不指定索引时,默认索引都是 0、1、2、3 …
例:
s1=pd.Series([166,167,168])
s2=pd.Series([166,167,168],
index=[“小张”,“小王”,“小李"]
)
s1 s2
df1=pd.DataFrame([ [166,56], [167,57], [168,58] ])
df2=pd.DataFrame([ [166,56], [167,57], [168,58]],
index=["s1","s2","s3"],columns=["身高","体重"]
)
df1 df2
2、把字典转换为对象
要点:
1、Series 对象中,键代表行索引,键值代表行数据
2、DataFrame 对象中,键代表列索引,键值代表一列数据。
例:
s3=pd.Series(“s1”:166,“s2”:167,“s3":168)
df3=pd.DataFrame({"身高":[166,167,168],"体重":[56,57,58]},
index=["s1","s2","s3"]
)
s3 df3
下载后可阅读完整内容,剩余3页未读,立即下载
787 浏览量
1623 浏览量
272 浏览量
213 浏览量
129 浏览量
152 浏览量
2020-06-23 上传
1979 浏览量
632 浏览量

qq_15378927
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- SocketCode.7z
- Xiaomi-MACE-Notes
- dbxincluder:带有XInclude 1.1的DocBook的内含物
- 电信设备-基于手机短信实现远程开门的系统及方法.zip
- OMDB:打开电影数据库
- jessie-ffmpeg:jessie-ffmpeg-使用ffmpeg和imageMagik创建Docker映像
- 模拟退火算法解决tsp问题.rar
- 年度业绩、能力盘点清单(总经理)
- Stripe-crx插件
- BiologyCalculator:IT-планета2021年的Командныйпроект,написанныйдляучастия
- WEB1:taller1
- eloquent-ci:口才的ORM在CodeIgniter中的实现
- parcel-boilerplate:包裹2样板
- 商场营业员工作总结范文
- Panda-Dev-Website
- dynamic_widget:一个后端驱动的UI工具包,使用json构建动态UI,而json格式与flutter小部件代码非常相似
